 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthGuard: An Open Platform for Detecting AI-Generated Multimedia with Multimodal LLMs
Nov 16, 2025
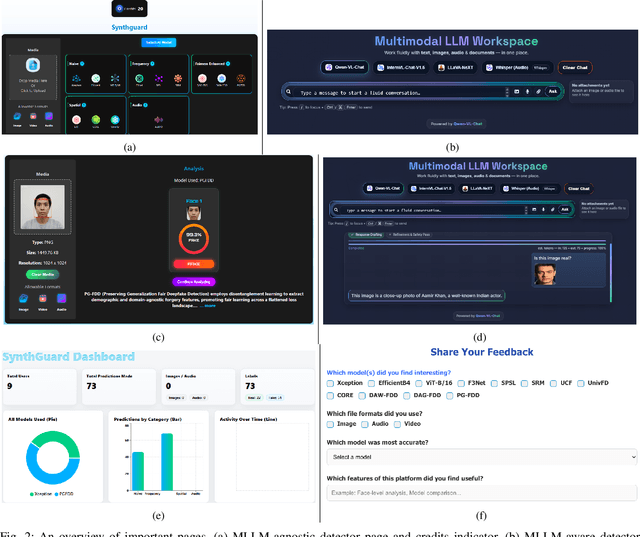
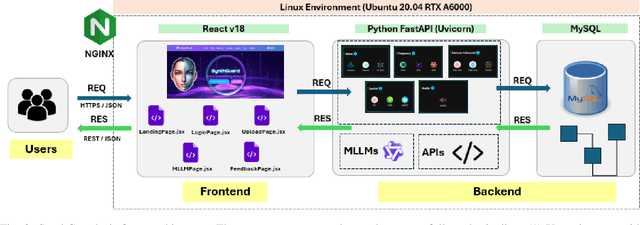
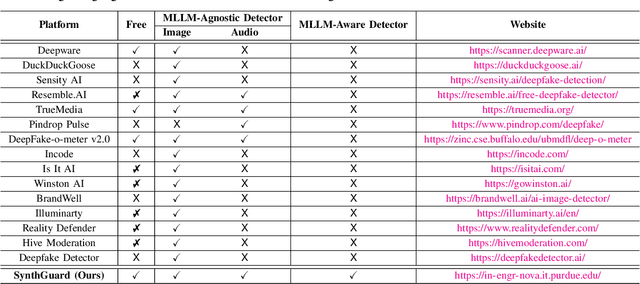
Artificial Intelligence (AI) has made it possible for anyone to create images, audio, and video with unprecedented ease, enriching education, communication, and creative expression. At the same time, the rapid rise of AI-generated media has introduced serious risks, including misinformation, identity misuse, and the erosion of public trust as synthetic content becomes increasingly indistinguishable from real media. Although deepfake detection has advanced, many existing tools remain closed-source, limited in modality, or lacking transparency and educational value, making it difficult for users to understand how detection decisions are made. To address these gaps, we introduce SynthGuard, an open, user-friendly platform for detecting and analyzing AI-generated multimedia using both traditional detectors and multimodal large language models (MLLMs). SynthGuard provides explainable inference, unified image and audio support, and an interactive interface designed to make forensic analysis accessible to researchers, educators, and the public. The SynthGuard platform is available at: https://in-engr-nova.it.purdue.edu/
HyperD: Hybrid Periodicity Decoupling Framework for Traffic Forecasting
Nov 16, 2025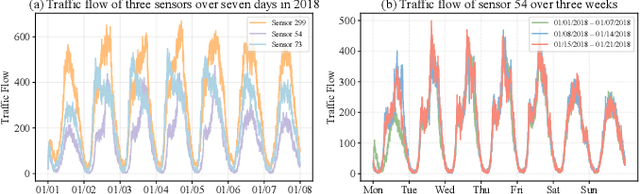
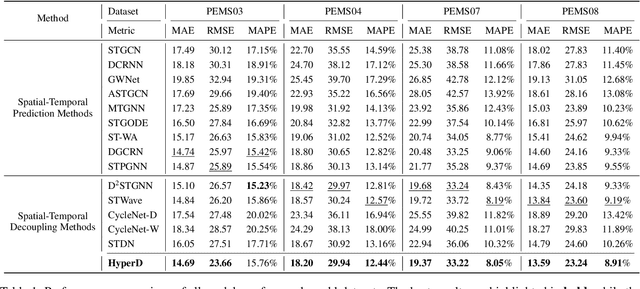
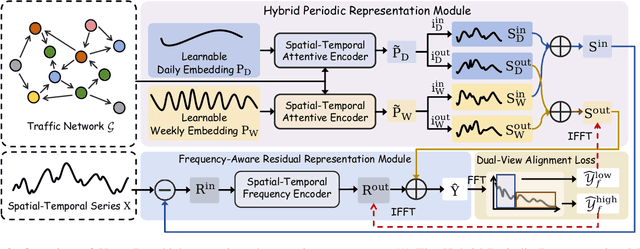
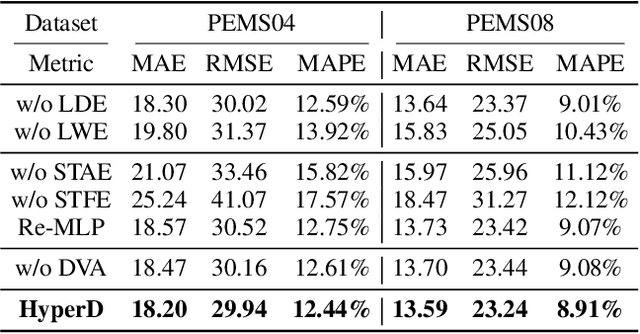
Accurate traffic forecasting plays a vital role in intelligent transportation systems, enabling applications such as congestion control, route planning, and urban mobility optimization. However, traffic forecasting remains challenging due to two key factors: (1) complex spatial dependencies arising from dynamic interactions between road segments and traffic sensors across the network, and (2) the coexistence of multi-scale periodic patterns (e.g., daily and weekly periodic patterns driven by human routines) with irregular fluctuations caused by unpredictable events (e.g., accidents, weather, or construction). To tackle these challenges, we propose HyperD (Hybrid Periodic Decoupling), a novel framework that decouples traffic data into periodic and residual components. The periodic component is handled by the Hybrid Periodic Representation Module, which extracts fine-grained daily and weekly patterns using learnable periodic embeddings and spatial-temporal attention. The residual component, which captures non-periodic, high-frequency fluctuations, is modeled by the Frequency-Aware Residual Representation Module, leveraging complex-valued MLP in frequency domain. To enforce semantic separation between the two components, we further introduce a Dual-View Alignment Loss, which aligns low-frequency information with the periodic branch and high-frequency information with the residual branch. Extensive experiments on four real-world traffic datasets demonstrate that HyperD achieves state-of-the-art prediction accuracy, while offering superior robustness under disturbances and improved computational efficiency compared to existing methods.
Evolve the Method, Not the Prompts: Evolutionary Synthesis of Jailbreak Attacks on LLMs
Nov 16, 2025Automated red teaming frameworks for Large Language Models (LLMs) have become increasingly sophisticated, yet they share a fundamental limitation: their jailbreak logic is confined to selecting, combining, or refining pre-existing attack strategies. This binds their creativity and leaves them unable to autonomously invent entirely new attack mechanisms. To overcome this gap, we introduce \textbf{EvoSynth}, an autonomous framework that shifts the paradigm from attack planning to the evolutionary synthesis of jailbreak methods. Instead of refining prompts, EvoSynth employs a multi-agent system to autonomously engineer, evolve, and execute novel, code-based attack algorithms. Crucially, it features a code-level self-correction loop, allowing it to iteratively rewrite its own attack logic in response to failure. Through extensive experiments, we demonstrate that EvoSynth not only establishes a new state-of-the-art by achieving an 85.5\% Attack Success Rate (ASR) against highly robust models like Claude-Sonnet-4.5, but also generates attacks that are significantly more diverse than those from existing methods. We release our framework to facilitate future research in this new direction of evolutionary synthesis of jailbreak methods. Code is available at: https://github.com/dongdongunique/EvoSynth.
MPCGNet: A Multiscale Feature Extraction and Progressive Feature Aggregation Network Using Coupling Gates for Polyp Segmentation
Nov 14, 2025Automatic segmentation methods of polyps is crucial for assisting doctors in colorectal polyp screening and cancer diagnosis. Despite the progress made by existing methods, polyp segmentation faces several challenges: (1) small-sized polyps are prone to being missed during identification, (2) the boundaries between polyps and the surrounding environment are often ambiguous, (3) noise in colonoscopy images, caused by uneven lighting and other factors, affects segmentation results. To address these challenges, this paper introduces coupling gates as components in specific modules to filter noise and perform feature importance selection. Three modules are proposed: the coupling gates multiscale feature extraction (CGMFE) module, which effectively extracts local features and suppresses noise; the windows cross attention (WCAD) decoder module, which restores details after capturing the precise location of polyps; and the decoder feature aggregation (DFA) module, which progressively aggregates features, further extracts them, and performs feature importance selection to reduce the loss of small-sized polyps. Experimental results demonstrate that MPCGNet outperforms recent networks, with mDice scores 2.20% and 0.68% higher than the second-best network on the ETIS-LaribPolypDB and CVC-ColonDB datasets, respectively.
SMART: A Surrogate Model for Predicting Application Runtime in Dragonfly Systems
Nov 14, 2025The Dragonfly network, with its high-radix and low-diameter structure, is a leading interconnect in high-performance computing. A major challenge is workload interference on shared network links. Parallel discrete event simulation (PDES) is commonly used to analyze workload interference. However, high-fidelity PDES is computationally expensive, making it impractical for large-scale or real-time scenarios. Hybrid simulation that incorporates data-driven surrogate models offers a promising alternative, especially for forecasting application runtime, a task complicated by the dynamic behavior of network traffic. We present \ourmodel, a surrogate model that combines graph neural networks (GNNs) and large language models (LLMs) to capture both spatial and temporal patterns from port level router data. \ourmodel outperforms existing statistical and machine learning baselines, enabling accurate runtime prediction and supporting efficient hybrid simulation of Dragonfly networks.
FedeCouple: Fine-Grained Balancing of Global-Generalization and Local-Adaptability in Federated Learning
Nov 12, 2025



In privacy-preserving mobile network transmission scenarios with heterogeneous client data, personalized federated learning methods that decouple feature extractors and classifiers have demonstrated notable advantages in enhancing learning capability. However, many existing approaches primarily focus on feature space consistency and classification personalization during local training, often neglecting the local adaptability of the extractor and the global generalization of the classifier. This oversight results in insufficient coordination and weak coupling between the components, ultimately degrading the overall model performance. To address this challenge, we propose FedeCouple, a federated learning method that balances global generalization and local adaptability at a fine-grained level. Our approach jointly learns global and local feature representations while employing dynamic knowledge distillation to enhance the generalization of personalized classifiers. We further introduce anchors to refine the feature space; their strict locality and non-transmission inherently preserve privacy and reduce communication overhead. Furthermore, we provide a theoretical analysis proving that FedeCouple converges for nonconvex objectives, with iterates approaching a stationary point as the number of communication rounds increases. Extensive experiments conducted on five image-classification datasets demonstrate that FedeCouple consistently outperforms nine baseline methods in effectiveness, stability, scalability, and security. Notably, in experiments evaluating effectiveness, FedeCouple surpasses the best baseline by a significant margin of 4.3%.
The Impact of Longitudinal Mammogram Alignment on Breast Cancer Risk Assessment
Nov 11, 2025Regular mammography screening is crucial for early breast cancer detection. By leveraging deep learning-based risk models, screening intervals can be personalized, especially for high-risk individuals. While recent methods increasingly incorporate longitudinal information from prior mammograms, accurate spatial alignment across time points remains a key challenge. Misalignment can obscure meaningful tissue changes and degrade model performance. In this study, we provide insights into various alignment strategies, image-based registration, feature-level (representation space) alignment with and without regularization, and implicit alignment methods, for their effectiveness in longitudinal deep learning-based risk modeling. Using two large-scale mammography datasets, we assess each method across key metrics, including predictive accuracy, precision, recall, and deformation field quality. Our results show that image-based registration consistently outperforms the more recently favored feature-based and implicit approaches across all metrics, enabling more accurate, temporally consistent predictions and generating smooth, anatomically plausible deformation fields. Although regularizing the deformation field improves deformation quality, it reduces the risk prediction performance of feature-level alignment. Applying image-based deformation fields within the feature space yields the best risk prediction performance. These findings underscore the importance of image-based deformation fields for spatial alignment in longitudinal risk modeling, offering improved prediction accuracy and robustness. This approach has strong potential to enhance personalized screening and enable earlier interventions for high-risk individuals. The code is available at https://github.com/sot176/Mammogram_Alignment_Study_Risk_Prediction.git, allowing full reproducibility of the results.
Dual Mamba for Node-Specific Representation Learning: Tackling Over-Smoothing with Selective State Space Modeling
Nov 11, 2025Over-smoothing remains a fundamental challenge in deep Graph Neural Networks (GNNs), where repeated message passing causes node representations to become indistinguishable. While existing solutions, such as residual connections and skip layers, alleviate this issue to some extent, they fail to explicitly model how node representations evolve in a node-specific and progressive manner across layers. Moreover, these methods do not take global information into account, which is also crucial for mitigating the over-smoothing problem. To address the aforementioned issues, in this work, we propose a Dual Mamba-enhanced Graph Convolutional Network (DMbaGCN), which is a novel framework that integrates Mamba into GNNs to address over-smoothing from both local and global perspectives. DMbaGCN consists of two modules: the Local State-Evolution Mamba (LSEMba) for local neighborhood aggregation and utilizing Mamba's selective state space modeling to capture node-specific representation dynamics across layers, and the Global Context-Aware Mamba (GCAMba) that leverages Mamba's global attention capabilities to incorporate global context for each node. By combining these components, DMbaGCN enhances node discriminability in deep GNNs, thereby mitigating over-smoothing. Extensive experiments on multiple benchmarks demonstrate the effectiveness and efficiency of our method.
Learning Performance Optimization for Edge AI System with Time and Energy Constraints
Nov 10, 2025Edge AI, which brings artificial intelligence to the edge of the network for real-time processing and decision-making, has emerged as a transformative technology across various applications. However, the deployment of Edge AI systems faces significant challenges due to high energy consumption and extended operation time. In this paper, we consider an Edge AI system which integrates the data acquisition, computation and communication processes, and focus on improving learning performance of this system. We model the time and energy consumption of different processes and perform a rigorous convergence analysis to quantify the impact of key system parameters, such as the amount of collected data and the number of training rounds, on the learning performance. Based on this analysis, we formulate a system-wide optimization problem that seeks to maximize learning performance under given time and energy constraints. We explore both homogeneous and heterogeneous device scenarios, developing low-complexity algorithms based on one-dimensional search and alternating optimization to jointly optimize data collection time and training rounds. Simulation results validate the accuracy of our convergence analysis and demonstrate the effectiveness of the proposed algorithms, providing valuable insights into designing energy-efficient Edge AI systems under real-world conditions.
Trajectory Design for UAV-Assisted Logistics Collection in Low-Altitude Economy
Nov 10, 2025Low-altitude economy (LAE) is rapidly emerging as a key driver of innovation, encompassing economic activities taking place in airspace below 500 meters. Unmanned aerial vehicles (UAVs) provide valuable tools for logistics collection within LAE systems, offering the ability to navigate through complex environments, avoid obstacles, and improve operational efficiency. However, logistics collection tasks involve UAVs flying through complex three-dimensional (3D) environments while avoiding obstacles, where traditional UAV trajectory design methods,typically developed under free-space conditions without explicitly accounting for obstacles, are not applicable. This paper presents, we propose a novel algorithm that combines the Lin-Kernighan-Helsgaun (LKH) and Deep Deterministic Policy Gradient (DDPG) methods to minimize the total collection time. Specifically, the LKH algorithm determines the optimal order of item collection, while the DDPG algorithm designs the flight trajectory between collection points. Simulations demonstrate that the proposed LKH-DDPG algorithm significantly reduces collection time by approximately 49 percent compared to baseline approaches, thereby highlighting its effectiveness in optimizing UAV trajectories and enhancing operational efficiency for logistics collection tasks in the LAE paradigm.