 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergyLens: Interpretable Closed-Form Energy Models for Multimodal LLM Inference Serving
May 11, 2026As large language models span dense, mixture-of-experts, and state-space architectures and are deployed on heterogeneous accelerators under increasingly diverse multimodal workloads, optimising inference energy has become as critical as optimizing latency and throughput. Existing approaches either treat latency as an energy proxy or rely on data-hungry black-box surrogates. Both fail under varying parallelism strategies: latency and energy optima diverge in over 20% of configurations we tested, and black-box surrogates require hundreds of profiling samples to generalize across model families and hardware. We present EnergyLens, which uses symbolic regression as a structure-discovery tool over profiling data to derive a single twelve-parameter closed-form energy model expressed in terms of system properties such as degree of parallelism, batch size, and sequence length. Unlike black-box surrogates, EnergyLens decouples tensor and pipeline parallelism contributions and separates prefill from decode energy, making its predictions physically interpretable and actionable. Fitted from as few as 50 profiling measurements, EnergyLens achieves 88.2% Top-1 configuration selection accuracy across many evaluation scenarios compared to 60.9% for the closest prior analytical baseline, matches the predictive accuracy of ensemble ML methods with 10x fewer profiling samples, and extrapolates reliably to unseen batch sizes and hardware platforms without structural modification, making it a practical, interpretable tool for energy-optimal LLM deployment.
SMART: A Surrogate Model for Predicting Application Runtime in Dragonfly Systems
Nov 14, 2025The Dragonfly network, with its high-radix and low-diameter structure, is a leading interconnect in high-performance computing. A major challenge is workload interference on shared network links. Parallel discrete event simulation (PDES) is commonly used to analyze workload interference. However, high-fidelity PDES is computationally expensive, making it impractical for large-scale or real-time scenarios. Hybrid simulation that incorporates data-driven surrogate models offers a promising alternative, especially for forecasting application runtime, a task complicated by the dynamic behavior of network traffic. We present \ourmodel, a surrogate model that combines graph neural networks (GNNs) and large language models (LLMs) to capture both spatial and temporal patterns from port level router data. \ourmodel outperforms existing statistical and machine learning baselines, enabling accurate runtime prediction and supporting efficient hybrid simulation of Dragonfly networks.
Leveraging LLMs to Automate Energy-Aware Refactoring of Parallel Scientific Codes
May 04, 2025While large language models (LLMs) are increasingly used for generating parallel scientific code, most current efforts emphasize functional correctness, often overlooking performance and energy considerations. In this work, we propose LASSI-EE, an automated LLM-based refactoring framework that generates energy-efficient parallel code on a target parallel system for a given parallel code as input. Through a multi-stage, iterative pipeline process, LASSI-EE achieved an average energy reduction of 47% across 85% of the 20 HeCBench benchmarks tested on NVIDIA A100 GPUs. Our findings demonstrate the broader potential of LLMs, not only for generating correct code but also for enabling energy-aware programming. We also address key insights and limitations within the framework, offering valuable guidance for future improvements.
LASSI: An LLM-based Automated Self-Correcting Pipeline for Translating Parallel Scientific Codes
Jun 30, 2024



This paper addresses the problem of providing a novel approach to sourcing significant training data for LLMs focused on science and engineering. In particular, a crucial challenge is sourcing parallel scientific codes in the ranges of millions to billions of codes. To tackle this problem, we propose an automated pipeline framework, called LASSI, designed to translate between parallel programming languages by bootstrapping existing closed- or open-source LLMs. LASSI incorporates autonomous enhancement through self-correcting loops where errors encountered during compilation and execution of generated code are fed back to the LLM through guided prompting for debugging and refactoring. We highlight the bi-directional translation of existing GPU benchmarks between OpenMP target offload and CUDA to validate LASSI. The results of evaluating LASSI with different application codes across four LLMs demonstrate the effectiveness of LASSI for generating executable parallel codes, with 80% of OpenMP to CUDA translations and 85% of CUDA to OpenMP translations producing the expected output. We also observe approximately 78% of OpenMP to CUDA translations and 62% of CUDA to OpenMP translations execute within 10% of or at a faster runtime than the original benchmark code in the same language.
Integrating Mamba and Transformer for Long-Short Range Time Series Forecasting
Apr 23, 2024



Time series forecasting is an important problem and plays a key role in a variety of applications including weather forecasting, stock market, and scientific simulations. Although transformers have proven to be effective in capturing dependency, its quadratic complexity of attention mechanism prevents its further adoption in long-range time series forecasting, thus limiting them attend to short-range range. Recent progress on state space models (SSMs) have shown impressive performance on modeling long range dependency due to their subquadratic complexity. Mamba, as a representative SSM, enjoys linear time complexity and has achieved strong scalability on tasks that requires scaling to long sequences, such as language, audio, and genomics. In this paper, we propose to leverage a hybrid framework Mambaformer that internally combines Mamba for long-range dependency, and Transformer for short range dependency, for long-short range forecasting. To the best of our knowledge, this is the first paper to combine Mamba and Transformer architecture in time series data. We investigate possible hybrid architectures to combine Mamba layer and attention layer for long-short range time series forecasting. The comparative study shows that the Mambaformer family can outperform Mamba and Transformer in long-short range time series forecasting problem. The code is available at https://github.com/XiongxiaoXu/Mambaformerin-Time-Series.
Interpretable Modeling of Deep Reinforcement Learning Driven Scheduling
Mar 24, 2024In the field of high-performance computing (HPC), there has been recent exploration into the use of deep reinforcement learning for cluster scheduling (DRL scheduling), which has demonstrated promising outcomes. However, a significant challenge arises from the lack of interpretability in deep neural networks (DNN), rendering them as black-box models to system managers. This lack of model interpretability hinders the practical deployment of DRL scheduling. In this work, we present a framework called IRL (Interpretable Reinforcement Learning) to address the issue of interpretability of DRL scheduling. The core idea is to interpret DNN (i.e., the DRL policy) as a decision tree by utilizing imitation learning. Unlike DNN, decision tree models are non-parametric and easily comprehensible to humans. To extract an effective and efficient decision tree, IRL incorporates the Dataset Aggregation (DAgger) algorithm and introduces the notion of critical state to prune the derived decision tree. Through trace-based experiments, we demonstrate that IRL is capable of converting a black-box DNN policy into an interpretable rulebased decision tree while maintaining comparable scheduling performance. Additionally, IRL can contribute to the setting of rewards in DRL scheduling.
DRAS-CQSim: A Reinforcement Learning based Framework for HPC Cluster Scheduling
May 16, 2021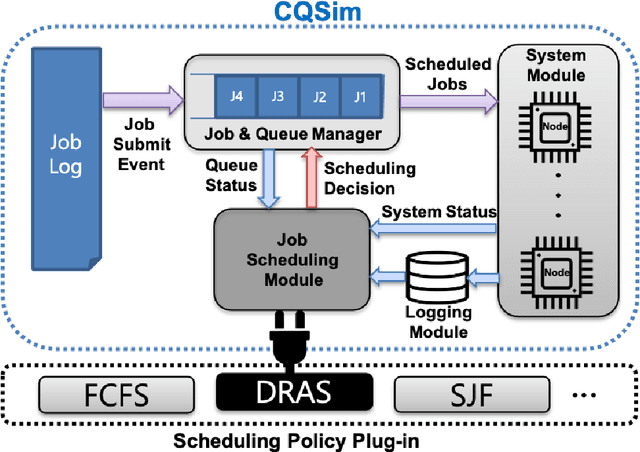

For decades, system administrators have been striving to design and tune cluster scheduling policies to improve the performance of high performance computing (HPC) systems. However, the increasingly complex HPC systems combined with highly diverse workloads make such manual process challenging, time-consuming, and error-prone. We present a reinforcement learning based HPC scheduling framework named DRAS-CQSim to automatically learn optimal scheduling policy. DRAS-CQSim encapsulates simulation environments, agents, hyperparameter tuning options, and different reinforcement learning algorithms, which allows the system administrators to quickly obtain customized scheduling policies.
Deep Reinforcement Agent for Scheduling in HPC
Feb 11, 2021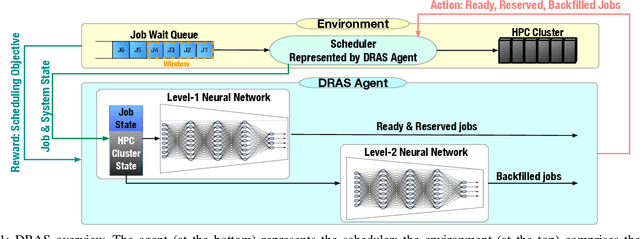
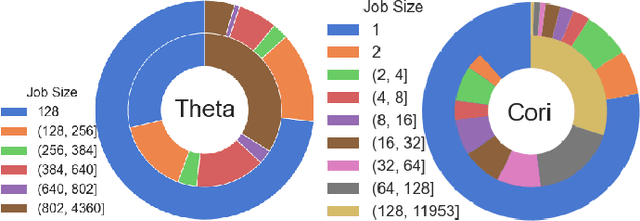
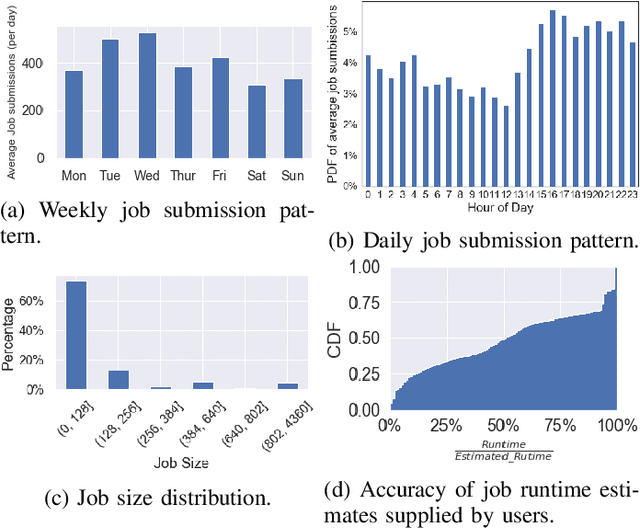
Cluster scheduler is crucial in high-performance computing (HPC). It determines when and which user jobs should be allocated to available system resources. Existing cluster scheduling heuristics are developed by human experts based on their experience with specific HPC systems and workloads. However, the increasing complexity of computing systems and the highly dynamic nature of application workloads have placed tremendous burden on manually designed and tuned scheduling heuristics. More aggressive optimization and automation are needed for cluster scheduling in HPC. In this work, we present an automated HPC scheduling agent named DRAS (Deep Reinforcement Agent for Scheduling) by leveraging deep reinforcement learning. DRAS is built on a novel, hierarchical neural network incorporating special HPC scheduling features such as resource reservation and backfilling. A unique training strategy is presented to enable DRAS to rapidly learn the target environment. Once being provided a specific scheduling objective given by system manager, DRAS automatically learns to improve its policy through interaction with the scheduling environment and dynamically adjusts its policy as workload changes. The experiments with different production workloads demonstrate that DRAS outperforms the existing heuristic and optimization approaches by up to 45%.
* Accepted by IPDPS 2021
Performance and Power Modeling and Prediction Using MuMMI and Ten Machine Learning Methods
Nov 12, 2020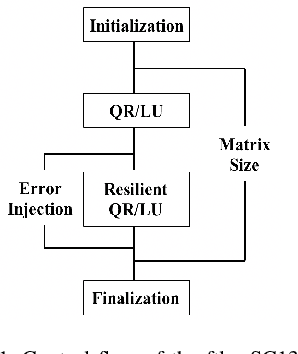
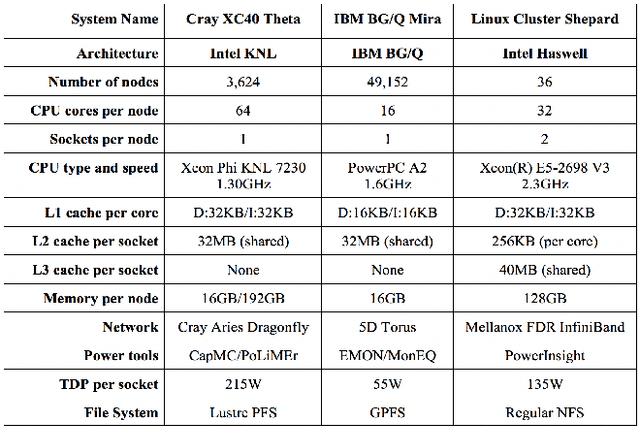
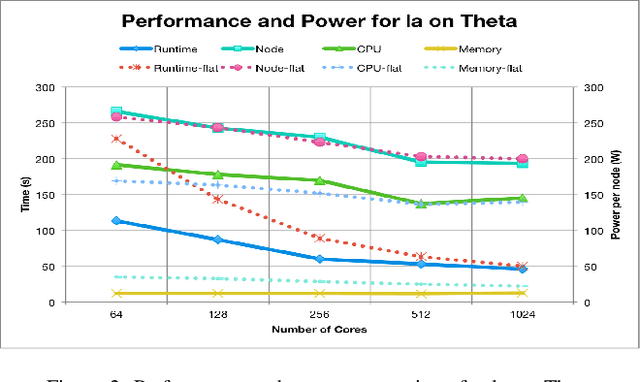
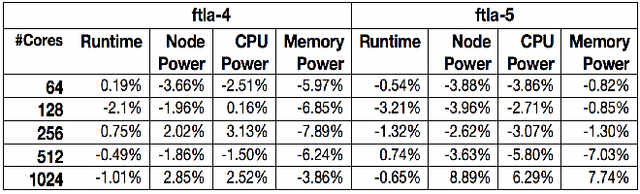
In this paper, we use modeling and prediction tool MuMMI (Multiple Metrics Modeling Infrastructure) and ten machine learning methods to model and predict performance and power and compare their prediction error rates. We use a fault-tolerant linear algebra code and a fault-tolerant heat distribution code to conduct our modeling and prediction study on the Cray XC40 Theta and IBM BG/Q Mira at Argonne National Laboratory and the Intel Haswell cluster Shepard at Sandia National Laboratories. Our experiment results show that the prediction error rates in performance and power using MuMMI are less than 10% for most cases. Based on the models for runtime, node power, CPU power, and memory power, we identify the most significant performance counters for potential optimization efforts associated with the application characteristics and the target architectures, and we predict theoretical outcomes of the potential optimizations. When we compare the prediction accuracy using MuMMI with that using 10 machine learning methods, we observe that MuMMI not only results in more accurate prediction in both performance and power but also presents how performance counters impact the performance and power models. This provides some insights about how to fine-tune the applications and/or systems for energy efficiency.