 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelfAug: Mitigating Catastrophic Forgetting in Retrieval-Augmented Generation via Distribution Self-Alignment
Sep 04, 2025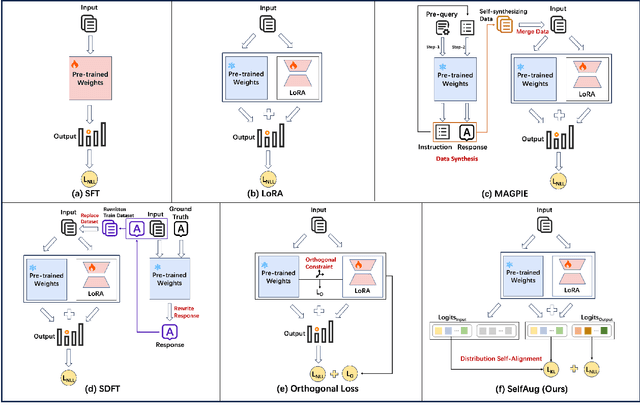
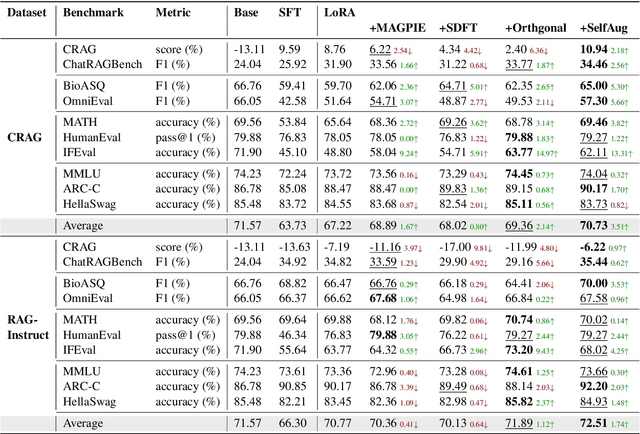
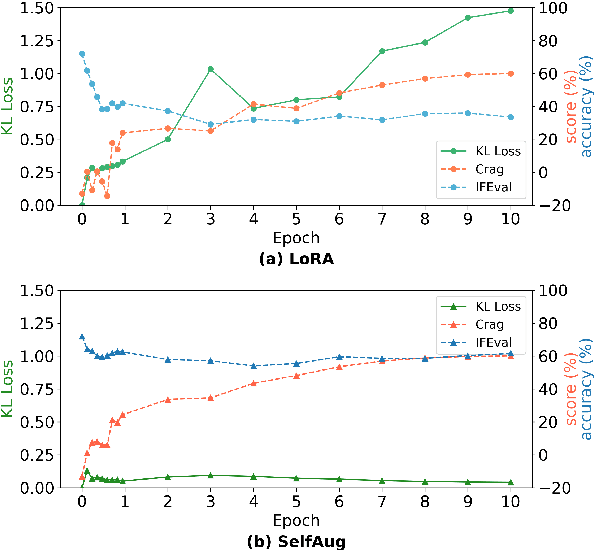
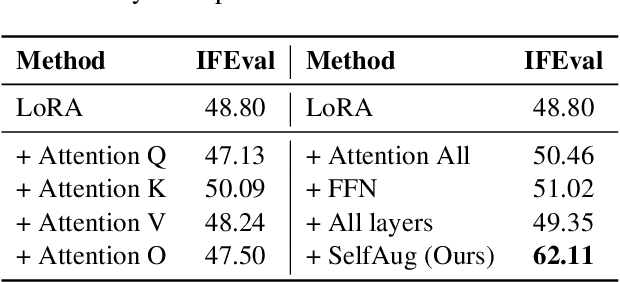
Recent advancements in large language models (LLMs) have revolutionized natural language processing through their remarkable capabilities in understanding and executing diverse tasks. While supervised fine-tuning, particularly in Retrieval-Augmented Generation (RAG) scenarios, effectively enhances task-specific performance, it often leads to catastrophic forgetting, where models lose their previously acquired knowledge and general capabilities. Existing solutions either require access to general instruction data or face limitations in preserving the model's original distribution. To overcome these limitations, we propose SelfAug, a self-distribution alignment method that aligns input sequence logits to preserve the model's semantic distribution, thereby mitigating catastrophic forgetting and improving downstream performance. Extensive experiments demonstrate that SelfAug achieves a superior balance between downstream learning and general capability retention. Our comprehensive empirical analysis reveals a direct correlation between distribution shifts and the severity of catastrophic forgetting in RAG scenarios, highlighting how the absence of RAG capabilities in general instruction tuning leads to significant distribution shifts during fine-tuning. Our findings not only advance the understanding of catastrophic forgetting in RAG contexts but also provide a practical solution applicable across diverse fine-tuning scenarios. Our code is publicly available at https://github.com/USTC-StarTeam/SelfAug.
PromptEnhancer: A Simple Approach to Enhance Text-to-Image Models via Chain-of-Thought Prompt Rewriting
Sep 04, 2025Recent advancements in text-to-image (T2I) diffusion models have demonstrated remarkable capabilities in generating high-fidelity images. However, these models often struggle to faithfully render complex user prompts, particularly in aspects like attribute binding, negation, and compositional relationships. This leads to a significant mismatch between user intent and the generated output. To address this challenge, we introduce PromptEnhancer, a novel and universal prompt rewriting framework that enhances any pretrained T2I model without requiring modifications to its weights. Unlike prior methods that rely on model-specific fine-tuning or implicit reward signals like image-reward scores, our framework decouples the rewriter from the generator. We achieve this by training a Chain-of-Thought (CoT) rewriter through reinforcement learning, guided by a dedicated reward model we term the AlignEvaluator. The AlignEvaluator is trained to provide explicit and fine-grained feedback based on a systematic taxonomy of 24 key points, which are derived from a comprehensive analysis of common T2I failure modes. By optimizing the CoT rewriter to maximize the reward from our AlignEvaluator, our framework learns to generate prompts that are more precisely interpreted by T2I models. Extensive experiments on the HunyuanImage 2.1 model demonstrate that PromptEnhancer significantly improves image-text alignment across a wide range of semantic and compositional challenges. Furthermore, we introduce a new, high-quality human preference benchmark to facilitate future research in this direction.
Building Self-Evolving Agents via Experience-Driven Lifelong Learning: A Framework and Benchmark
Aug 26, 2025As AI advances toward general intelligence, the focus is shifting from systems optimized for static tasks to creating open-ended agents that learn continuously. In this paper, we introduce Experience-driven Lifelong Learning (ELL), a framework for building self-evolving agents capable of continuous growth through real-world interaction. The framework is built on four core principles: (1) Experience Exploration: Agents learn through continuous, self-motivated interaction with dynamic environments, navigating interdependent tasks and generating rich experiential trajectories. (2) Long-term Memory: Agents preserve and structure historical knowledge, including personal experiences, domain expertise, and commonsense reasoning, into a persistent memory system. (3) Skill Learning: Agents autonomously improve by abstracting recurring patterns from experience into reusable skills, which are actively refined and validated for application in new tasks. (4) Knowledge Internalization: Agents internalize explicit and discrete experiences into implicit and intuitive capabilities as "second nature". We also introduce StuLife, a benchmark dataset for ELL that simulates a student's holistic college journey, from enrollment to academic and personal development, across three core phases and ten detailed sub-scenarios. StuLife is designed around three key paradigm shifts: From Passive to Proactive, From Context to Memory, and From Imitation to Learning. In this dynamic environment, agents must acquire and distill practical skills and maintain persistent memory to make decisions based on evolving state variables. StuLife provides a comprehensive platform for evaluating lifelong learning capabilities, including memory retention, skill transfer, and self-motivated behavior. Beyond evaluating SOTA LLMs on the StuLife benchmark, we also explore the role of context engineering in advancing AGI.
GitTaskBench: A Benchmark for Code Agents Solving Real-World Tasks Through Code Repository Leveraging
Aug 26, 2025



Beyond scratch coding, exploiting large-scale code repositories (e.g., GitHub) for practical tasks is vital in real-world software development, yet current benchmarks rarely evaluate code agents in such authentic, workflow-driven scenarios. To bridge this gap, we introduce GitTaskBench, a benchmark designed to systematically assess this capability via 54 realistic tasks across 7 modalities and 7 domains. Each task pairs a relevant repository with an automated, human-curated evaluation harness specifying practical success criteria. Beyond measuring execution and task success, we also propose the alpha-value metric to quantify the economic benefit of agent performance, which integrates task success rates, token cost, and average developer salaries. Experiments across three state-of-the-art agent frameworks with multiple advanced LLMs show that leveraging code repositories for complex task solving remains challenging: even the best-performing system, OpenHands+Claude 3.7, solves only 48.15% of tasks. Error analysis attributes over half of failures to seemingly mundane yet critical steps like environment setup and dependency resolution, highlighting the need for more robust workflow management and increased timeout preparedness. By releasing GitTaskBench, we aim to drive progress and attention toward repository-aware code reasoning, execution, and deployment -- moving agents closer to solving complex, end-to-end real-world tasks. The benchmark and code are open-sourced at https://github.com/QuantaAlpha/GitTaskBench.
CMPhysBench: A Benchmark for Evaluating Large Language Models in Condensed Matter Physics
Aug 25, 2025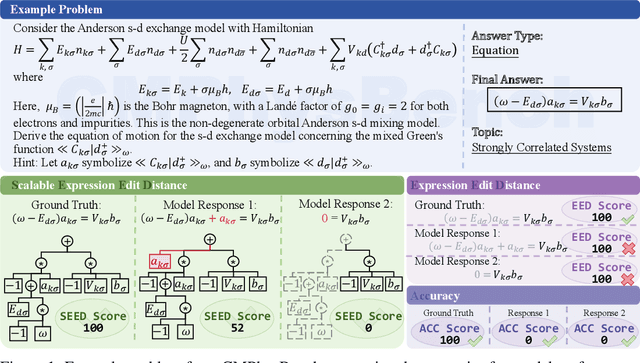
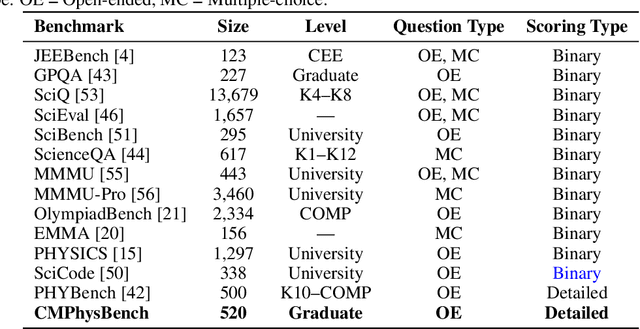
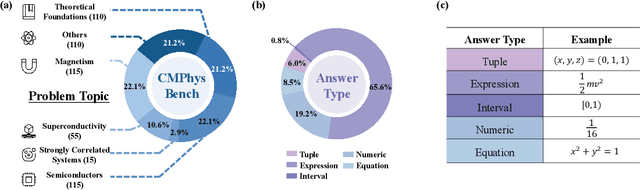

We introduce CMPhysBench, designed to assess the proficiency of Large Language Models (LLMs) in Condensed Matter Physics, as a novel Benchmark. CMPhysBench is composed of more than 520 graduate-level meticulously curated questions covering both representative subfields and foundational theoretical frameworks of condensed matter physics, such as magnetism, superconductivity, strongly correlated systems, etc. To ensure a deep understanding of the problem-solving process,we focus exclusively on calculation problems, requiring LLMs to independently generate comprehensive solutions. Meanwhile, leveraging tree-based representations of expressions, we introduce the Scalable Expression Edit Distance (SEED) score, which provides fine-grained (non-binary) partial credit and yields a more accurate assessment of similarity between prediction and ground-truth. Our results show that even the best models, Grok-4, reach only 36 average SEED score and 28% accuracy on CMPhysBench, underscoring a significant capability gap, especially for this practical and frontier domain relative to traditional physics. The code anddataset are publicly available at https://github.com/CMPhysBench/CMPhysBench.
Comp-X: On Defining an Interactive Learned Image Compression Paradigm With Expert-driven LLM Agent
Aug 21, 2025We present Comp-X, the first intelligently interactive image compression paradigm empowered by the impressive reasoning capability of large language model (LLM) agent. Notably, commonly used image codecs usually suffer from limited coding modes and rely on manual mode selection by engineers, making them unfriendly for unprofessional users. To overcome this, we advance the evolution of image coding paradigm by introducing three key innovations: (i) multi-functional coding framework, which unifies different coding modes of various objective/requirements, including human-machine perception, variable coding, and spatial bit allocation, into one framework. (ii) interactive coding agent, where we propose an augmented in-context learning method with coding expert feedback to teach the LLM agent how to understand the coding request, mode selection, and the use of the coding tools. (iii) IIC-bench, the first dedicated benchmark comprising diverse user requests and the corresponding annotations from coding experts, which is systematically designed for intelligently interactive image compression evaluation. Extensive experimental results demonstrate that our proposed Comp-X can understand the coding requests efficiently and achieve impressive textual interaction capability. Meanwhile, it can maintain comparable compression performance even with a single coding framework, providing a promising avenue for artificial general intelligence (AGI) in image compression.
Power Stabilization for AI Training Datacenters
Aug 21, 2025Large Artificial Intelligence (AI) training workloads spanning several tens of thousands of GPUs present unique power management challenges. These arise due to the high variability in power consumption during the training. Given the synchronous nature of these jobs, during every iteration there is a computation-heavy phase, where each GPU works on the local data, and a communication-heavy phase where all the GPUs synchronize on the data. Because compute-heavy phases require much more power than communication phases, large power swings occur. The amplitude of these power swings is ever increasing with the increase in the size of training jobs. An even bigger challenge arises from the frequency spectrum of these power swings which, if harmonized with critical frequencies of utilities, can cause physical damage to the power grid infrastructure. Therefore, to continue scaling AI training workloads safely, we need to stabilize the power of such workloads. This paper introduces the challenge with production data and explores innovative solutions across the stack: software, GPU hardware, and datacenter infrastructure. We present the pros and cons of each of these approaches and finally present a multi-pronged approach to solving the challenge. The proposed solutions are rigorously tested using a combination of real hardware and Microsoft's in-house cloud power simulator, providing critical insights into the efficacy of these interventions under real-world conditions.
Robust and Efficient Quantum Reservoir Computing with Discrete Time Crystal
Aug 21, 2025The rapid development of machine learning and quantum computing has placed quantum machine learning at the forefront of research. However, existing quantum machine learning algorithms based on quantum variational algorithms face challenges in trainability and noise robustness. In order to address these challenges, we introduce a gradient-free, noise-robust quantum reservoir computing algorithm that harnesses discrete time crystal dynamics as a reservoir. We first calibrate the memory, nonlinear, and information scrambling capacities of the quantum reservoir, revealing their correlation with dynamical phases and non-equilibrium phase transitions. We then apply the algorithm to the binary classification task and establish a comparative quantum kernel advantage. For ten-class classification, both noisy simulations and experimental results on superconducting quantum processors match ideal simulations, demonstrating the enhanced accuracy with increasing system size and confirming the topological noise robustness. Our work presents the first experimental demonstration of quantum reservoir computing for image classification based on digital quantum simulation. It establishes the correlation between quantum many-body non-equilibrium phase transitions and quantum machine learning performance, providing new design principles for quantum reservoir computing and broader quantum machine learning algorithms in the NISQ era.
RynnEC: Bringing MLLMs into Embodied World
Aug 19, 2025We introduce RynnEC, a video multimodal large language model designed for embodied cognition. Built upon a general-purpose vision-language foundation model, RynnEC incorporates a region encoder and a mask decoder, enabling flexible region-level video interaction. Despite its compact architecture, RynnEC achieves state-of-the-art performance in object property understanding, object segmentation, and spatial reasoning. Conceptually, it offers a region-centric video paradigm for the brain of embodied agents, providing fine-grained perception of the physical world and enabling more precise interactions. To mitigate the scarcity of annotated 3D datasets, we propose an egocentric video based pipeline for generating embodied cognition data. Furthermore, we introduce RynnEC-Bench, a region-centered benchmark for evaluating embodied cognitive capabilities. We anticipate that RynnEC will advance the development of general-purpose cognitive cores for embodied agents and facilitate generalization across diverse embodied tasks. The code, model checkpoints, and benchmark are available at: https://github.com/alibaba-damo-academy/RynnEC
Towards Affordance-Aware Robotic Dexterous Grasping with Human-like Priors
Aug 12, 2025A dexterous hand capable of generalizable grasping objects is fundamental for the development of general-purpose embodied AI. However, previous methods focus narrowly on low-level grasp stability metrics, neglecting affordance-aware positioning and human-like poses which are crucial for downstream manipulation. To address these limitations, we propose AffordDex, a novel framework with two-stage training that learns a universal grasping policy with an inherent understanding of both motion priors and object affordances. In the first stage, a trajectory imitator is pre-trained on a large corpus of human hand motions to instill a strong prior for natural movement. In the second stage, a residual module is trained to adapt these general human-like motions to specific object instances. This refinement is critically guided by two components: our Negative Affordance-aware Segmentation (NAA) module, which identifies functionally inappropriate contact regions, and a privileged teacher-student distillation process that ensures the final vision-based policy is highly successful. Extensive experiments demonstrate that AffordDex not only achieves universal dexterous grasping but also remains remarkably human-like in posture and functionally appropriate in contact location. As a result, AffordDex significantly outperforms state-of-the-art baselines across seen objects, unseen instances, and even entirely novel categories.