 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCS: Clinical Consensus Selection for Radiology Report Generation
May 28, 2026Radiology report generation (RRG) is commonly formulated as a single-path generation task, where a multimodal large language model (MLLM) produces one decoded report as the final output. While recent progress has largely been driven by scaling training data, model capacity, and retrieval mechanisms, improving report quality at inference time remains underexplored. In this work, we observe that fixed radiology MLLMs often generate clinically stronger reports elsewhere in their candidate pool than the one selected by default decoding, suggesting that inference-time decision making remains an overlooked bottleneck. To address this, we propose Clinical Consensus Selection (CCS), a decoder-agnostic inference-time selection framework that samples multiple candidate reports and selects the one with the highest clinical consensus across the rollout pool. CCS unifies text-based utilities with a radiology-adapted utility computed by an image--report-trained multimodal embedder, which measures candidate agreement beyond surface-level textual similarity. Across three datasets and multiple radiology MLLMs, CCS consistently improves inference-time performance over single-path decoding and generic Best-of-N baselines, with particularly clear gains on clinical metrics. Further analysis shows that image-grounded utility forms a selection axis distinct from textual consensus and that substantial headroom remains for improving RRG at inference time.
A Large-Scale Dataset and Benchmark: Do Protein-Ligand Models Learn Binding Sites or Just Binding Likelihood?
May 21, 2026Protein-ligand modeling underpins computational drug discovery and molecular design. Existing protein-ligand benchmarks typically evaluate whether a protein and ligand interact and how strongly they bind, through tasks such as binary binding prediction and affinity regression. However, these evaluations provide limited evidence of whether models can localize binding sites or identify the non-covalent interactions underlying molecular recognition. To address this gap, we introduce InteractBind, a large-scale protein-ligand dataset comprising approximately 100k protein-ligand pairs, together with a benchmark for fine-grained evaluation. The core fine-grained task is that of binding-site localization, which uses protein-residue and ligand-atom interaction maps spanning six major types of non-covalent interactions to assess whether model-derived interaction maps localize binding sites. InteractBind further includes binding affinity and protein similarity-controlled splits to support realistic generalization assessment. Using InteractBind, we evaluate eight existing sequence-based and interaction-aware models, assessing binary binding prediction and binding-site localization. Results reveal limited binding-site localization despite strong binary binding prediction, with marked variation across non-covalent interaction types. Overall, InteractBind establishes a benchmark paradigm that encourages the development of more interpretable and physically grounded protein-ligand models.
EvoIdeator: Evolving Scientific Ideas through Checklist-Grounded Reinforcement Learning
Mar 23, 2026Scientific idea generation is a cornerstone of autonomous knowledge discovery, yet the iterative evolution required to transform initial concepts into high-quality research proposals remains a formidable challenge for Large Language Models (LLMs). Existing Reinforcement Learning (RL) paradigms often rely on rubric-based scalar rewards that provide global quality scores but lack actionable granularity. Conversely, language-based refinement methods are typically confined to inference-time prompting, targeting models that are not explicitly optimized to internalize such critiques. To bridge this gap, we propose \textbf{EvoIdeator}, a framework that facilitates the evolution of scientific ideas by aligning the RL training objective with \textbf{checklist-grounded feedback}. EvoIdeator leverages a structured judge model to generate two synergistic signals: (1) \emph{lexicographic rewards} for multi-dimensional optimization, and (2) \emph{fine-grained language feedback} that offers span-level critiques regarding grounding, feasibility, and methodological rigor. By integrating these signals into the RL loop, we condition the policy to systematically utilize precise feedback during both optimization and inference. Extensive experiments demonstrate that EvoIdeator, built on Qwen3-4B, significantly outperforms much larger frontier models across key scientific metrics. Crucially, the learned policy exhibits strong generalization to diverse external feedback sources without further fine-tuning, offering a scalable and rigorous path toward self-refining autonomous ideation.
EvoScientist: Towards Multi-Agent Evolving AI Scientists for End-to-End Scientific Discovery
Mar 09, 2026The increasing adoption of Large Language Models (LLMs) has enabled AI scientists to perform complex end-to-end scientific discovery tasks requiring coordination of specialized roles, including idea generation and experimental execution. However, most state-of-the-art AI scientist systems rely on static, hand-designed pipelines and fail to adapt based on accumulated interaction histories. As a result, these systems overlook promising research directions, repeat failed experiments, and pursue infeasible ideas. To address this, we introduce EvoScientist, an evolving multi-agent AI scientist framework that continuously improves research strategies through persistent memory and self-evolution. EvoScientist comprises three specialized agents: a Researcher Agent (RA) for scientific idea generation, an Engineer Agent (EA) for experiment implementation and execution, and an Evolution Manager Agent (EMA) that distills insights from prior interactions into reusable knowledge. EvoScientist contains two persistent memory modules: (i) an ideation memory, which summarizes feasible research directions from top-ranked ideas while recording previously unsuccessful directions; and (ii) an experimentation memory, which captures effective data processing and model training strategies derived from code search trajectories and best-performing implementations. These modules enable the RA and EA to retrieve relevant prior strategies, improving idea quality and code execution success rates over time. Experiments show that EvoScientist outperforms 7 open-source and commercial state-of-the-art systems in scientific idea generation, achieving higher novelty, feasibility, relevance, and clarity via automatic and human evaluation. EvoScientist also substantially improves code execution success rates through multi-agent evolution, demonstrating persistent memory's effectiveness for end-to-end scientific discovery.
Failure Modes in Multi-Hop QA: The Weakest Link Law and the Recognition Bottleneck
Jan 18, 2026Despite scaling to massive context windows, Large Language Models (LLMs) struggle with multi-hop reasoning due to inherent position bias, which causes them to overlook information at certain positions. Whether these failures stem from an inability to locate evidence (recognition failure) or integrate it (synthesis failure) is unclear. We introduce Multi-Focus Attention Instruction (MFAI), a semantic probe to disentangle these mechanisms by explicitly steering attention towards selected positions. Across 5 LLMs on two multi-hop QA tasks (MuSiQue and NeoQA), we establish the "Weakest Link Law": multi-hop reasoning performance collapses to the performance level of the least visible evidence. Crucially, this failure is governed by absolute position rather than the linear distance between facts (performance variance $<3%$). We further identify a duality in attention steering: while matched MFAI resolves recognition bottlenecks, improving accuracy by up to 11.5% in low-visibility positions, misleading MFAI triggers confusion in real-world tasks but is successfully filtered in synthetic tasks. Finally, we demonstrate that "thinking" models that utilize System-2 reasoning, effectively locate and integrate the required information, matching gold-only baselines even in noisy, long-context settings.
T-Retrievability: A Topic-Focused Approach to Measure Fair Document Exposure in Information Retrieval
Aug 29, 2025Retrievability of a document is a collection-based statistic that measures its expected (reciprocal) rank of being retrieved within a specific rank cut-off. A collection with uniformly distributed retrievability scores across documents is an indicator of fair document exposure. While retrievability scores have been used to quantify the fairness of exposure for a collection, in our work, we use the distribution of retrievability scores to measure the exposure bias of retrieval models. We hypothesise that an uneven distribution of retrievability scores across the entire collection may not accurately reflect exposure bias but rather indicate variations in topical relevance. As a solution, we propose a topic-focused localised retrievability measure, which we call \textit{T-Retrievability} (topic-retrievability), which first computes retrievability scores over multiple groups of topically-related documents, and then aggregates these localised values to obtain the collection-level statistics. Our analysis using this proposed T-Retrievability measure uncovers new insights into the exposure characteristics of various neural ranking models. The findings suggest that this localised measure provides a more nuanced understanding of exposure fairness, offering a more reliable approach for assessing document accessibility in IR systems.
A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems
Aug 10, 2025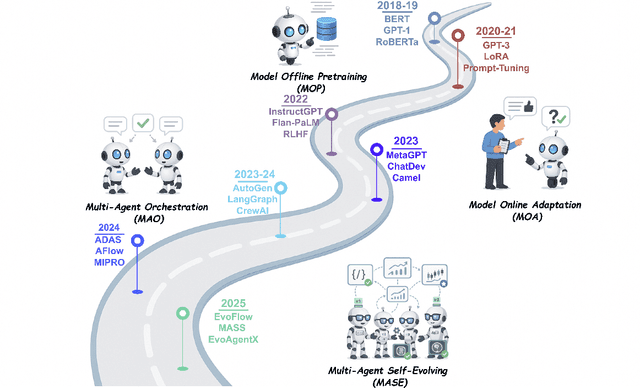
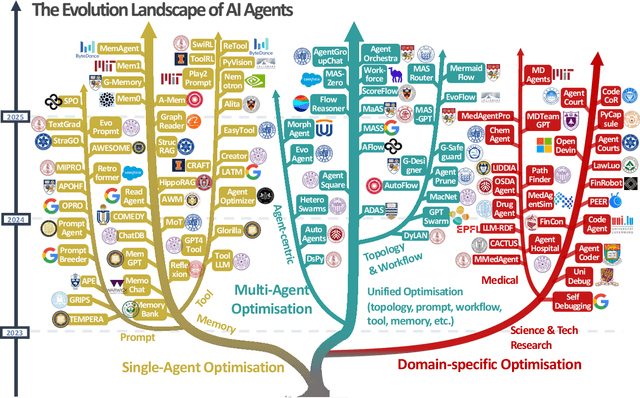
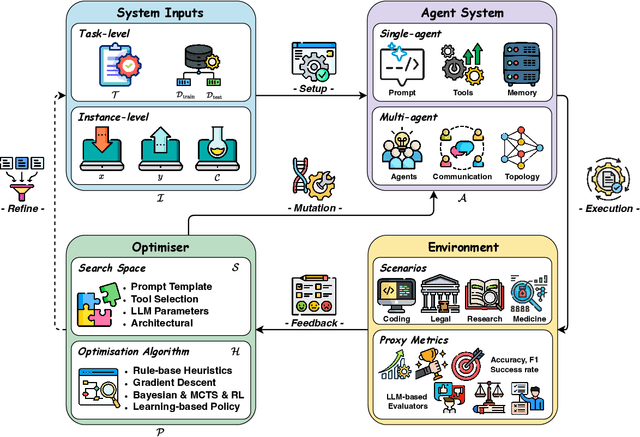
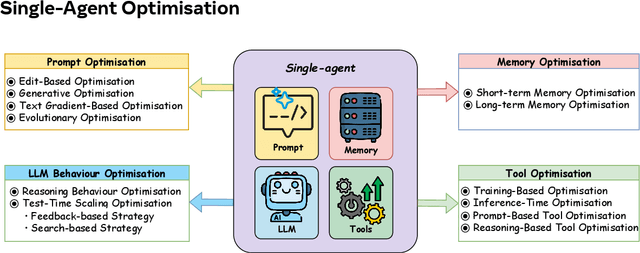
Recent advances in large language models have sparked growing interest in AI agents capable of solving complex, real-world tasks. However, most existing agent systems rely on manually crafted configurations that remain static after deployment, limiting their ability to adapt to dynamic and evolving environments. To this end, recent research has explored agent evolution techniques that aim to automatically enhance agent systems based on interaction data and environmental feedback. This emerging direction lays the foundation for self-evolving AI agents, which bridge the static capabilities of foundation models with the continuous adaptability required by lifelong agentic systems. In this survey, we provide a comprehensive review of existing techniques for self-evolving agentic systems. Specifically, we first introduce a unified conceptual framework that abstracts the feedback loop underlying the design of self-evolving agentic systems. The framework highlights four key components: System Inputs, Agent System, Environment, and Optimisers, serving as a foundation for understanding and comparing different strategies. Based on this framework, we systematically review a wide range of self-evolving techniques that target different components of the agent system. We also investigate domain-specific evolution strategies developed for specialised fields such as biomedicine, programming, and finance, where optimisation objectives are tightly coupled with domain constraints. In addition, we provide a dedicated discussion on the evaluation, safety, and ethical considerations for self-evolving agentic systems, which are critical to ensuring their effectiveness and reliability. This survey aims to provide researchers and practitioners with a systematic understanding of self-evolving AI agents, laying the foundation for the development of more adaptive, autonomous, and lifelong agentic systems.
Constructing and Evaluating Declarative RAG Pipelines in PyTerrier
Jun 12, 2025


Search engines often follow a pipeline architecture, where complex but effective reranking components are used to refine the results of an initial retrieval. Retrieval augmented generation (RAG) is an exciting application of the pipeline architecture, where the final component generates a coherent answer for the users from the retrieved documents. In this demo paper, we describe how such RAG pipelines can be formulated in the declarative PyTerrier architecture, and the advantages of doing so. Our PyTerrier-RAG extension for PyTerrier provides easy access to standard RAG datasets and evaluation measures, state-of-the-art LLM readers, and using PyTerrier's unique operator notation, easy-to-build pipelines. We demonstrate the succinctness of indexing and RAG pipelines on standard datasets (including Natural Questions) and how to build on the larger PyTerrier ecosystem with state-of-the-art sparse, learned-sparse, and dense retrievers, and other neural rankers.
SEW: Self-Evolving Agentic Workflows for Automated Code Generation
May 24, 2025Large Language Models (LLMs) have demonstrated effectiveness in code generation tasks. To enable LLMs to address more complex coding challenges, existing research has focused on crafting multi-agent systems with agentic workflows, where complex coding tasks are decomposed into sub-tasks, assigned to specialized agents. Despite their effectiveness, current approaches heavily rely on hand-crafted agentic workflows, with both agent topologies and prompts manually designed, which limits their ability to automatically adapt to different types of coding problems. To address these limitations and enable automated workflow design, we propose \textbf{S}elf-\textbf{E}volving \textbf{W}orkflow (\textbf{SEW}), a novel self-evolving framework that automatically generates and optimises multi-agent workflows. Extensive experiments on three coding benchmark datasets, including the challenging LiveCodeBench, demonstrate that our SEW can automatically design agentic workflows and optimise them through self-evolution, bringing up to 33\% improvement on LiveCodeBench compared to using the backbone LLM only. Furthermore, by investigating different representation schemes of workflow, we provide insights into the optimal way to encode workflow information with text.
Grounding Chest X-Ray Visual Question Answering with Generated Radiology Reports
May 22, 2025We present a novel approach to Chest X-ray (CXR) Visual Question Answering (VQA), addressing both single-image image-difference questions. Single-image questions focus on abnormalities within a specific CXR ("What abnormalities are seen in image X?"), while image-difference questions compare two longitudinal CXRs acquired at different time points ("What are the differences between image X and Y?"). We further explore how the integration of radiology reports can enhance the performance of VQA models. While previous approaches have demonstrated the utility of radiology reports during the pre-training phase, we extend this idea by showing that the reports can also be leveraged as additional input to improve the VQA model's predicted answers. First, we propose a unified method that handles both types of questions and auto-regressively generates the answers. For single-image questions, the model is provided with a single CXR. For image-difference questions, the model is provided with two CXRs from the same patient, captured at different time points, enabling the model to detect and describe temporal changes. Taking inspiration from 'Chain-of-Thought reasoning', we demonstrate that performance on the CXR VQA task can be improved by grounding the answer generator module with a radiology report predicted for the same CXR. In our approach, the VQA model is divided into two steps: i) Report Generation (RG) and ii) Answer Generation (AG). Our results demonstrate that incorporating predicted radiology reports as evidence to the AG model enhances performance on both single-image and image-difference questions, achieving state-of-the-art results on the Medical-Diff-VQA dataset.