 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster-Based Generalized Additive Models Informed by Random Fourier Features
Dec 22, 2025Explainable machine learning aims to strike a balance between prediction accuracy and model transparency, particularly in settings where black-box predictive models, such as deep neural networks or kernel-based methods, achieve strong empirical performance but remain difficult to interpret. This work introduces a mixture of generalized additive models (GAMs) in which random Fourier feature (RFF) representations are leveraged to uncover locally adaptive structure in the data. In the proposed method, an RFF-based embedding is first learned and then compressed via principal component analysis. The resulting low-dimensional representations are used to perform soft clustering of the data through a Gaussian mixture model. These cluster assignments are then applied to construct a mixture-of-GAMs framework, where each local GAM captures nonlinear effects through interpretable univariate smooth functions. Numerical experiments on real-world regression benchmarks, including the California Housing, NASA Airfoil Self-Noise, and Bike Sharing datasets, demonstrate improved predictive performance relative to classical interpretable models. Overall, this construction provides a principled approach for integrating representation learning with transparent statistical modeling.
Step-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
Acquiring Common Chinese Emotional Events Using Large Language Model
Nov 07, 2025Knowledge about emotional events is an important kind of knowledge which has been applied to improve the effectiveness of different applications. However, emotional events cannot be easily acquired, especially common or generalized emotional events that are context-independent. The goal of this paper is to obtain common emotional events in Chinese language such as "win a prize" and "be criticized". Our approach begins by collecting a comprehensive list of Chinese emotional event indicators. Then, we generate emotional events by prompting a Chinese large language model (LLM) using these indicators. To ensure the quality of these emotional events, we train a filter to discard invalid generated results. We also classify these emotional events as being positive events and negative events using different techniques. Finally, we harvest a total of 102,218 high-quality common emotional events with sentiment polarity labels, which is the only large-scale commonsense knowledge base of emotional events in Chinese language. Intrinsic evaluation results show that the proposed method in this paper can be effectively used to acquire common Chinese emotional events. An extrinsic use case also demonstrates the strong potential of common emotional events in the field of emotion cause extraction (ECE). Related resources including emotional event indicators and emotional events will be released after the publication of this paper.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
Remote Sensing Image Intelligent Interpretation with the Language-Centered Perspective: Principles, Methods and Challenges
Aug 09, 2025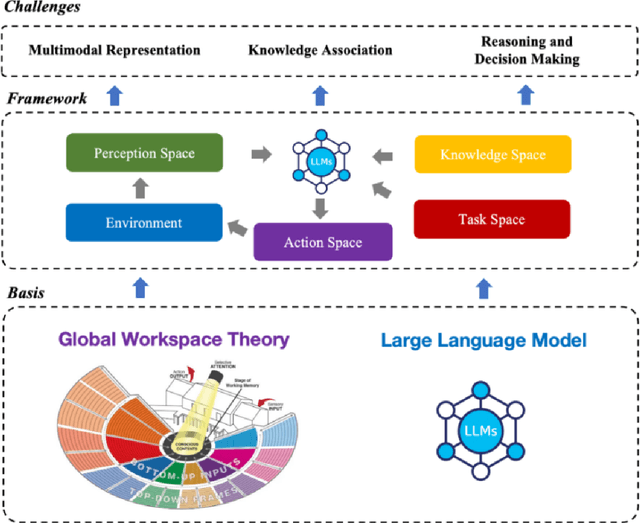
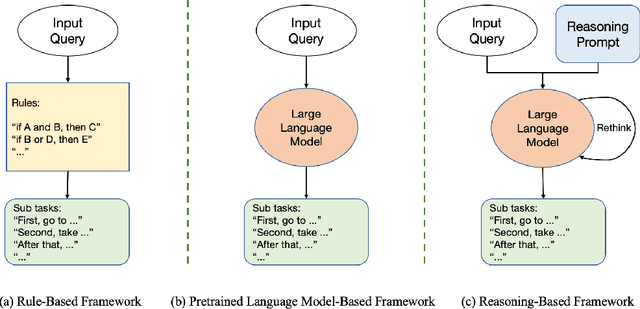
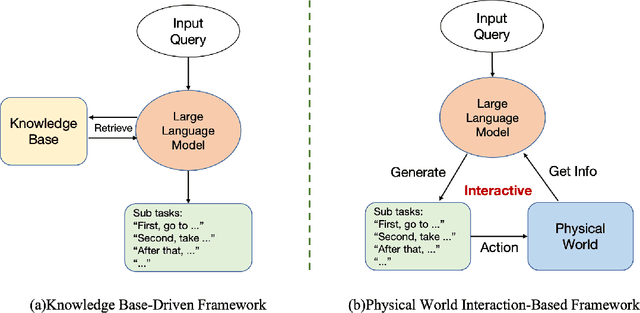
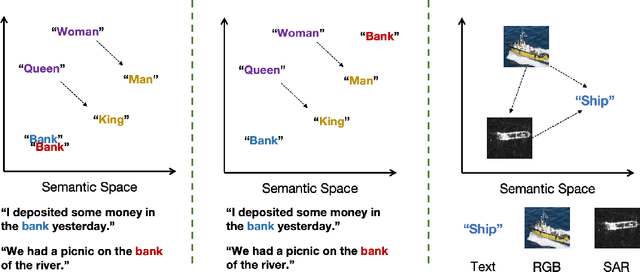
The mainstream paradigm of remote sensing image interpretation has long been dominated by vision-centered models, which rely on visual features for semantic understanding. However, these models face inherent limitations in handling multi-modal reasoning, semantic abstraction, and interactive decision-making. While recent advances have introduced Large Language Models (LLMs) into remote sensing workflows, existing studies primarily focus on downstream applications, lacking a unified theoretical framework that explains the cognitive role of language. This review advocates a paradigm shift from vision-centered to language-centered remote sensing interpretation. Drawing inspiration from the Global Workspace Theory (GWT) of human cognition, We propose a language-centered framework for remote sensing interpretation that treats LLMs as the cognitive central hub integrating perceptual, task, knowledge and action spaces to enable unified understanding, reasoning, and decision-making. We first explore the potential of LLMs as the central cognitive component in remote sensing interpretation, and then summarize core technical challenges, including unified multimodal representation, knowledge association, and reasoning and decision-making. Furthermore, we construct a global workspace-driven interpretation mechanism and review how language-centered solutions address each challenge. Finally, we outline future research directions from four perspectives: adaptive alignment of multimodal data, task understanding under dynamic knowledge constraints, trustworthy reasoning, and autonomous interaction. This work aims to provide a conceptual foundation for the next generation of remote sensing interpretation systems and establish a roadmap toward cognition-driven intelligent geospatial analysis.
AsyncFlow: An Asynchronous Streaming RL Framework for Efficient LLM Post-Training
Jul 02, 2025Reinforcement learning (RL) has become a pivotal technology in the post-training phase of large language models (LLMs). Traditional task-colocated RL frameworks suffer from significant scalability bottlenecks, while task-separated RL frameworks face challenges in complex dataflows and the corresponding resource idling and workload imbalance. Moreover, most existing frameworks are tightly coupled with LLM training or inference engines, making it difficult to support custom-designed engines. To address these challenges, we propose AsyncFlow, an asynchronous streaming RL framework for efficient post-training. Specifically, we introduce a distributed data storage and transfer module that provides a unified data management and fine-grained scheduling capability in a fully streamed manner. This architecture inherently facilitates automated pipeline overlapping among RL tasks and dynamic load balancing. Moreover, we propose a producer-consumer-based asynchronous workflow engineered to minimize computational idleness by strategically deferring parameter update process within staleness thresholds. Finally, the core capability of AsynFlow is architecturally decoupled from underlying training and inference engines and encapsulated by service-oriented user interfaces, offering a modular and customizable user experience. Extensive experiments demonstrate an average of 1.59 throughput improvement compared with state-of-the-art baseline. The presented architecture in this work provides actionable insights for next-generation RL training system designs.
Demystifying Distributed Training of Graph Neural Networks for Link Prediction
Jun 25, 2025Graph neural networks (GNNs) are powerful tools for solving graph-related problems. Distributed GNN frameworks and systems enhance the scalability of GNNs and accelerate model training, yet most are optimized for node classification. Their performance on link prediction remains underexplored. This paper demystifies distributed training of GNNs for link prediction by investigating the issue of performance degradation when each worker trains a GNN on its assigned partitioned subgraph without having access to the entire graph. We discover that the main sources of the issue come from not only the information loss caused by graph partitioning but also the ways of drawing negative samples during model training. While sharing the complete graph information with each worker resolves the issue and preserves link prediction accuracy, it incurs a high communication cost. We propose SpLPG, which effectively leverages graph sparsification to mitigate the issue of performance degradation at a reduced communication cost. Experiment results on several public real-world datasets demonstrate the effectiveness of SpLPG, which reduces the communication overhead by up to about 80% while mostly preserving link prediction accuracy.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.
Baltimore Atlas: FreqWeaver Adapter for Semi-supervised Ultra-high Spatial Resolution Land Cover Classification
Jun 18, 2025Ultra-high Spatial Resolution Land Cover Classification is essential for fine-grained land cover analysis, yet it remains challenging due to the high cost of pixel-level annotations, significant scale variation, and the limited adaptability of large-scale vision models. Existing methods typically focus on 1-meter spatial resolution imagery and rely heavily on annotated data, whereas practical applications often require processing higher-resolution imagery under weak supervision. To address this, we propose a parameter-efficient semi-supervised segmentation framework for 0.3 m spatial resolution imagery, which leverages the knowledge of SAM2 and introduces a remote sensing-specific FreqWeaver Adapter to enhance fine-grained detail modeling while maintaining a lightweight design at only 5.96% of the total model parameters. By effectively leveraging unlabeled data and maintaining minimal parameter overhead, the proposed method delivers robust segmentation results with superior structural consistency, achieving a 1.78% improvement over existing parameter-efficient tuning strategies and a 3.44% gain compared to state-of-the-art high-resolution remote sensing segmentation approaches.
Visual Perturbation and Adaptive Hard Negative Contrastive Learning for Compositional Reasoning in Vision-Language Models
May 21, 2025Vision-Language Models (VLMs) are essential for multimodal tasks, especially compositional reasoning (CR) tasks, which require distinguishing fine-grained semantic differences between visual and textual embeddings. However, existing methods primarily fine-tune the model by generating text-based hard negative samples, neglecting the importance of image-based negative samples, which results in insufficient training of the visual encoder and ultimately impacts the overall performance of the model. Moreover, negative samples are typically treated uniformly, without considering their difficulty levels, and the alignment of positive samples is insufficient, which leads to challenges in aligning difficult sample pairs. To address these issues, we propose Adaptive Hard Negative Perturbation Learning (AHNPL). AHNPL translates text-based hard negatives into the visual domain to generate semantically disturbed image-based negatives for training the model, thereby enhancing its overall performance. AHNPL also introduces a contrastive learning approach using a multimodal hard negative loss to improve the model's discrimination of hard negatives within each modality and a dynamic margin loss that adjusts the contrastive margin according to sample difficulty to enhance the distinction of challenging sample pairs. Experiments on three public datasets demonstrate that our method effectively boosts VLMs' performance on complex CR tasks. The source code is available at https://github.com/nynu-BDAI/AHNPL.