 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphoSim: An Interactive, Controllable, and Editable Language-guided 4D World Simulator
Oct 05, 2025



World models that support controllable and editable spatiotemporal environments are valuable for robotics, enabling scalable training data, repro ducible evaluation, and flexible task design. While recent text-to-video models generate realistic dynam ics, they are constrained to 2D views and offer limited interaction. We introduce MorphoSim, a language guided framework that generates 4D scenes with multi-view consistency and object-level controls. From natural language instructions, MorphoSim produces dynamic environments where objects can be directed, recolored, or removed, and scenes can be observed from arbitrary viewpoints. The framework integrates trajectory-guided generation with feature field dis tillation, allowing edits to be applied interactively without full re-generation. Experiments show that Mor phoSim maintains high scene fidelity while enabling controllability and editability. The code is available at https://github.com/eric-ai-lab/Morph4D.
The Unreasonable Effectiveness of Scaling Agents for Computer Use
Oct 02, 2025Computer-use agents (CUAs) hold promise for automating everyday digital tasks, but their unreliability and high variance hinder their application to long-horizon, complex tasks. We introduce Behavior Best-of-N (bBoN), a method that scales over agents by generating multiple rollouts and selecting among them using behavior narratives that describe the agents' rollouts. It enables both wide exploration and principled trajectory selection, substantially improving robustness and success rates. On OSWorld, our bBoN scaling method establishes a new state of the art (SoTA) at 69.9%, significantly outperforming prior methods and approaching human-level performance at 72%, with comprehensive ablations validating key design choices. We further demonstrate strong generalization results to different operating systems on WindowsAgentArena and AndroidWorld. Crucially, our results highlight the unreasonable effectiveness of scaling CUAs, when you do it right: effective scaling requires structured trajectory understanding and selection, and bBoN provides a practical framework to achieve this.
"PhyWorldBench": A Comprehensive Evaluation of Physical Realism in Text-to-Video Models
Jul 17, 2025Video generation models have achieved remarkable progress in creating high-quality, photorealistic content. However, their ability to accurately simulate physical phenomena remains a critical and unresolved challenge. This paper presents PhyWorldBench, a comprehensive benchmark designed to evaluate video generation models based on their adherence to the laws of physics. The benchmark covers multiple levels of physical phenomena, ranging from fundamental principles like object motion and energy conservation to more complex scenarios involving rigid body interactions and human or animal motion. Additionally, we introduce a novel ""Anti-Physics"" category, where prompts intentionally violate real-world physics, enabling the assessment of whether models can follow such instructions while maintaining logical consistency. Besides large-scale human evaluation, we also design a simple yet effective method that could utilize current MLLM to evaluate the physics realism in a zero-shot fashion. We evaluate 12 state-of-the-art text-to-video generation models, including five open-source and five proprietary models, with a detailed comparison and analysis. we identify pivotal challenges models face in adhering to real-world physics. Through systematic testing of their outputs across 1,050 curated prompts-spanning fundamental, composite, and anti-physics scenarios-we identify pivotal challenges these models face in adhering to real-world physics. We then rigorously examine their performance on diverse physical phenomena with varying prompt types, deriving targeted recommendations for crafting prompts that enhance fidelity to physical principles.
Agents of Change: Self-Evolving LLM Agents for Strategic Planning
Jun 05, 2025Recent advances in LLMs have enabled their use as autonomous agents across a range of tasks, yet they continue to struggle with formulating and adhering to coherent long-term strategies. In this paper, we investigate whether LLM agents can self-improve when placed in environments that explicitly challenge their strategic planning abilities. Using the board game Settlers of Catan, accessed through the open-source Catanatron framework, we benchmark a progression of LLM-based agents, from a simple game-playing agent to systems capable of autonomously rewriting their own prompts and their player agent's code. We introduce a multi-agent architecture in which specialized roles (Analyzer, Researcher, Coder, and Player) collaborate to iteratively analyze gameplay, research new strategies, and modify the agent's logic or prompt. By comparing manually crafted agents to those evolved entirely by LLMs, we evaluate how effectively these systems can diagnose failure and adapt over time. Our results show that self-evolving agents, particularly when powered by models like Claude 3.7 and GPT-4o, outperform static baselines by autonomously adopting their strategies, passing along sample behavior to game-playing agents, and demonstrating adaptive reasoning over multiple iterations.
SafeKey: Amplifying Aha-Moment Insights for Safety Reasoning
May 22, 2025



Large Reasoning Models (LRMs) introduce a new generation paradigm of explicitly reasoning before answering, leading to remarkable improvements in complex tasks. However, they pose great safety risks against harmful queries and adversarial attacks. While recent mainstream safety efforts on LRMs, supervised fine-tuning (SFT), improve safety performance, we find that SFT-aligned models struggle to generalize to unseen jailbreak prompts. After thorough investigation of LRMs' generation, we identify a safety aha moment that can activate safety reasoning and lead to a safe response. This aha moment typically appears in the `key sentence', which follows models' query understanding process and can indicate whether the model will proceed safely. Based on these insights, we propose SafeKey, including two complementary objectives to better activate the safety aha moment in the key sentence: (1) a Dual-Path Safety Head to enhance the safety signal in the model's internal representations before the key sentence, and (2) a Query-Mask Modeling objective to improve the models' attention on its query understanding, which has important safety hints. Experiments across multiple safety benchmarks demonstrate that our methods significantly improve safety generalization to a wide range of jailbreak attacks and out-of-distribution harmful prompts, lowering the average harmfulness rate by 9.6\%, while maintaining general abilities. Our analysis reveals how SafeKey enhances safety by reshaping internal attention and improving the quality of hidden representations.
GRIT: Teaching MLLMs to Think with Images
May 21, 2025Recent studies have demonstrated the efficacy of using Reinforcement Learning (RL) in building reasoning models that articulate chains of thoughts prior to producing final answers. However, despite ongoing advances that aim at enabling reasoning for vision-language tasks, existing open-source visual reasoning models typically generate reasoning content with pure natural language, lacking explicit integration of visual information. This limits their ability to produce clearly articulated and visually grounded reasoning chains. To this end, we propose Grounded Reasoning with Images and Texts (GRIT), a novel method for training MLLMs to think with images. GRIT introduces a grounded reasoning paradigm, in which models generate reasoning chains that interleave natural language and explicit bounding box coordinates. These coordinates point to regions of the input image that the model consults during its reasoning process. Additionally, GRIT is equipped with a reinforcement learning approach, GRPO-GR, built upon the GRPO algorithm. GRPO-GR employs robust rewards focused on the final answer accuracy and format of the grounded reasoning output, which eliminates the need for data with reasoning chain annotations or explicit bounding box labels. As a result, GRIT achieves exceptional data efficiency, requiring as few as 20 image-question-answer triplets from existing datasets. Comprehensive evaluations demonstrate that GRIT effectively trains MLLMs to produce coherent and visually grounded reasoning chains, showing a successful unification of reasoning and grounding abilities.
Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space
May 21, 2025Human cognition typically involves thinking through abstract, fluid concepts rather than strictly using discrete linguistic tokens. Current reasoning models, however, are constrained to reasoning within the boundaries of human language, processing discrete token embeddings that represent fixed points in the semantic space. This discrete constraint restricts the expressive power and upper potential of such reasoning models, often causing incomplete exploration of reasoning paths, as standard Chain-of-Thought (CoT) methods rely on sampling one token per step. In this work, we introduce Soft Thinking, a training-free method that emulates human-like "soft" reasoning by generating soft, abstract concept tokens in a continuous concept space. These concept tokens are created by the probability-weighted mixture of token embeddings, which form the continuous concept space, enabling smooth transitions and richer representations that transcend traditional discrete boundaries. In essence, each generated concept token encapsulates multiple meanings from related discrete tokens, implicitly exploring various reasoning paths to converge effectively toward the correct answer. Empirical evaluations on diverse mathematical and coding benchmarks consistently demonstrate the effectiveness and efficiency of Soft Thinking, improving pass@1 accuracy by up to 2.48 points while simultaneously reducing token usage by up to 22.4% compared to standard CoT. Qualitative analysis further reveals that Soft Thinking outputs remain highly interpretable and readable, highlighting the potential of Soft Thinking to break the inherent bottleneck of discrete language-based reasoning. Code is available at https://github.com/eric-ai-lab/Soft-Thinking.
Constructing a 3D Town from a Single Image
May 21, 2025Acquiring detailed 3D scenes typically demands costly equipment, multi-view data, or labor-intensive modeling. Therefore, a lightweight alternative, generating complex 3D scenes from a single top-down image, plays an essential role in real-world applications. While recent 3D generative models have achieved remarkable results at the object level, their extension to full-scene generation often leads to inconsistent geometry, layout hallucinations, and low-quality meshes. In this work, we introduce 3DTown, a training-free framework designed to synthesize realistic and coherent 3D scenes from a single top-down view. Our method is grounded in two principles: region-based generation to improve image-to-3D alignment and resolution, and spatial-aware 3D inpainting to ensure global scene coherence and high-quality geometry generation. Specifically, we decompose the input image into overlapping regions and generate each using a pretrained 3D object generator, followed by a masked rectified flow inpainting process that fills in missing geometry while maintaining structural continuity. This modular design allows us to overcome resolution bottlenecks and preserve spatial structure without requiring 3D supervision or fine-tuning. Extensive experiments across diverse scenes show that 3DTown outperforms state-of-the-art baselines, including Trellis, Hunyuan3D-2, and TripoSG, in terms of geometry quality, spatial coherence, and texture fidelity. Our results demonstrate that high-quality 3D town generation is achievable from a single image using a principled, training-free approach.
A Comprehensive Analysis for Visual Object Hallucination in Large Vision-Language Models
May 04, 2025
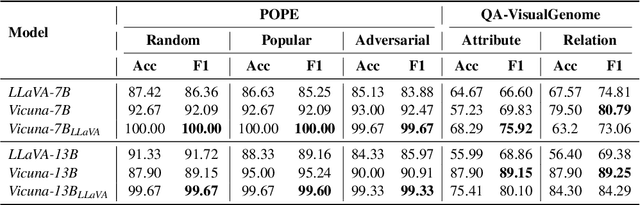


Large Vision-Language Models (LVLMs) demonstrate remarkable capabilities in multimodal tasks, but visual object hallucination remains a persistent issue. It refers to scenarios where models generate inaccurate visual object-related information based on the query input, potentially leading to misinformation and concerns about safety and reliability. Previous works focus on the evaluation and mitigation of visual hallucinations, but the underlying causes have not been comprehensively investigated. In this paper, we analyze each component of LLaVA-like LVLMs -- the large language model, the vision backbone, and the projector -- to identify potential sources of error and their impact. Based on our observations, we propose methods to mitigate hallucination for each problematic component. Additionally, we developed two hallucination benchmarks: QA-VisualGenome, which emphasizes attribute and relation hallucinations, and QA-FB15k, which focuses on cognition-based hallucinations.
Self-Resource Allocation in Multi-Agent LLM Systems
Apr 02, 2025



With the development of LLMs as agents, there is a growing interest in connecting multiple agents into multi-agent systems to solve tasks concurrently, focusing on their role in task assignment and coordination. This paper explores how LLMs can effectively allocate computational tasks among multiple agents, considering factors such as cost, efficiency, and performance. In this work, we address key questions, including the effectiveness of LLMs as orchestrators and planners, comparing their effectiveness in task assignment and coordination. Our experiments demonstrate that LLMs can achieve high validity and accuracy in resource allocation tasks. We find that the planner method outperforms the orchestrator method in handling concurrent actions, resulting in improved efficiency and better utilization of agents. Additionally, we show that providing explicit information about worker capabilities enhances the allocation strategies of planners, particularly when dealing with suboptimal workers.