 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBUNET: Blind Medical Image Segmentation Based on Secure UNET
Jul 14, 2020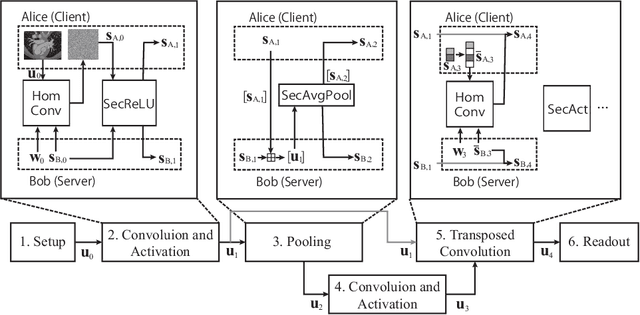
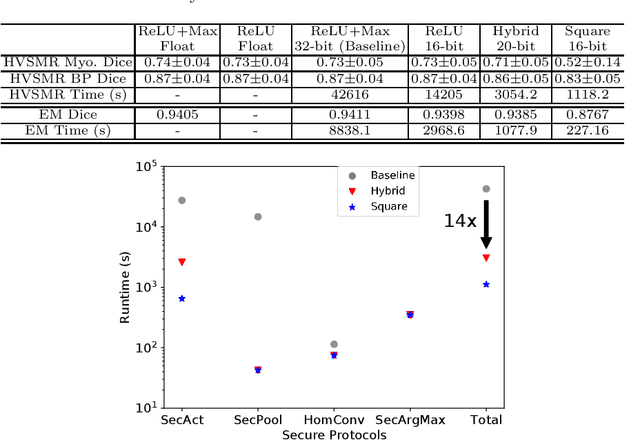
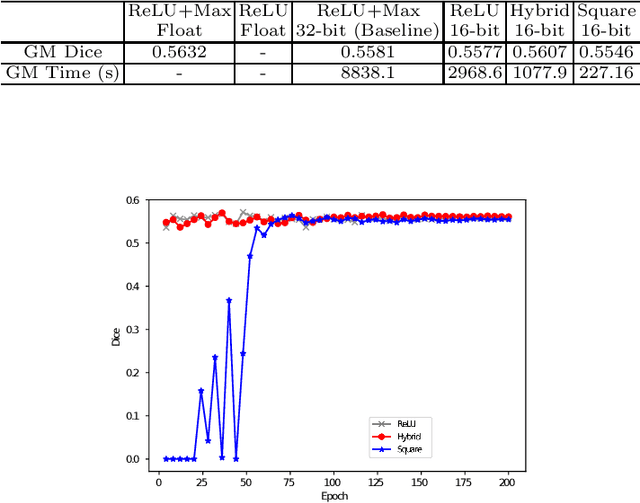
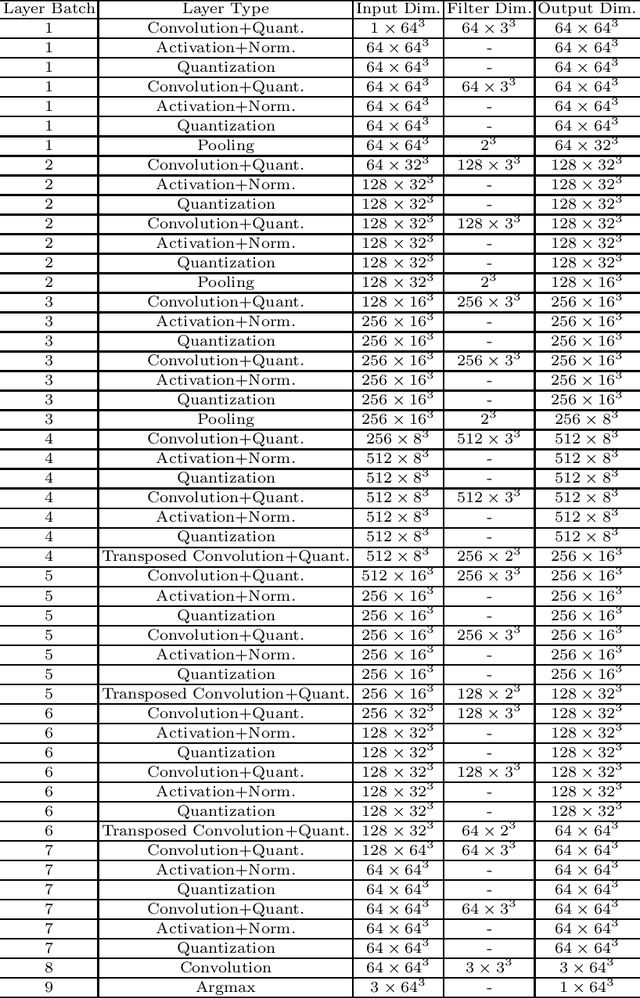
The strict security requirements placed on medical records by various privacy regulations become major obstacles in the age of big data. To ensure efficient machine learning as a service schemes while protecting data confidentiality, in this work, we propose blind UNET (BUNET), a secure protocol that implements privacy-preserving medical image segmentation based on the UNET architecture. In BUNET, we efficiently utilize cryptographic primitives such as homomorphic encryption and garbled circuits (GC) to design a complete secure protocol for the UNET neural architecture. In addition, we perform extensive architectural search in reducing the computational bottleneck of GC-based secure activation protocols with high-dimensional input data. In the experiment, we thoroughly examine the parameter space of our protocol, and show that we can achieve up to 14x inference time reduction compared to the-state-of-the-art secure inference technique on a baseline architecture with negligible accuracy degradation.
Evolving Metric Learning for Incremental and Decremental Features
Jun 27, 2020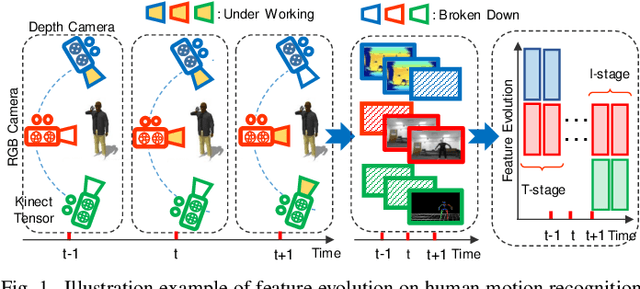
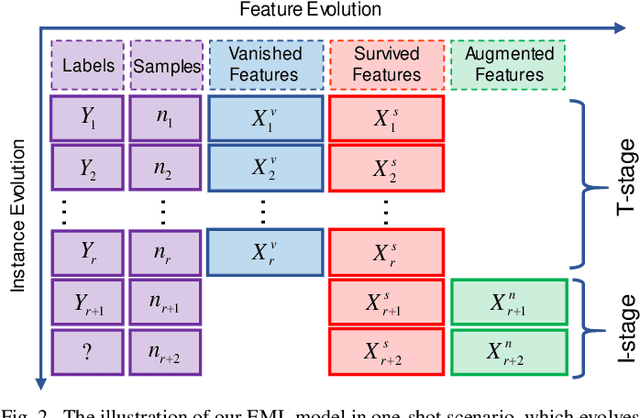
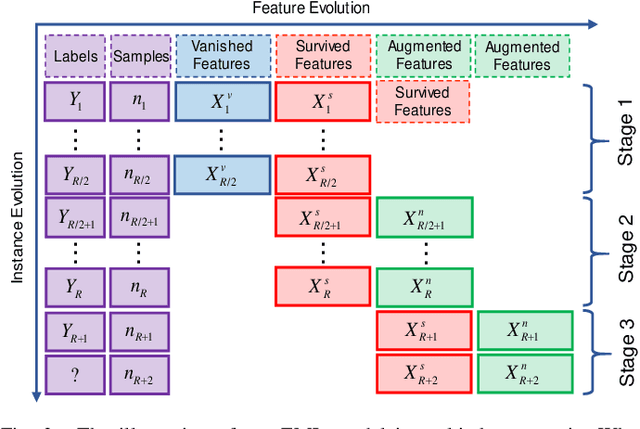

Online metric learning has been widely exploited for large-scale data classification due to the low computational cost. However, amongst online practical scenarios where the features are evolving (e.g., some features are vanished and some new features are augmented), most metric learning models cannot be successfully applied into these scenarios although they can tackle the evolving instances efficiently. To address the challenge, we propose a new online Evolving Metric Learning (EML) model for incremental and decremental features, which can handle the instance and feature evolutions simultaneously by incorporating with a smoothed Wasserstein metric distance. Specifically, our model contains two essential stages: the Transforming stage (T-stage) and the Inheriting stage (I-stage). For the T-stage, we propose to extract important information from vanished features while neglecting non-informative knowledge, and forward it into survived features by transforming them into a low-rank discriminative metric space. It further explores the intrinsic low-rank structure of heterogeneous samples to reduce the computation and memory burden especially for highly-dimensional large-scale data. For the I-stage, we inherit the metric performance of survived features from the T-stage and then expand to include the augmented new features. Moreover, the smoothed Wasserstein distance is utilized to characterize the similarity relations among the complex and heterogeneous data, since the evolving features in the different stages are not strictly aligned. In addition to tackling the challenges in one-shot case, we also extend our model into multi-shot scenario. After deriving an efficient optimization method for both T-stage and I-stage, extensive experiments on several benchmark datasets verify the superiority of our model.
What Can Be Transferred: Unsupervised Domain Adaptation for Endoscopic Lesions Segmentation
Apr 24, 2020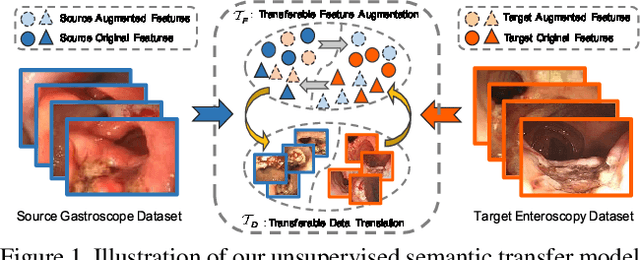

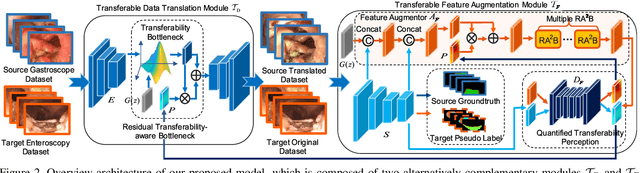
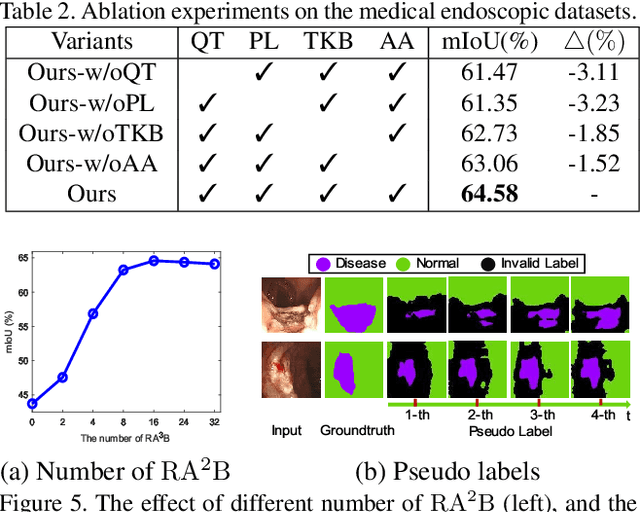
Unsupervised domain adaptation has attracted growing research attention on semantic segmentation. However, 1) most existing models cannot be directly applied into lesions transfer of medical images, due to the diverse appearances of same lesion among different datasets; 2) equal attention has been paid into all semantic representations instead of neglecting irrelevant knowledge, which leads to negative transfer of untransferable knowledge. To address these challenges, we develop a new unsupervised semantic transfer model including two complementary modules (i.e., T_D and T_F ) for endoscopic lesions segmentation, which can alternatively determine where and how to explore transferable domain-invariant knowledge between labeled source lesions dataset (e.g., gastroscope) and unlabeled target diseases dataset (e.g., enteroscopy). Specifically, T_D focuses on where to translate transferable visual information of medical lesions via residual transferability-aware bottleneck, while neglecting untransferable visual characterizations. Furthermore, T_F highlights how to augment transferable semantic features of various lesions and automatically ignore untransferable representations, which explores domain-invariant knowledge and in return improves the performance of T_D. To the end, theoretical analysis and extensive experiments on medical endoscopic dataset and several non-medical public datasets well demonstrate the superiority of our proposed model.
Deep Learning System to Screen Coronavirus Disease 2019 Pneumonia
Feb 21, 2020
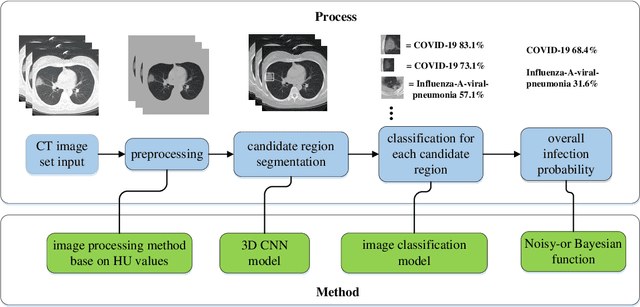

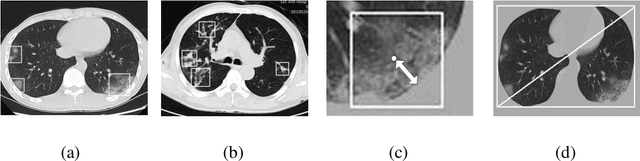
We found that the real time reverse transcription-polymerase chain reaction (RT-PCR) detection of viral RNA from sputum or nasopharyngeal swab has a relatively low positive rate in the early stage to determine COVID-19 (named by the World Health Organization). The manifestations of computed tomography (CT) imaging of COVID-19 had their own characteristics, which are different from other types of viral pneumonia, such as Influenza-A viral pneumonia. Therefore, clinical doctors call for another early diagnostic criteria for this new type of pneumonia as soon as possible.This study aimed to establish an early screening model to distinguish COVID-19 pneumonia from Influenza-A viral pneumonia and healthy cases with pulmonary CT images using deep learning techniques. The candidate infection regions were first segmented out using a 3-dimensional deep learning model from pulmonary CT image set. These separated images were then categorized into COVID-19, Influenza-A viral pneumonia and irrelevant to infection groups, together with the corresponding confidence scores using a location-attention classification model. Finally the infection type and total confidence score of this CT case were calculated with Noisy-or Bayesian function.The experiments result of benchmark dataset showed that the overall accuracy was 86.7 % from the perspective of CT cases as a whole.The deep learning models established in this study were effective for the early screening of COVID-19 patients and demonstrated to be a promising supplementary diagnostic method for frontline clinical doctors.
ColluEagle: Collusive review spammer detection using Markov random fields
Nov 05, 2019

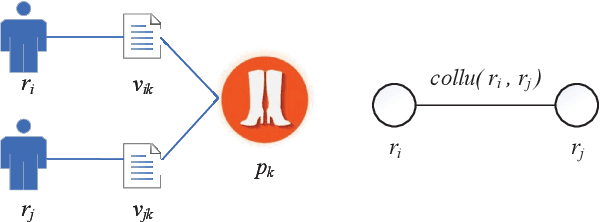
Product reviews are extremely valuable for online shoppers in providing purchase decisions. Driven by immense profit incentives, fraudsters deliberately fabricate untruthful reviews to distort the reputation of online products. As online reviews become more and more important, group spamming, i.e., a team of fraudsters working collaboratively to attack a set of target products, becomes a new fashion. Previous works use review network effects, i.e. the relationships among reviewers, reviews, and products, to detect fake reviews or review spammers, but ignore time effects, which are critical in characterizing group spamming. In this paper, we propose a novel Markov random field (MRF)-based method (ColluEagle) to detect collusive review spammers, as well as review spam campaigns, considering both network effects and time effects. First we identify co-review pairs, a review phenomenon that happens between two reviewers who review a common product in a similar way, and then model reviewers and their co-review pairs as a pairwise-MRF, and use loopy belief propagation to evaluate the suspiciousness of reviewers. We further design a high quality yet easy-to-compute node prior for ColluEagle, through which the review spammer groups can also be subsequently identified. Experiments show that ColluEagle can not only detect collusive spammers with high precision, significantly outperforming state-of-the-art baselines --- FraudEagle and SpEagle, but also identify highly suspicious review spammer campaigns.
MRNN: A Multi-Resolution Neural Network with Duplex Attention for Document Retrieval in the Context of Question Answering
Nov 03, 2019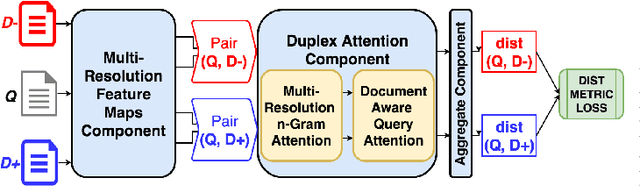
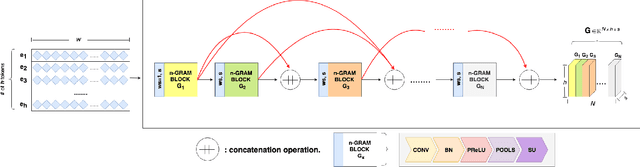
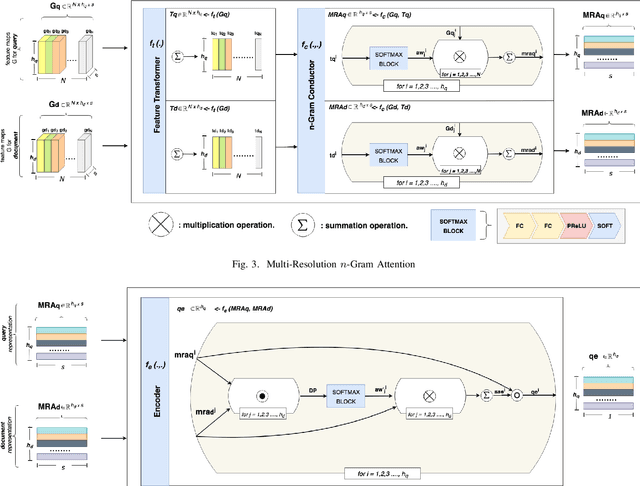

The primary goal of ad-hoc retrieval (document retrieval in the context of question answering) is to find relevant documents satisfied the information need posted in a natural language query. It requires a good understanding of the query and all the documents in a corpus, which is difficult because the meaning of natural language texts depends on the context, syntax,and semantics. Recently deep neural networks have been used to rank search results in response to a query. In this paper, we devise a multi-resolution neural network(MRNN) to leverage the whole hierarchy of representations for document retrieval. The proposed MRNN model is capable of deriving a representation that integrates representations of different levels of abstraction from all the layers of the learned hierarchical representation.Moreover, a duplex attention component is designed to refinethe multi-resolution representation so that an optimal contextfor matching the query and document can be determined. More specifically, the first attention mechanism determines optimal context from the learned multi-resolution representation for the query and document. The latter attention mechanism aims to fine-tune the representation so that the query and the relevant document are closer in proximity. The empirical study shows that MRNN with the duplex attention is significantly superior to existing models used for ad-hoc retrieval on benchmark datasets including SQuAD, WikiQA, QUASAR, and TrecQA.
On Neural Architecture Search for Resource-Constrained Hardware Platforms
Oct 31, 2019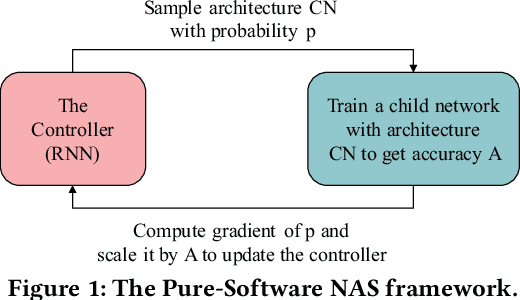
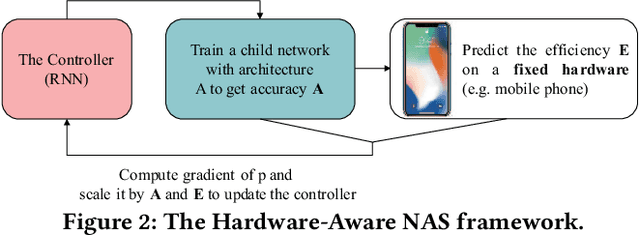

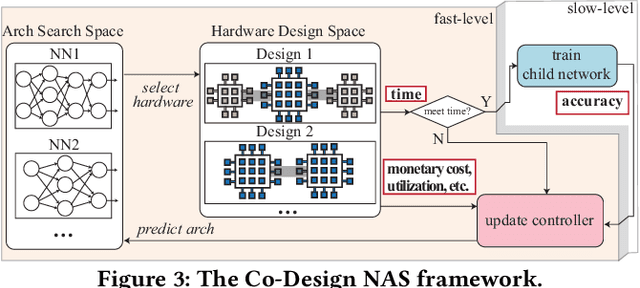
In the recent past, the success of Neural Architecture Search (NAS) has enabled researchers to broadly explore the design space using learning-based methods. Apart from finding better neural network architectures, the idea of automation has also inspired to improve their implementations on hardware. While some practices of hardware machine-learning automation have achieved remarkable performance, the traditional design concept is still followed: a network architecture is first structured with excellent test accuracy, and then compressed and optimized to fit into a target platform. Such a design flow will easily lead to inferior local-optimal solutions. To address this problem, we propose a new framework to jointly explore the space of neural architecture, hardware implementation, and quantization. Our objective is to find a quantized architecture with the highest accuracy that is implementable on given hardware specifications. We employ FPGAs to implement and test our designs with limited loop-up tables (LUTs) and required throughput. Compared to the separate design/searching methods, our framework has demonstrated much better performance under strict specifications and generated designs of higher accuracy by 18\% to 68\% in the task of classifying CIFAR10 images. With 30,000 LUTs, a light-weight design is found to achieve 82.98\% accuracy and 1293 images/second throughput, compared to which, under the same constraints, the traditional method even fails to find a valid solution.
MSU-Net: Multiscale Statistical U-Net for Real-time 3D Cardiac MRI Video Segmentation
Sep 15, 2019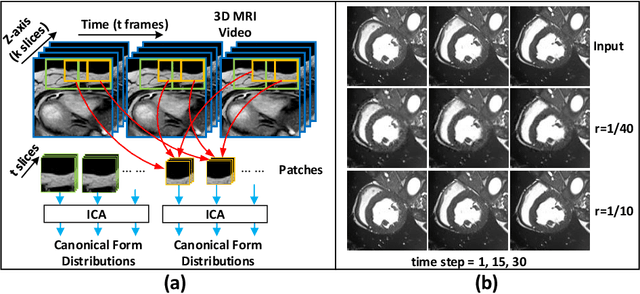
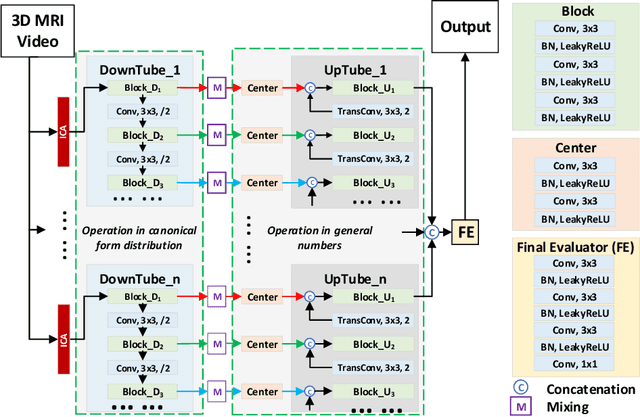
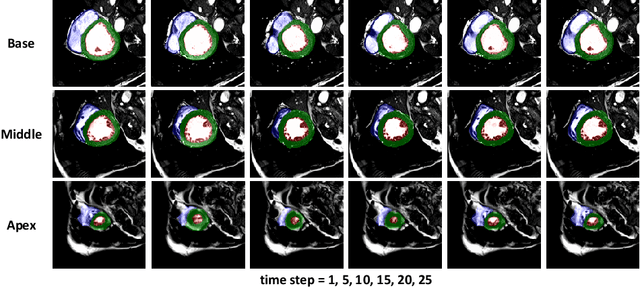
Cardiac magnetic resonance imaging (MRI) is an essential tool for MRI-guided surgery and real-time intervention. The MRI videos are expected to be segmented on-the-fly in real practice. However, existing segmentation methods would suffer from drastic accuracy loss when modified for speedup. In this work, we propose Multiscale Statistical U-Net (MSU-Net) for real-time 3D MRI video segmentation in cardiac surgical guidance. Our idea is to model the input samples as multiscale canonical form distributions for speedup, while the spatio-temporal correlation is still fully utilized. A parallel statistical U-Net is then designed to efficiently process these distributions. The fast data sampling and efficient parallel structure of MSU-Net endorse the fast and accurate inference. Compared with vanilla U-Net and a modified state-of-the-art method GridNet, our method achieves up to 268% and 237% speedup with 1.6% and 3.6% increased Dice scores.
Accurate Congenital Heart Disease Model Generation for 3D Printing
Jul 12, 2019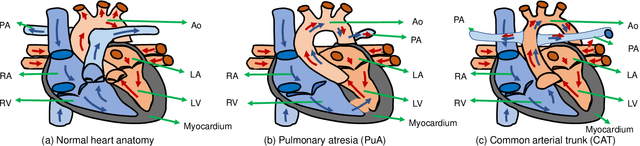
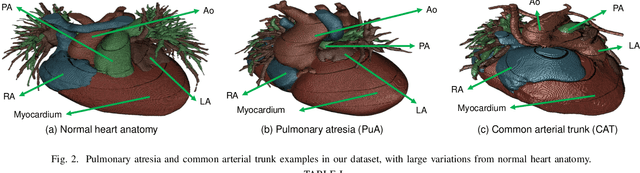
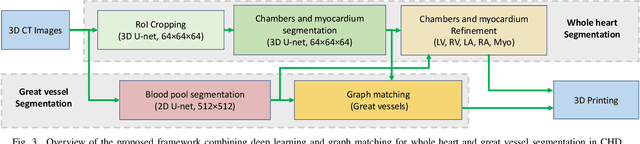
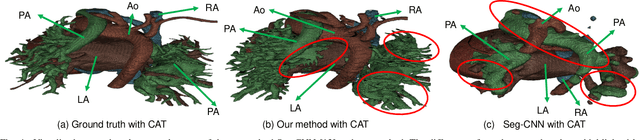
3D printing has been widely adopted for clinical decision making and interventional planning of Congenital heart disease (CHD), while whole heart and great vessel segmentation is the most significant but time-consuming step in the model generation for 3D printing. While various automatic whole heart and great vessel segmentation frameworks have been developed in the literature, they are ineffective when applied to medical images in CHD, which have significant variations in heart structure and great vessel connections. To address the challenge, we leverage the power of deep learning in processing regular structures and that of graph algorithms in dealing with large variations and propose a framework that combines both for whole heart and great vessel segmentation in CHD. Particularly, we first use deep learning to segment the four chambers and myocardium followed by the blood pool, where variations are usually small. We then extract the connection information and apply graph matching to determine the categories of all the vessels. Experimental results using 683D CT images covering 14 types of CHD show that our method can increase Dice score by 11.9% on average compared with the state-of-the-art whole heart and great vessel segmentation method in normal anatomy. The segmentation results are also printed out using 3D printers for validation.
Exploiting Computation Power of Blockchain for Biomedical Image Segmentation
Apr 15, 2019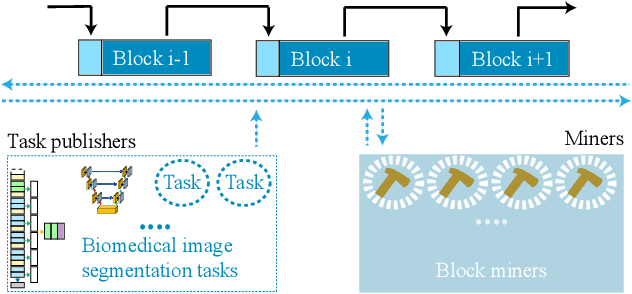
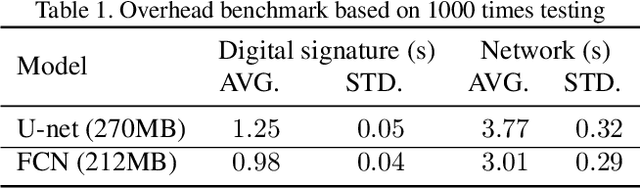
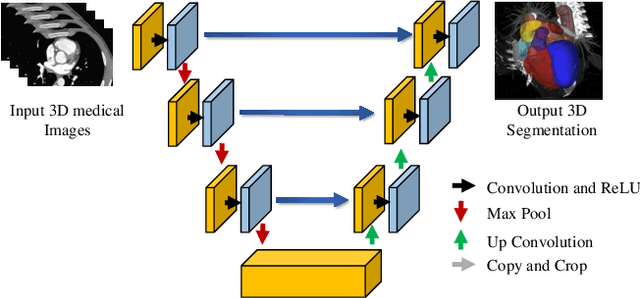
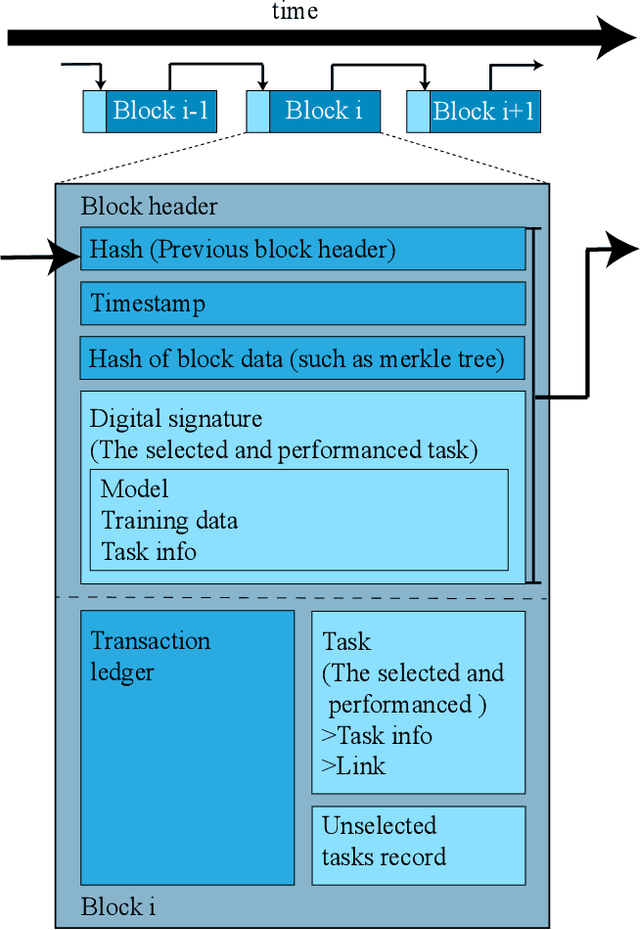
Biomedical image segmentation based on Deep neuralnetwork (DNN) is a promising approach that assists clin-ical diagnosis. This approach demands enormous com-putation power because these DNN models are compli-cated, and the size of the training data is usually very huge.As blockchain technology based on Proof-of-Work (PoW)has been widely used, an immense amount of computationpower is consumed to maintain the PoW consensus. Inthis paper, we propose a design to exploit the computationpower of blockchain miners for biomedical image segmen-tation, which lets miners perform image segmentation as theProof-of-Useful-Work (PoUW) instead of calculating use-less hash values. This work distinguishes itself from otherPoUW by addressing various limitations of related others.As the overhead evaluation shown in Section 5 indicates,for U-net and FCN, the average overhead of digital sig-nature is 1.25 seconds and 0.98 seconds, respectively, andthe average overhead of network is 3.77 seconds and 3.01seconds, respectively. These quantitative experiment resultsprove that the overhead of the digital signature and networkis small and comparable to other existing PoUW designs.