 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgen-stage Latent Dirichlet Allocation: A Novel Approach for LDA
Oct 20, 2021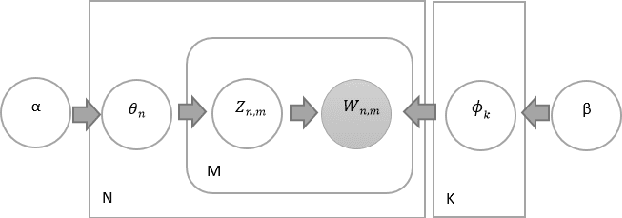

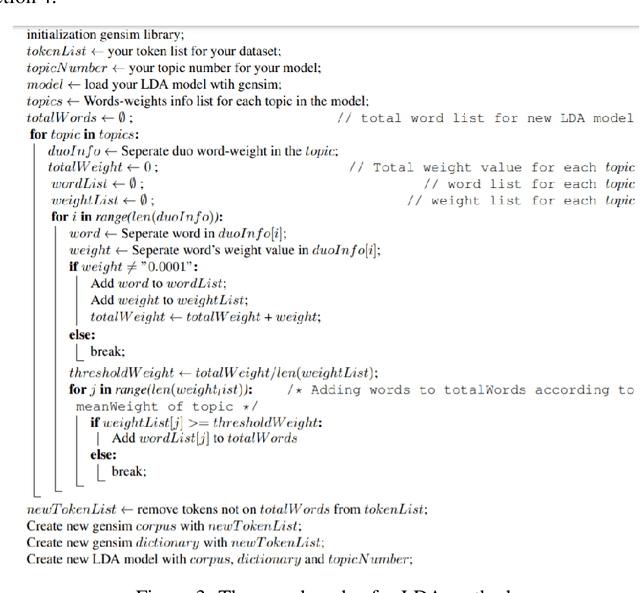
Nowadays, data analysis has become a problem as the amount of data is constantly increasing. In order to overcome this problem in textual data, many models and methods are used in natural language processing. The topic modeling field is one of these methods. Topic modeling allows determining the semantic structure of a text document. Latent Dirichlet Allocation (LDA) is the most common method among topic modeling methods. In this article, the proposed n-stage LDA method, which can enable the LDA method to be used more effectively, is explained in detail. The positive effect of the method has been demonstrated by the applied English and Turkish studies. Since the method focuses on reducing the word count in the dictionary, it can be used language-independently. You can access the open-source code of the method and the example: https://github.com/anil1055/n-stage_LDA
Evaluation of Non-Negative Matrix Factorization and n-stage Latent Dirichlet Allocation for Emotion Analysis in Turkish Tweets
Sep 27, 2021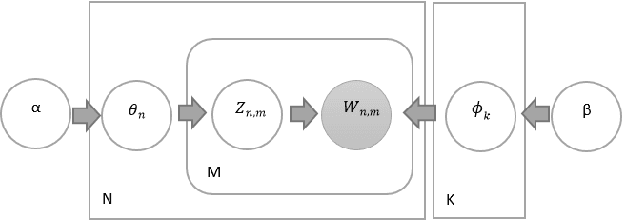
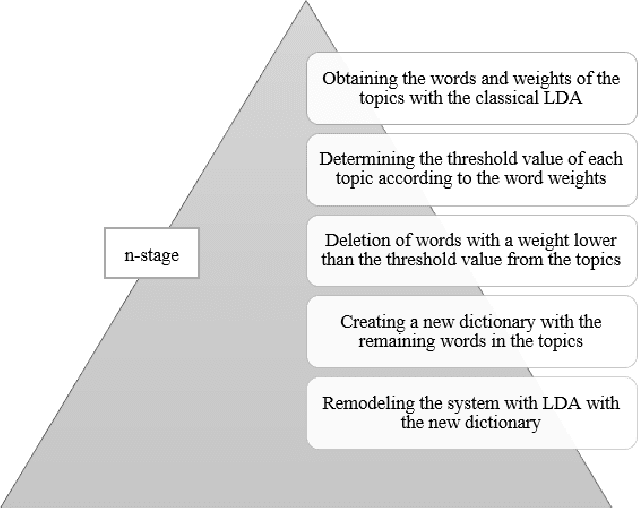


With the development of technology, the use of social media has become quite common. Analyzing comments on social media in areas such as media and advertising plays an important role today. For this reason, new and traditional natural language processing methods are used to detect the emotion of these shares. In this paper, the Latent Dirichlet Allocation, namely LDA, and Non-Negative Matrix Factorization methods in topic modeling were used to determine which emotion the Turkish tweets posted via Twitter. In addition, the accuracy of a proposed n-level method based on LDA was analyzed. Dataset consists of 5 emotions, namely angry, fear, happy, sad and confused. NMF was the most successful method among all topic modeling methods in this study. Then, the F1-measure of Random Forest, Naive Bayes and Support Vector Machine methods was analyzed by obtaining a file suitable for Weka by using the word weights and class labels of the topics. Among the Weka results, the most successful method was n-stage LDA, and the most successful algorithm was Random Forest.
* Published in: 2019 Innovations in Intelligent Systems and Applications Conference (ASYU). This paper is extension version of Comparison Method for Emotion Detection of Twitter Users (http://dx.doi.org/10.1109/ASYU48272.2019.8946435). Please citation this IEEE paper
MRNN: A Multi-Resolution Neural Network with Duplex Attention for Document Retrieval in the Context of Question Answering
Nov 03, 2019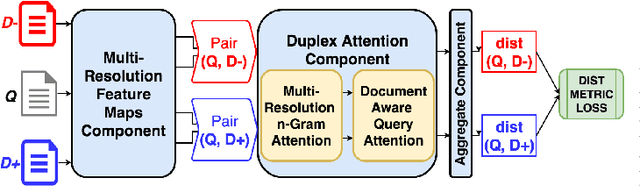
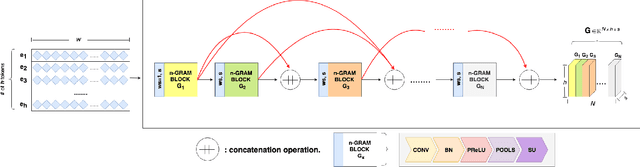
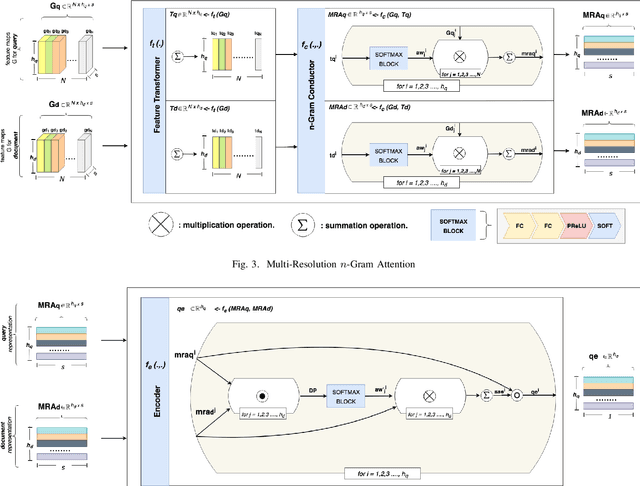

The primary goal of ad-hoc retrieval (document retrieval in the context of question answering) is to find relevant documents satisfied the information need posted in a natural language query. It requires a good understanding of the query and all the documents in a corpus, which is difficult because the meaning of natural language texts depends on the context, syntax,and semantics. Recently deep neural networks have been used to rank search results in response to a query. In this paper, we devise a multi-resolution neural network(MRNN) to leverage the whole hierarchy of representations for document retrieval. The proposed MRNN model is capable of deriving a representation that integrates representations of different levels of abstraction from all the layers of the learned hierarchical representation.Moreover, a duplex attention component is designed to refinethe multi-resolution representation so that an optimal contextfor matching the query and document can be determined. More specifically, the first attention mechanism determines optimal context from the learned multi-resolution representation for the query and document. The latter attention mechanism aims to fine-tune the representation so that the query and the relevant document are closer in proximity. The empirical study shows that MRNN with the duplex attention is significantly superior to existing models used for ad-hoc retrieval on benchmark datasets including SQuAD, WikiQA, QUASAR, and TrecQA.
A Multi-Resolution Word Embedding for Document Retrieval from Large Unstructured Knowledge Bases
Feb 21, 2019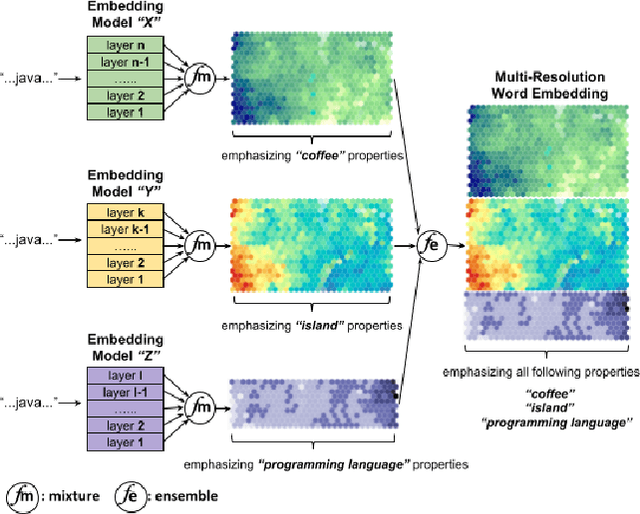
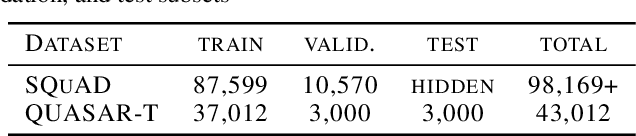
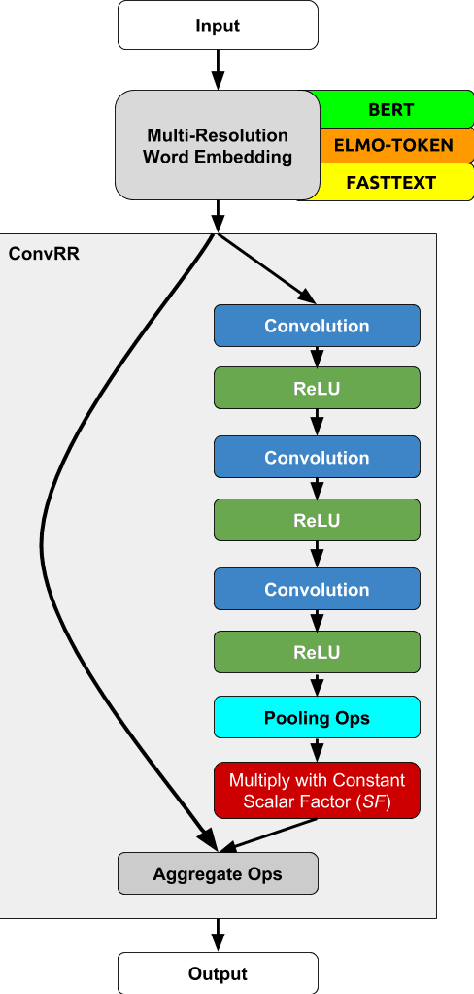

Deep language models learning a hierarchical representation proved to be a powerful tool for natural language processing, text mining and information retrieval. However, representations that perform well for retrieval must capture semantic meaning at different levels of abstraction or context-scopes. In this paper, we propose a new method to generate multi-resolution word embedding representing documents at multiple resolutions in term of context-scopes. In order to investigate its performance, we use the Stanford Question Answering Dataset (SQuAD) and the Question Answering by Search And Reading (QUASAR) in an open-domain question-answering setting, where the first task is to find documents useful for answering a given question. To this end, we first compare the quality of various text-embedding methods for retrieval performance and give an extensive empirical comparison with the performance of various non-augmented base embeddings with and without multi-resolution representation. We argue that multi-resolution word embeddings are consistently superior to the original counterparts and deep residual neural models specifically trained for retrieval purposes can yield further significant gains when they are used for augmenting those embeddings.
Text Embeddings for Retrieval From a Large Knowledge Base
Oct 24, 2018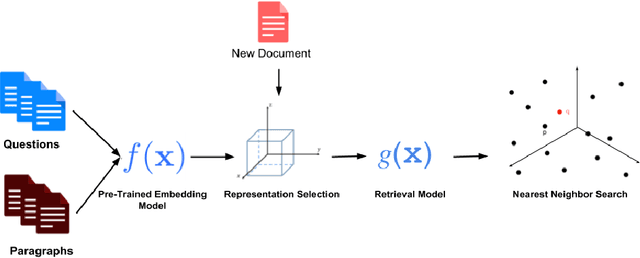
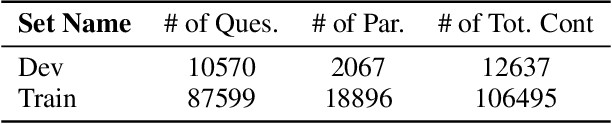

Text embedding representing natural language documents in a semantic vector space can be used for document retrieval using nearest neighbor lookup. In order to study the feasibility of neural models specialized for retrieval in a semantically meaningful way, we suggest the use of the Stanford Question Answering Dataset (SQuAD) in an open-domain question answering context, where the first task is to find paragraphs useful for answering a given question. First, we compare the quality of various text-embedding methods on the performance of retrieval and give an extensive empirical comparison on the performance of various non-augmented base embedding with, and without IDF weighting. Our main results are that by training deep residual neural models specifically for retrieval purposes can yield significant gains when it is used to augment existing embeddings. We also establish that deeper models are superior to this task. The best base baseline embeddings augmented by our learned neural approach improves the top-1 paragraph recall of the system by 14%.