 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAN: Revisiting Feature Co-Action for Click-Through Rate Prediction
Nov 11, 2020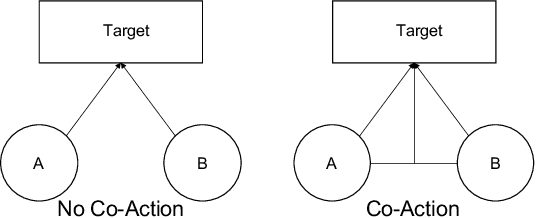
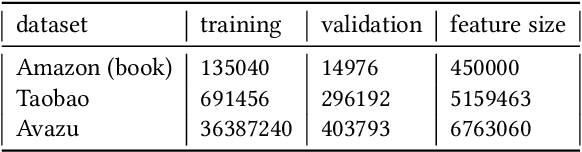
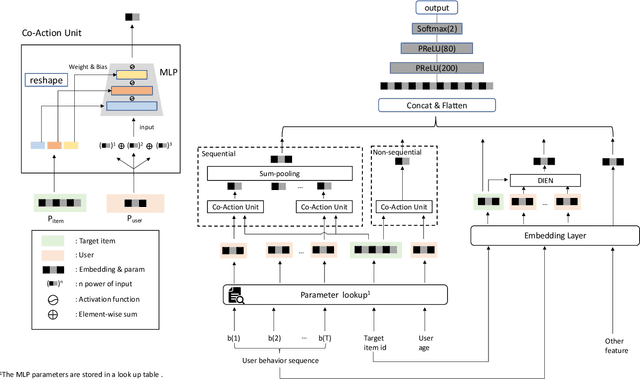
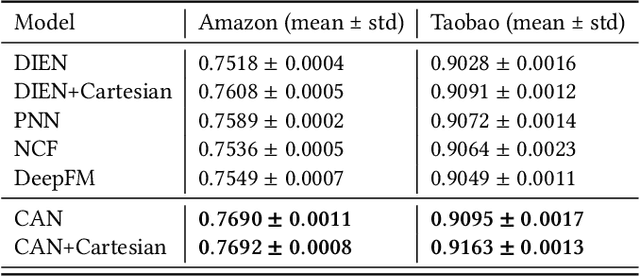
Inspired by the success of deep learning, recent industrial Click-Through Rate (CTR) prediction models have made the transition from traditional shallow approaches to deep approaches. Deep Neural Networks (DNNs) are known for its ability to learn non-linear interactions from raw feature automatically, however, the non-linear feature interaction is learned in an implicit manner. The non-linear interaction may be hard to capture and explicitly model the \textit{co-action} of raw feature is beneficial for CTR prediction. \textit{Co-action} refers to the collective effects of features toward final prediction. In this paper, we argue that current CTR models do not fully explore the potential of feature co-action. We conduct experiments and show that the effect of feature co-action is underestimated seriously. Motivated by our observation, we propose feature Co-Action Network (CAN) to explore the potential of feature co-action. The proposed model can efficiently and effectively capture the feature co-action, which improves the model performance while reduce the storage and computation consumption. Experiment results on public and industrial datasets show that CAN outperforms state-of-the-art CTR models by a large margin. Up to now, CAN has been deployed in the Alibaba display advertisement system, obtaining averaging 12\% improvement on CTR and 8\% on RPM.
COLD: Towards the Next Generation of Pre-Ranking System
Aug 17, 2020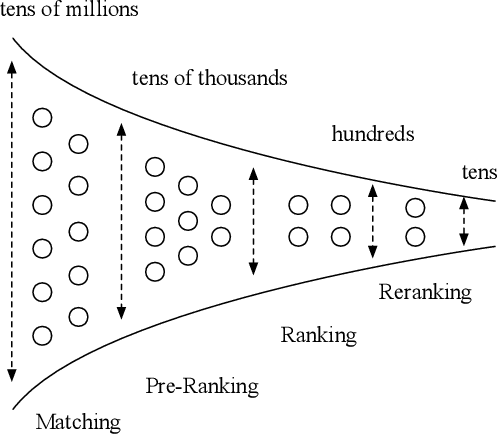

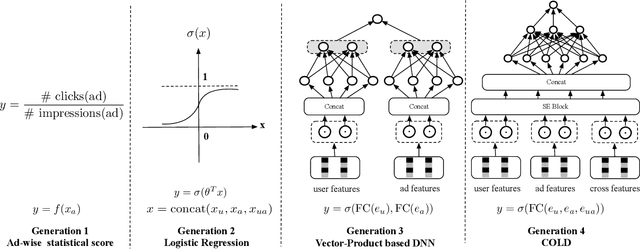

Multi-stage cascade architecture exists widely in many industrial systems such as recommender systems and online advertising, which often consists of sequential modules including matching, pre-ranking, ranking, etc. For a long time, it is believed pre-ranking is just a simplified version of the ranking module, considering the larger size of the candidate set to be ranked. Thus, efforts are made mostly on simplifying ranking model to handle the explosion of computing power for online inference. In this paper, we rethink the challenge of the pre-ranking system from an algorithm-system co-design view. Instead of saving computing power with restriction of model architecture which causes loss of model performance, here we design a new pre-ranking system by joint optimization of both the pre-ranking model and the computing power it costs. We name it COLD (Computing power cost-aware Online and Lightweight Deep pre-ranking system). COLD beats SOTA in three folds: (i) an arbitrary deep model with cross features can be applied in COLD under a constraint of controllable computing power cost. (ii) computing power cost is explicitly reduced by applying optimization tricks for inference acceleration. This further brings space for COLD to apply more complex deep models to reach better performance. (iii) COLD model works in an online learning and severing manner, bringing it excellent ability to handle the challenge of the data distribution shift. Meanwhile, the fully online pre-ranking system of COLD provides us with a flexible infrastructure that supports efficient new model developing and online A/B testing.Since 2019, COLD has been deployed in almost all products involving the pre-ranking module in the display advertising system in Alibaba, bringing significant improvements.
Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction
Jun 29, 2020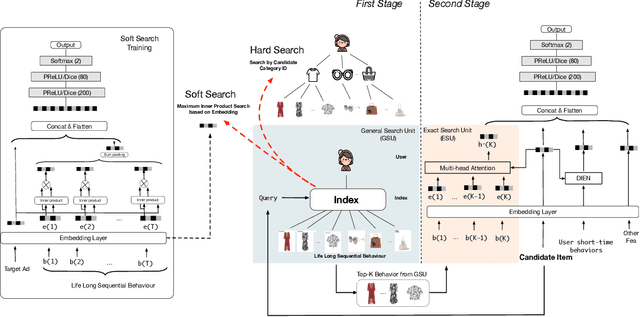


Rich user behavior data has been proven to be of great value for click-through rate prediction tasks, especially in industrial applications such as recommender systems and online advertising. Both industry and academy have paid much attention to this topic and propose different approaches to modeling with long sequential user behavior data. Among them, memory network based model MIMN proposed by Alibaba, achieves SOTA with the co-design of both learning algorithm and serving system. MIMN is the first industrial solution that can model sequential user behavior data with length scaling up to 1000. However, MIMN fails to precisely capture user interests given a specific candidate item when the length of user behavior sequence increases further, say, by 10 times or more. This challenge exists widely in previously proposed approaches. In this paper, we tackle this problem by designing a new modeling paradigm, which we name as Search-based Interest Model (SIM). SIM extracts user interests with two cascaded search units: (i) General Search Unit acts as a general search from the raw and arbitrary long sequential behavior data, with query information from candidate item, and gets a Sub user Behavior Sequence which is relevant to candidate item; (ii) Exact Search Unit models the precise relationship between candidate item and SBS. This cascaded search paradigm enables SIM with a better ability to model lifelong sequential behavior data in both scalability and accuracy. Apart from the learning algorithm, we also introduce our hands-on experience on how to implement SIM in large scale industrial systems. Since 2019, SIM has been deployed in the display advertising system in Alibaba, bringing 7.1\% CTR and 4.4\% RPM lift, which is significant to the business. Serving the main traffic in our real system now, SIM models user behavior data with maximum length reaching up to 54000, pushing SOTA to 54x.
DCAF: A Dynamic Computation Allocation Framework for Online Serving System
Jun 17, 2020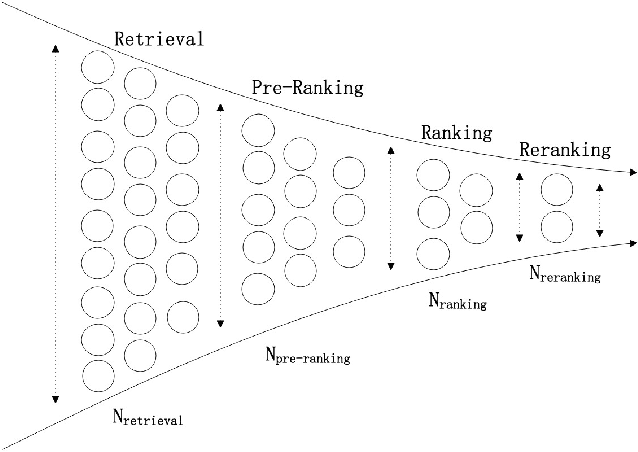
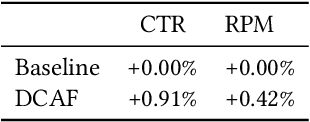
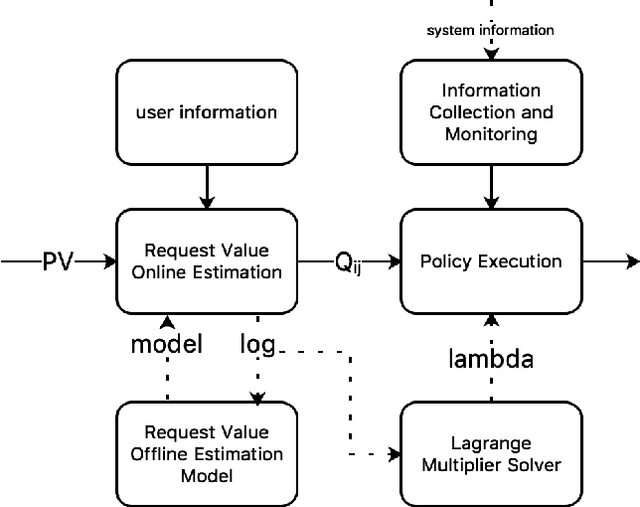

Modern large-scale systems such as recommender system and online advertising system are built upon computation-intensive infrastructure. The typical objective in these applications is to maximize the total revenue, e.g. GMV~(Gross Merchandise Volume), under a limited computation resource. Usually, the online serving system follows a multi-stage cascade architecture, which consists of several stages including retrieval, pre-ranking, ranking, etc. These stages usually allocate resource manually with specific computing power budgets, which requires the serving configuration to adapt accordingly. As a result, the existing system easily falls into suboptimal solutions with respect to maximizing the total revenue. The limitation is due to the face that, although the value of traffic requests vary greatly, online serving system still spends equal computing power among them. In this paper, we introduce a novel idea that online serving system could treat each traffic request differently and allocate "personalized" computation resource based on its value. We formulate this resource allocation problem as a knapsack problem and propose a Dynamic Computation Allocation Framework~(DCAF). Under some general assumptions, DCAF can theoretically guarantee that the system can maximize the total revenue within given computation budget. DCAF brings significant improvement and has been deployed in the display advertising system of Taobao for serving the main traffic. With DCAF, we are able to maintain the same business performance with 20\% computation resource reduction.
AMAD: Adversarial Multiscale Anomaly Detection on High-Dimensional and Time-Evolving Categorical Data
Jul 12, 2019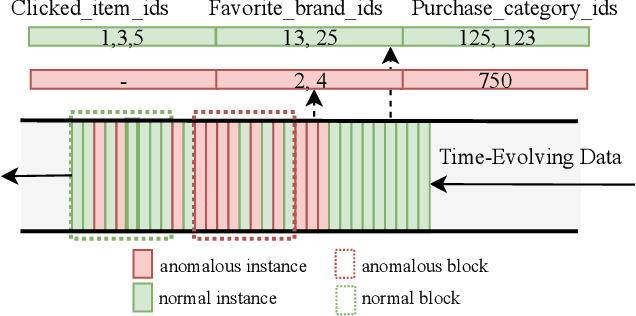
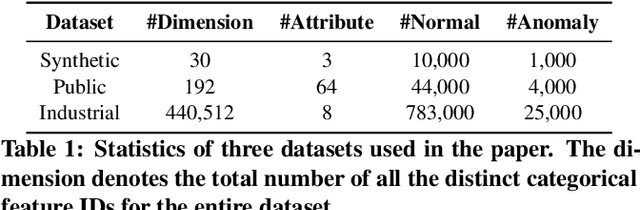
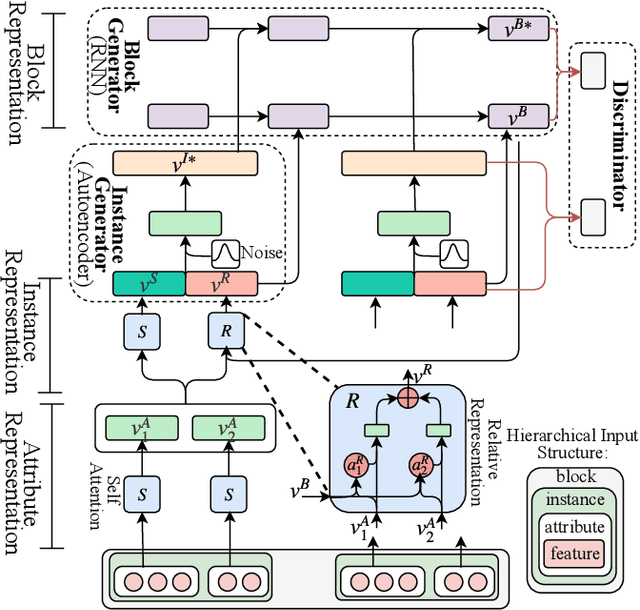
Anomaly detection is facing with emerging challenges in many important industry domains, such as cyber security and online recommendation and advertising. The recent trend in these areas calls for anomaly detection on time-evolving data with high-dimensional categorical features without labeled samples. Also, there is an increasing demand for identifying and monitoring irregular patterns at multiple resolutions. In this work, we propose a unified end-to-end approach to solve these challenges by combining the advantages of Adversarial Autoencoder and Recurrent Neural Network. The model learns data representations cross different scales with attention mechanisms, on which an enhanced two-resolution anomaly detector is developed for both instances and data blocks. Extensive experiments are performed over three types of datasets to demonstrate the efficacy of our method and its superiority over the state-of-art approaches.
Res-embedding for Deep Learning Based Click-Through Rate Prediction Modeling
Jun 25, 2019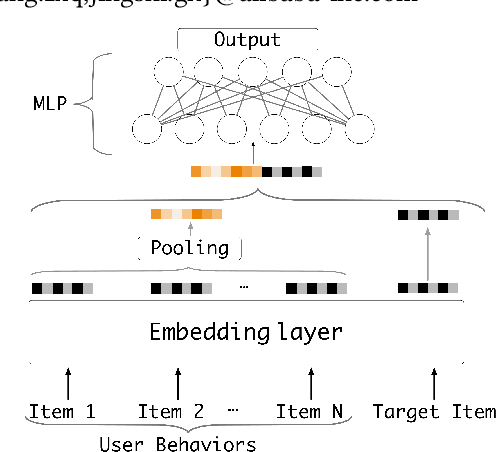
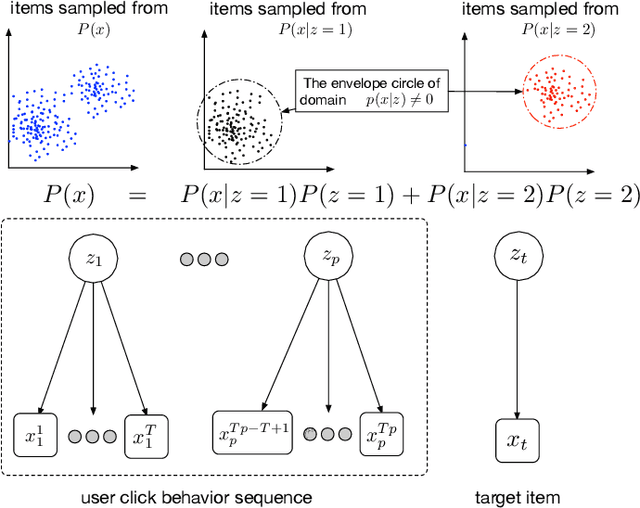
Recently, click-through rate (CTR) prediction models have evolved from shallow methods to deep neural networks. Most deep CTR models follow an Embedding\&MLP paradigm, that is, first mapping discrete id features, e.g. user visited items, into low dimensional vectors with an embedding module, then learn a multi-layer perception (MLP) to fit the target. In this way, embedding module performs as the representative learning and plays a key role in the model performance. However, in many real-world applications, deep CTR model often suffers from poor generalization performance, which is mostly due to the learning of embedding parameters. In this paper, we model user behavior using an interest delay model, study carefully the embedding mechanism, and obtain two important results: (i) We theoretically prove that small aggregation radius of embedding vectors of items which belongs to a same user interest domain will result in good generalization performance of deep CTR model. (ii) Following our theoretical analysis, we design a new embedding structure named res-embedding. In res-embedding module, embedding vector of each item is the sum of two components: (i) a central embedding vector calculated from an item-based interest graph (ii) a residual embedding vector with its scale to be relatively small. Empirical evaluation on several public datasets demonstrates the effectiveness of the proposed res-embedding structure, which brings significant improvement on the model performance.
Deep Interest Evolution Network for Click-Through Rate Prediction
Nov 06, 2018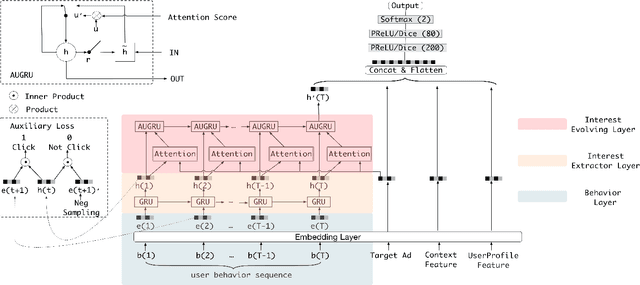

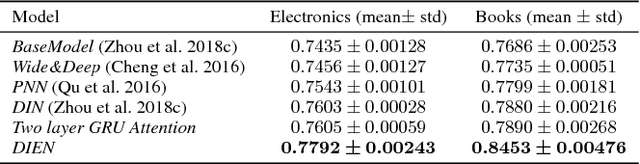
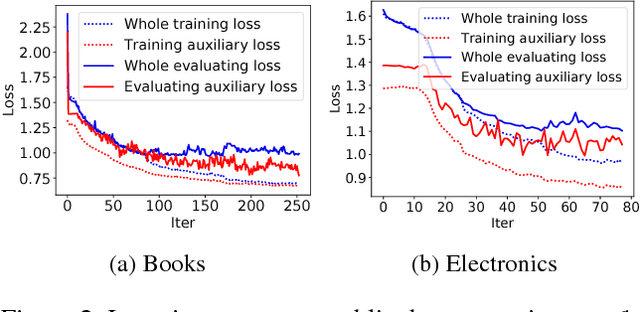
Click-through rate~(CTR) prediction, whose goal is to estimate the probability of the user clicks, has become one of the core tasks in advertising systems. For CTR prediction model, it is necessary to capture the latent user interest behind the user behavior data. Besides, considering the changing of the external environment and the internal cognition, user interest evolves over time dynamically. There are several CTR prediction methods for interest modeling, while most of them regard the representation of behavior as the interest directly, and lack specially modeling for latent interest behind the concrete behavior. Moreover, few work consider the changing trend of interest. In this paper, we propose a novel model, named Deep Interest Evolution Network~(DIEN), for CTR prediction. Specifically, we design interest extractor layer to capture temporal interests from history behavior sequence. At this layer, we introduce an auxiliary loss to supervise interest extracting at each step. As user interests are diverse, especially in the e-commerce system, we propose interest evolving layer to capture interest evolving process that is relative to the target item. At interest evolving layer, attention mechanism is embedded into the sequential structure novelly, and the effects of relative interests are strengthened during interest evolution. In the experiments on both public and industrial datasets, DIEN significantly outperforms the state-of-the-art solutions. Notably, DIEN has been deployed in the display advertisement system of Taobao, and obtained 20.7\% improvement on CTR.
Deep Interest Network for Click-Through Rate Prediction
Sep 13, 2018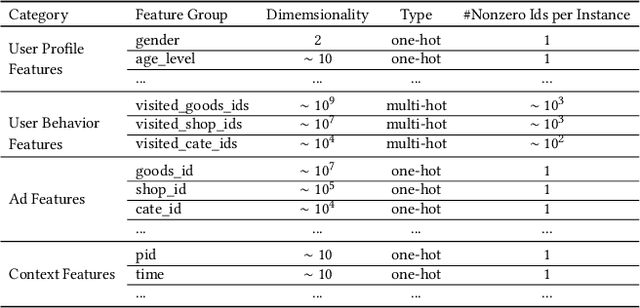
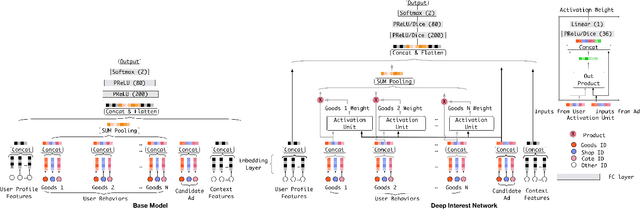
Click-through rate prediction is an essential task in industrial applications, such as online advertising. Recently deep learning based models have been proposed, which follow a similar Embedding\&MLP paradigm. In these methods large scale sparse input features are first mapped into low dimensional embedding vectors, and then transformed into fixed-length vectors in a group-wise manner, finally concatenated together to fed into a multilayer perceptron (MLP) to learn the nonlinear relations among features. In this way, user features are compressed into a fixed-length representation vector, in regardless of what candidate ads are. The use of fixed-length vector will be a bottleneck, which brings difficulty for Embedding\&MLP methods to capture user's diverse interests effectively from rich historical behaviors. In this paper, we propose a novel model: Deep Interest Network (DIN) which tackles this challenge by designing a local activation unit to adaptively learn the representation of user interests from historical behaviors with respect to a certain ad. This representation vector varies over different ads, improving the expressive ability of model greatly. Besides, we develop two techniques: mini-batch aware regularization and data adaptive activation function which can help training industrial deep networks with hundreds of millions of parameters. Experiments on two public datasets as well as an Alibaba real production dataset with over 2 billion samples demonstrate the effectiveness of proposed approaches, which achieve superior performance compared with state-of-the-art methods. DIN now has been successfully deployed in the online display advertising system in Alibaba, serving the main traffic.
Image Matters: Visually modeling user behaviors using Advanced Model Server
Sep 04, 2018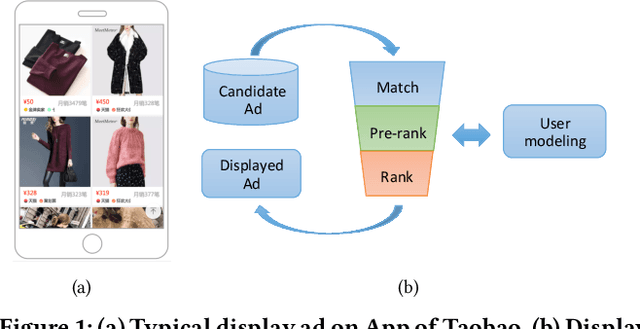

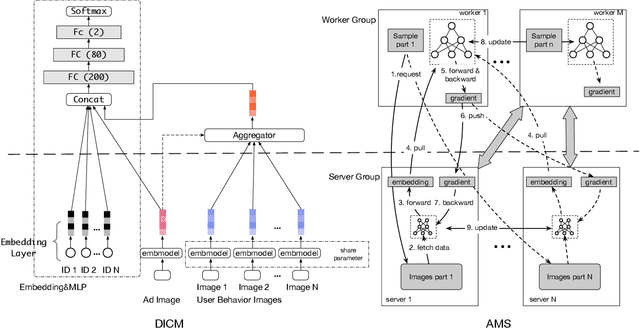
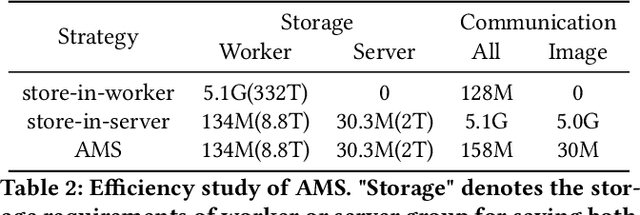
In Taobao, the largest e-commerce platform in China, billions of items are provided and typically displayed with their images. For better user experience and business effectiveness, Click Through Rate (CTR) prediction in online advertising system exploits abundant user historical behaviors to identify whether a user is interested in a candidate ad. Enhancing behavior representations with user behavior images will help understand user's visual preference and improve the accuracy of CTR prediction greatly. So we propose to model user preference jointly with user behavior ID features and behavior images. However, training with user behavior images brings tens to hundreds of images in one sample, giving rise to a great challenge in both communication and computation. To handle these challenges, we propose a novel and efficient distributed machine learning paradigm called Advanced Model Server (AMS). With the well known Parameter Server (PS) framework, each server node handles a separate part of parameters and updates them independently. AMS goes beyond this and is designed to be capable of learning a unified image descriptor model shared by all server nodes which embeds large images into low dimensional high level features before transmitting images to worker nodes. AMS thus dramatically reduces the communication load and enables the arduous joint training process. Based on AMS, the methods of effectively combining the images and ID features are carefully studied, and then we propose a Deep Image CTR Model. Our approach is shown to achieve significant improvements in both online and offline evaluations, and has been deployed in Taobao display advertising system serving the main traffic.
Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate
Apr 24, 2018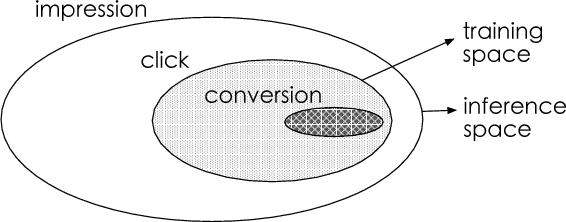

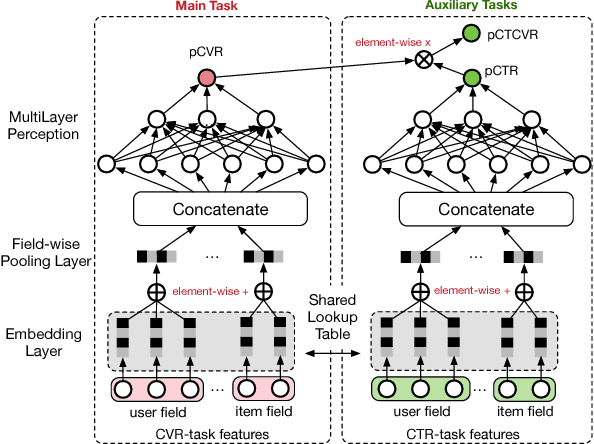
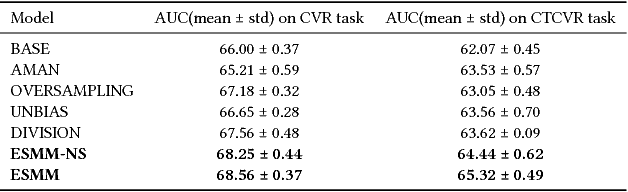
Estimating post-click conversion rate (CVR) accurately is crucial for ranking systems in industrial applications such as recommendation and advertising. Conventional CVR modeling applies popular deep learning methods and achieves state-of-the-art performance. However it encounters several task-specific problems in practice, making CVR modeling challenging. For example, conventional CVR models are trained with samples of clicked impressions while utilized to make inference on the entire space with samples of all impressions. This causes a sample selection bias problem. Besides, there exists an extreme data sparsity problem, making the model fitting rather difficult. In this paper, we model CVR in a brand-new perspective by making good use of sequential pattern of user actions, i.e., impression -> click -> conversion. The proposed Entire Space Multi-task Model (ESMM) can eliminate the two problems simultaneously by i) modeling CVR directly over the entire space, ii) employing a feature representation transfer learning strategy. Experiments on dataset gathered from Taobao's recommender system demonstrate that ESMM significantly outperforms competitive methods. We also release a sampling version of this dataset to enable future research. To the best of our knowledge, this is the first public dataset which contains samples with sequential dependence of click and conversion labels for CVR modeling.