 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDWDP: Distributed Weight Data Parallelism for High-Performance LLM Inference on NVL72
Apr 02, 2026Large language model (LLM) inference increasingly depends on multi-GPU execution, yet existing inference parallelization strategies require layer-wise inter-rank synchronization, making end-to-end performance sensitive to workload imbalance. We present DWDP (Distributed Weight Data Parallelism), an inference parallelization strategy that preserves data-parallel execution while offloading MoE weights across peer GPUs and fetching missing experts on demand. By removing collective inter-rank synchronization, DWDP allows each GPU to progress independently. We further address the practical overheads of this design with two optimizations for split-weight management and asynchronous remote-weight prefetch. Implemented in TensorRT-LLM and evaluated with DeepSeek-R1 on GB200 NVL72, DWDP improves end-to-end output TPS/GPU by 8.8% at comparable TPS/user in the 20-100 TPS/user serving range under 8K input sequence length and 1K output sequence length.
CAN: Revisiting Feature Co-Action for Click-Through Rate Prediction
Nov 11, 2020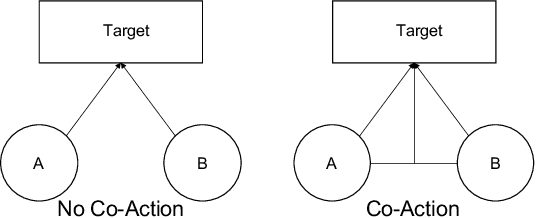
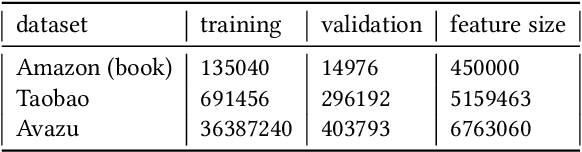
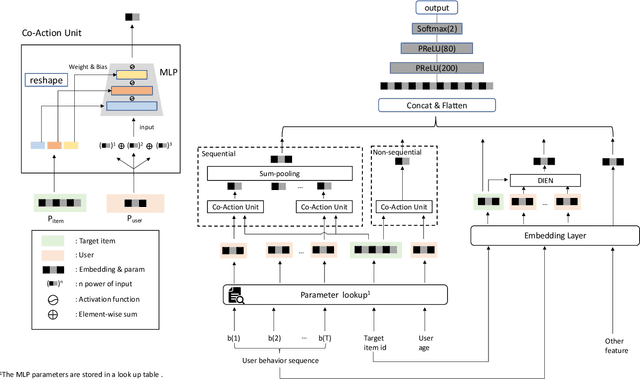
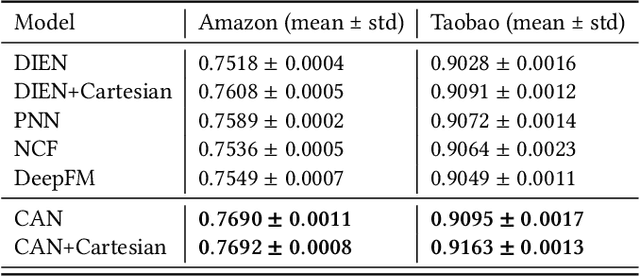
Inspired by the success of deep learning, recent industrial Click-Through Rate (CTR) prediction models have made the transition from traditional shallow approaches to deep approaches. Deep Neural Networks (DNNs) are known for its ability to learn non-linear interactions from raw feature automatically, however, the non-linear feature interaction is learned in an implicit manner. The non-linear interaction may be hard to capture and explicitly model the \textit{co-action} of raw feature is beneficial for CTR prediction. \textit{Co-action} refers to the collective effects of features toward final prediction. In this paper, we argue that current CTR models do not fully explore the potential of feature co-action. We conduct experiments and show that the effect of feature co-action is underestimated seriously. Motivated by our observation, we propose feature Co-Action Network (CAN) to explore the potential of feature co-action. The proposed model can efficiently and effectively capture the feature co-action, which improves the model performance while reduce the storage and computation consumption. Experiment results on public and industrial datasets show that CAN outperforms state-of-the-art CTR models by a large margin. Up to now, CAN has been deployed in the Alibaba display advertisement system, obtaining averaging 12\% improvement on CTR and 8\% on RPM.