 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphonomy: Universal Human Parsing via Graph Transfer Learning
Apr 09, 2019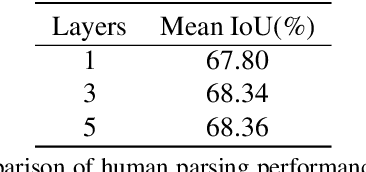



Prior highly-tuned human parsing models tend to fit towards each dataset in a specific domain or with discrepant label granularity, and can hardly be adapted to other human parsing tasks without extensive re-training. In this paper, we aim to learn a single universal human parsing model that can tackle all kinds of human parsing needs by unifying label annotations from different domains or at various levels of granularity. This poses many fundamental learning challenges, e.g. discovering underlying semantic structures among different label granularity, performing proper transfer learning across different image domains, and identifying and utilizing label redundancies across related tasks. To address these challenges, we propose a new universal human parsing agent, named "Graphonomy", which incorporates hierarchical graph transfer learning upon the conventional parsing network to encode the underlying label semantic structures and propagate relevant semantic information. In particular, Graphonomy first learns and propagates compact high-level graph representation among the labels within one dataset via Intra-Graph Reasoning, and then transfers semantic information across multiple datasets via Inter-Graph Transfer. Various graph transfer dependencies (\eg, similarity, linguistic knowledge) between different datasets are analyzed and encoded to enhance graph transfer capability. By distilling universal semantic graph representation to each specific task, Graphonomy is able to predict all levels of parsing labels in one system without piling up the complexity. Experimental results show Graphonomy effectively achieves the state-of-the-art results on three human parsing benchmarks as well as advantageous universal human parsing performance.
Regional Homogeneity: Towards Learning Transferable Universal Adversarial Perturbations Against Defenses
Apr 01, 2019

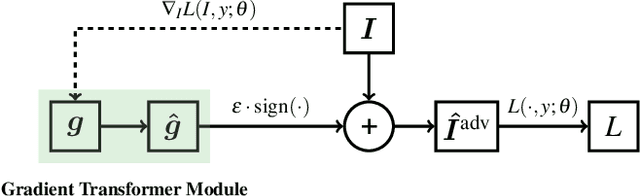
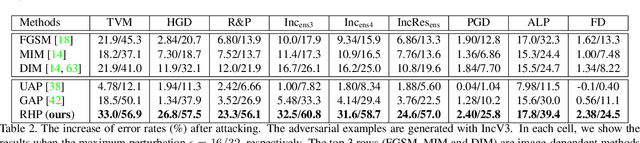
This paper focuses on learning transferable adversarial examples specifically against defense models (models to defense adversarial attacks). In particular, we show that a simple universal perturbation can fool a series of state-of-the-art defenses. Adversarial examples generated by existing attacks are generally hard to transfer to defense models. We observe the property of regional homogeneity in adversarial perturbations and suggest that the defenses are less robust to regionally homogeneous perturbations. Therefore, we propose an effective transforming paradigm and a customized gradient transformer module to transform existing perturbations into regionally homogeneous ones. Without explicitly forcing the perturbations to be universal, we observe that a well-trained gradient transformer module tends to output input-independent gradients (hence universal) benefiting from the under-fitting phenomenon. Thorough experiments demonstrate that our work significantly outperforms the prior art attacking algorithms (either image-dependent or universal ones) by an average improvement of 14.0% when attacking 9 defenses in the black-box setting. In addition to the cross-model transferability, we also verify that regionally homogeneous perturbations can well transfer across different vision tasks (attacking with the semantic segmentation task and testing on the object detection task).
DeepLens: Shallow Depth Of Field From A Single Image
Oct 18, 2018

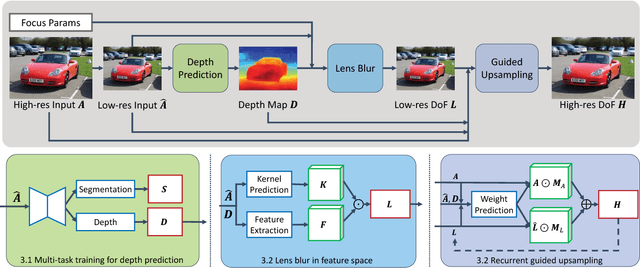
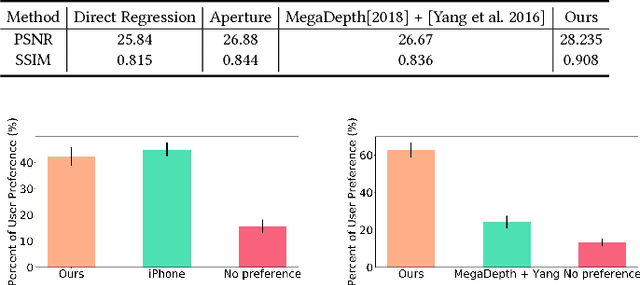
We aim to generate high resolution shallow depth-of-field (DoF) images from a single all-in-focus image with controllable focal distance and aperture size. To achieve this, we propose a novel neural network model comprised of a depth prediction module, a lens blur module, and a guided upsampling module. All modules are differentiable and are learned from data. To train our depth prediction module, we collect a dataset of 2462 RGB-D images captured by mobile phones with a dual-lens camera, and use existing segmentation datasets to improve border prediction. We further leverage a synthetic dataset with known depth to supervise the lens blur and guided upsampling modules. The effectiveness of our system and training strategies are verified in the experiments. Our method can generate high-quality shallow DoF images at high resolution, and produces significantly fewer artifacts than the baselines and existing solutions for single image shallow DoF synthesis. Compared with the iPhone portrait mode, which is a state-of-the-art shallow DoF solution based on a dual-lens depth camera, our method generates comparable results, while allowing for greater flexibility to choose focal points and aperture size, and is not limited to one capture setup.
A Modulation Module for Multi-task Learning with Applications in Image Retrieval
Sep 05, 2018
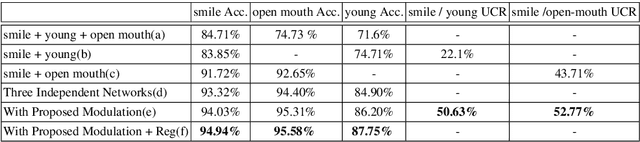

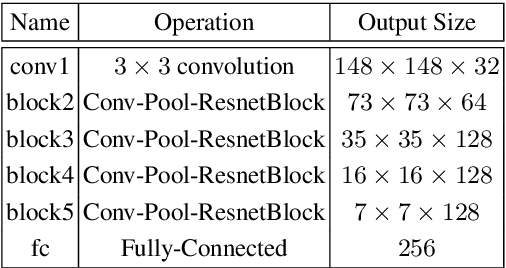
Multi-task learning has been widely adopted in many computer vision tasks to improve overall computation efficiency or boost the performance of individual tasks, under the assumption that those tasks are correlated and complementary to each other. However, the relationships between the tasks are complicated in practice, especially when the number of involved tasks scales up. When two tasks are of weak relevance, they may compete or even distract each other during joint training of shared parameters, and as a consequence undermine the learning of all the tasks. This will raise destructive interference which decreases learning efficiency of shared parameters and lead to low quality loss local optimum w.r.t. shared parameters. To address the this problem, we propose a general modulation module, which can be inserted into any convolutional neural network architecture, to encourage the coupling and feature sharing of relevant tasks while disentangling the learning of irrelevant tasks with minor parameters addition. Equipped with this module, gradient directions from different tasks can be enforced to be consistent for those shared parameters, which benefits multi-task joint training. The module is end-to-end learnable without ad-hoc design for specific tasks, and can naturally handle many tasks at the same time. We apply our approach on two retrieval tasks, face retrieval on the CelebA dataset [1] and product retrieval on the UT-Zappos50K dataset [2, 3], and demonstrate its advantage over other multi-task learning methods in both accuracy and storage efficiency.
Concept Mask: Large-Scale Segmentation from Semantic Concepts
Aug 18, 2018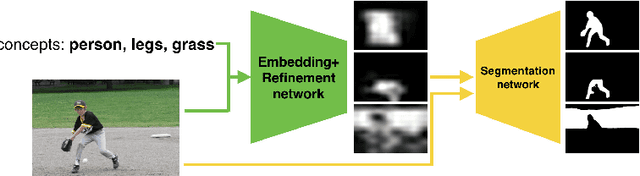


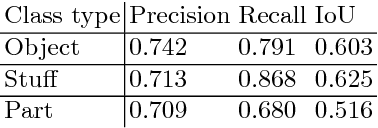
Existing works on semantic segmentation typically consider a small number of labels, ranging from tens to a few hundreds. With a large number of labels, training and evaluation of such task become extremely challenging due to correlation between labels and lack of datasets with complete annotations. We formulate semantic segmentation as a problem of image segmentation given a semantic concept, and propose a novel system which can potentially handle an unlimited number of concepts, including objects, parts, stuff, and attributes. We achieve this using a weakly and semi-supervised framework leveraging multiple datasets with different levels of supervision. We first train a deep neural network on a 6M stock image dataset with only image-level labels to learn visual-semantic embedding on 18K concepts. Then, we refine and extend the embedding network to predict an attention map, using a curated dataset with bounding box annotations on 750 concepts. Finally, we train an attention-driven class agnostic segmentation network using an 80-category fully annotated dataset. We perform extensive experiments to validate that the proposed system performs competitively to the state of the art on fully supervised concepts, and is capable of producing accurate segmentations for weakly learned and unseen concepts.
Progressive Attention Networks for Visual Attribute Prediction
Aug 06, 2018
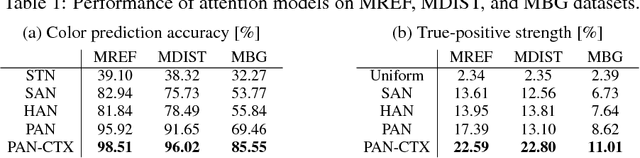
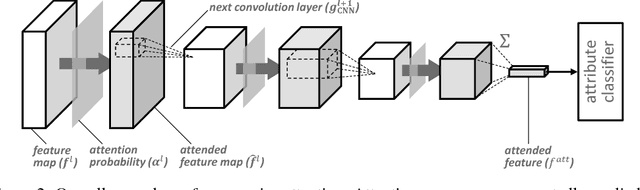

We propose a novel attention model that can accurately attends to target objects of various scales and shapes in images. The model is trained to gradually suppress irrelevant regions in an input image via a progressive attentive process over multiple layers of a convolutional neural network. The attentive process in each layer determines whether to pass or block features at certain spatial locations for use in the subsequent layers. The proposed progressive attention mechanism works well especially when combined with hard attention. We further employ local contexts to incorporate neighborhood features of each location and estimate a better attention probability map. The experiments on synthetic and real datasets show that the proposed attention networks outperform traditional attention methods in visual attribute prediction tasks.
Free-Form Image Inpainting with Gated Convolution
Jun 10, 2018

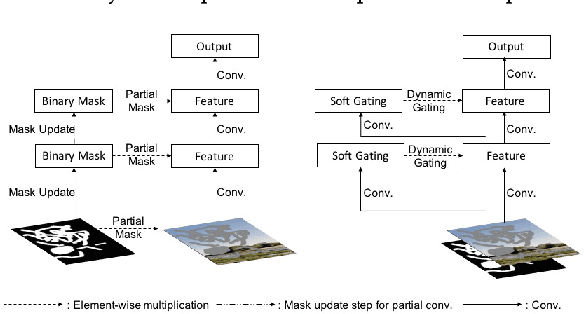

We present a novel deep learning based image inpainting system to complete images with free-form masks and inputs. The system is based on gated convolutions learned from millions of images without additional labelling efforts. The proposed gated convolution solves the issue of vanilla convolution that treats all input pixels as valid ones, generalizes partial convolution by providing a learnable dynamic feature selection mechanism for each channel at each spatial location across all layers. Moreover, as free-form masks may appear anywhere in images with any shapes, global and local GANs designed for a single rectangular mask are not suitable. To this end, we also present a novel GAN loss, named SN-PatchGAN, by applying spectral-normalized discriminators on dense image patches. It is simple in formulation, fast and stable in training. Results on automatic image inpainting and user-guided extension demonstrate that our system generates higher-quality and more flexible results than previous methods. We show that our system helps users quickly remove distracting objects, modify image layouts, clear watermarks, edit faces and interactively create novel objects in images. Furthermore, visualization of learned feature representations reveals the effectiveness of gated convolution and provides an interpretation of how the proposed neural network fills in missing regions. More high-resolution results and video materials are available at http://jiahuiyu.com/deepfill2
Towards Interpretable Face Recognition
May 02, 2018
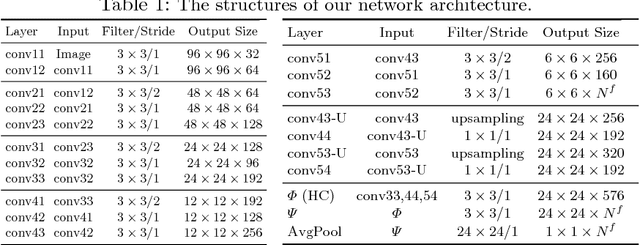
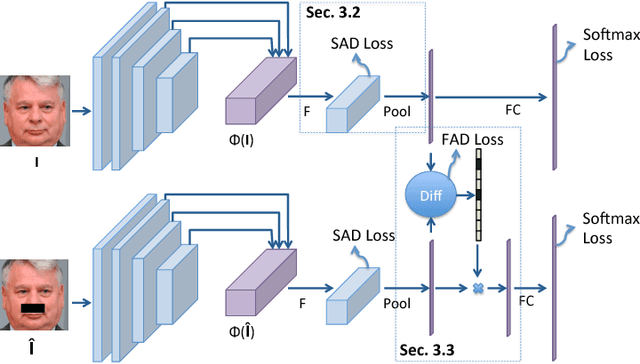
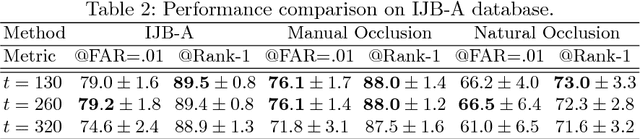
Deep CNNs have been pushing the frontier of visual recognition over past years. Besides recognition accuracy, strong demands in understanding deep CNNs in the research community motivate developments of tools to dissect pre-trained models to visualize how they make predictions. Recent works further push the interpretability in the network learning stage to learn more meaningful representations. In this work, focusing on a specific area of visual recognition, we report our efforts towards interpretable face recognition. We propose a spatial activation diversity loss to learn more structured face representations. By leveraging the structure, we further design a feature activation diversity loss to push the interpretable representations to be discriminative and robust to occlusions. We demonstrate on three face recognition benchmarks that our proposed method is able to improve face recognition accuracy with easily interpretable face representations.
Look into Person: Joint Body Parsing & Pose Estimation Network and A New Benchmark
Apr 05, 2018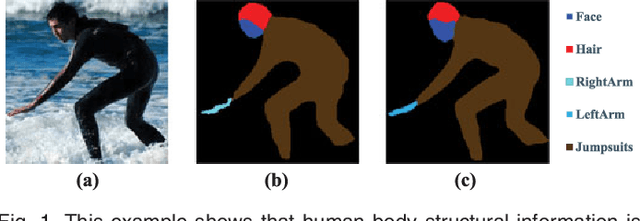

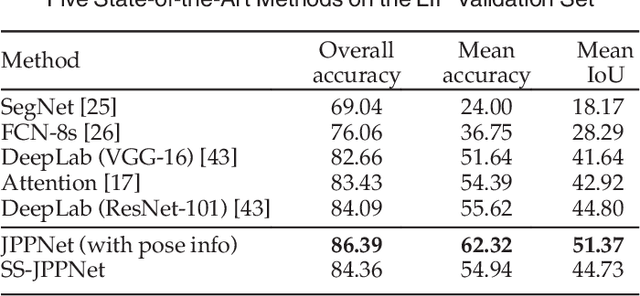
Human parsing and pose estimation have recently received considerable interest due to their substantial application potentials. However, the existing datasets have limited numbers of images and annotations and lack a variety of human appearances and coverage of challenging cases in unconstrained environments. In this paper, we introduce a new benchmark named "Look into Person (LIP)" that provides a significant advancement in terms of scalability, diversity, and difficulty, which are crucial for future developments in human-centric analysis. This comprehensive dataset contains over 50,000 elaborately annotated images with 19 semantic part labels and 16 body joints, which are captured from a broad range of viewpoints, occlusions, and background complexities. Using these rich annotations, we perform detailed analyses of the leading human parsing and pose estimation approaches, thereby obtaining insights into the successes and failures of these methods. To further explore and take advantage of the semantic correlation of these two tasks, we propose a novel joint human parsing and pose estimation network to explore efficient context modeling, which can simultaneously predict parsing and pose with extremely high quality. Furthermore, we simplify the network to solve human parsing by exploring a novel self-supervised structure-sensitive learning approach, which imposes human pose structures into the parsing results without resorting to extra supervision. The dataset, code and models are available at http://www.sysu-hcp.net/lip/.
MAttNet: Modular Attention Network for Referring Expression Comprehension
Mar 27, 2018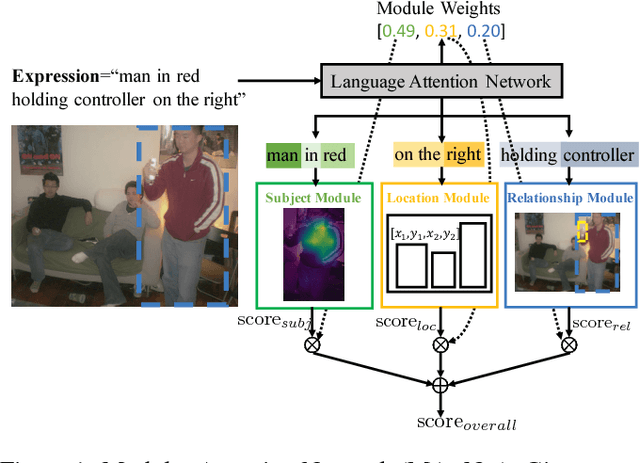
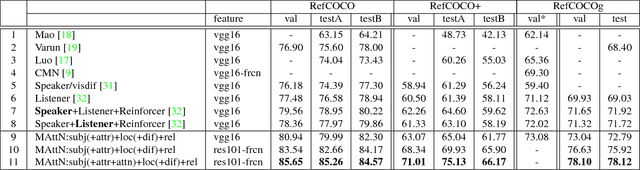
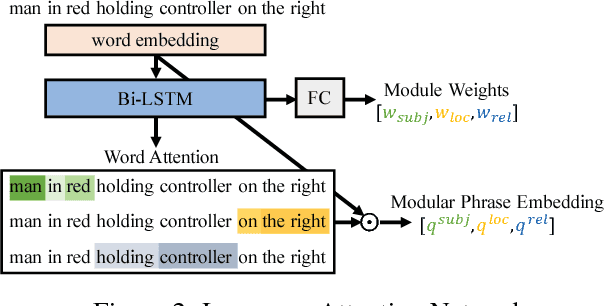
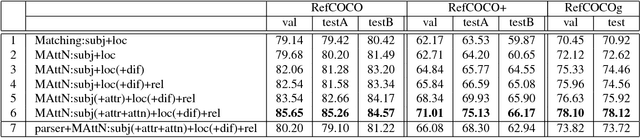
In this paper, we address referring expression comprehension: localizing an image region described by a natural language expression. While most recent work treats expressions as a single unit, we propose to decompose them into three modular components related to subject appearance, location, and relationship to other objects. This allows us to flexibly adapt to expressions containing different types of information in an end-to-end framework. In our model, which we call the Modular Attention Network (MAttNet), two types of attention are utilized: language-based attention that learns the module weights as well as the word/phrase attention that each module should focus on; and visual attention that allows the subject and relationship modules to focus on relevant image components. Module weights combine scores from all three modules dynamically to output an overall score. Experiments show that MAttNet outperforms previous state-of-art methods by a large margin on both bounding-box-level and pixel-level comprehension tasks. Demo and code are provided.