 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Continuous CRFs as Sequential Deep Networks for Monocular Depth Estimation
Apr 07, 2017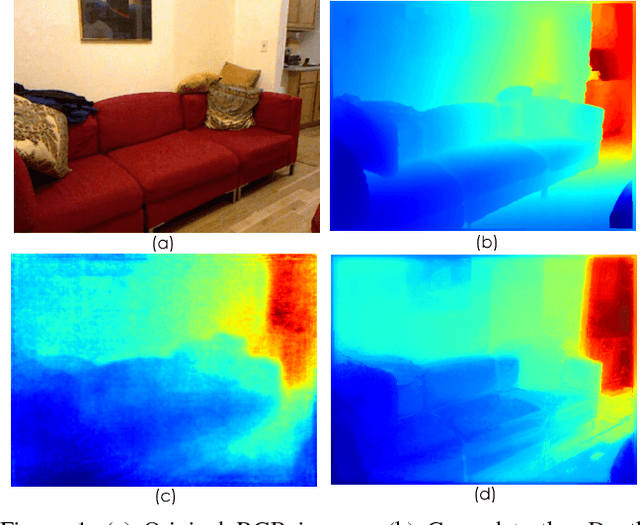
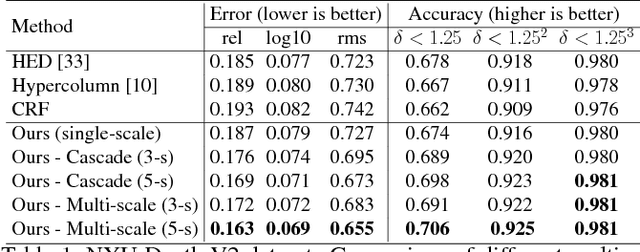
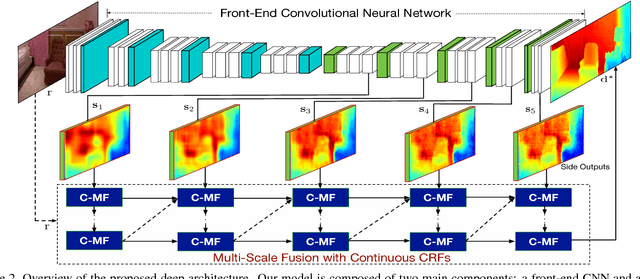
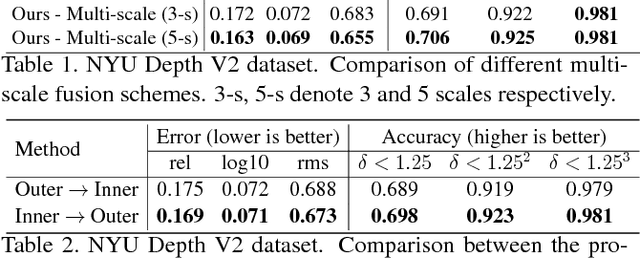
This paper addresses the problem of depth estimation from a single still image. Inspired by recent works on multi- scale convolutional neural networks (CNN), we propose a deep model which fuses complementary information derived from multiple CNN side outputs. Different from previous methods, the integration is obtained by means of continuous Conditional Random Fields (CRFs). In particular, we propose two different variations, one based on a cascade of multiple CRFs, the other on a unified graphical model. By designing a novel CNN implementation of mean-field updates for continuous CRFs, we show that both proposed models can be regarded as sequential deep networks and that training can be performed end-to-end. Through extensive experimental evaluation we demonstrate the effective- ness of the proposed approach and establish new state of the art results on publicly available datasets.
Joint Detection and Identification Feature Learning for Person Search
Apr 06, 2017
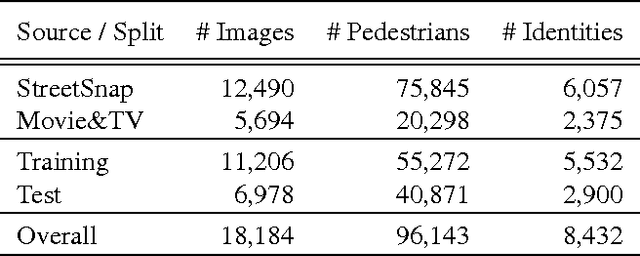
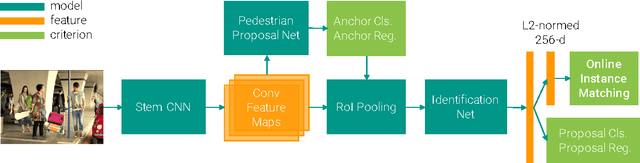
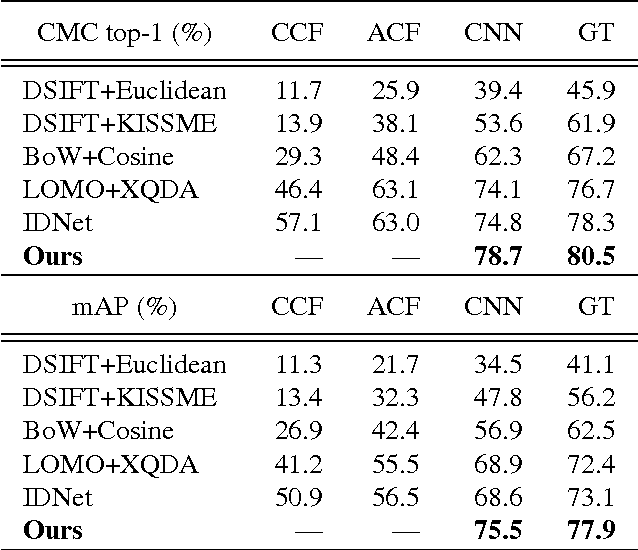
Existing person re-identification benchmarks and methods mainly focus on matching cropped pedestrian images between queries and candidates. However, it is different from real-world scenarios where the annotations of pedestrian bounding boxes are unavailable and the target person needs to be searched from a gallery of whole scene images. To close the gap, we propose a new deep learning framework for person search. Instead of breaking it down into two separate tasks---pedestrian detection and person re-identification, we jointly handle both aspects in a single convolutional neural network. An Online Instance Matching (OIM) loss function is proposed to train the network effectively, which is scalable to datasets with numerous identities. To validate our approach, we collect and annotate a large-scale benchmark dataset for person search. It contains 18,184 images, 8,432 identities, and 96,143 pedestrian bounding boxes. Experiments show that our framework outperforms other separate approaches, and the proposed OIM loss function converges much faster and better than the conventional Softmax loss.
Learning Deep Features via Congenerous Cosine Loss for Person Recognition
Mar 31, 2017
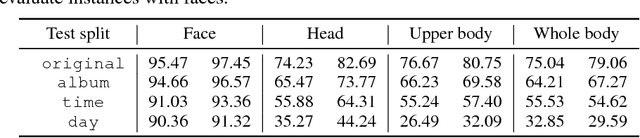
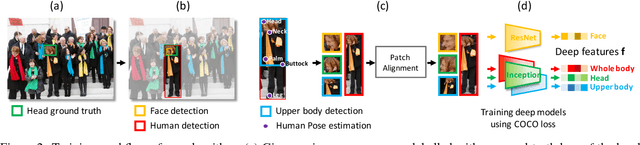
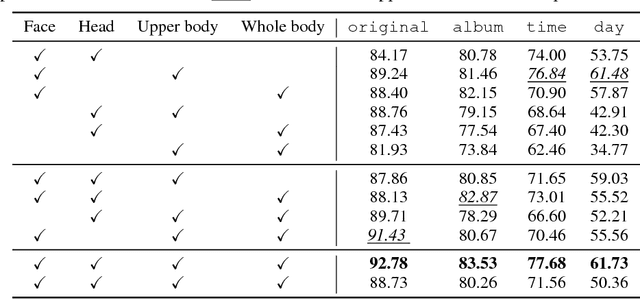
Person recognition aims at recognizing the same identity across time and space with complicated scenes and similar appearance. In this paper, we propose a novel method to address this task by training a network to obtain robust and representative features. The intuition is that we directly compare and optimize the cosine distance between two features - enlarging inter-class distinction as well as alleviating inner-class variance. We propose a congenerous cosine loss by minimizing the cosine distance between samples and their cluster centroid in a cooperative way. Such a design reduces the complexity and could be implemented via softmax with normalized inputs. Our method also differs from previous work in person recognition that we do not conduct a second training on the test subset. The identity of a person is determined by measuring the similarity from several body regions in the reference set. Experimental results show that the proposed approach achieves better classification accuracy against previous state-of-the-arts.
Learning Spatial Regularization with Image-level Supervisions for Multi-label Image Classification
Mar 31, 2017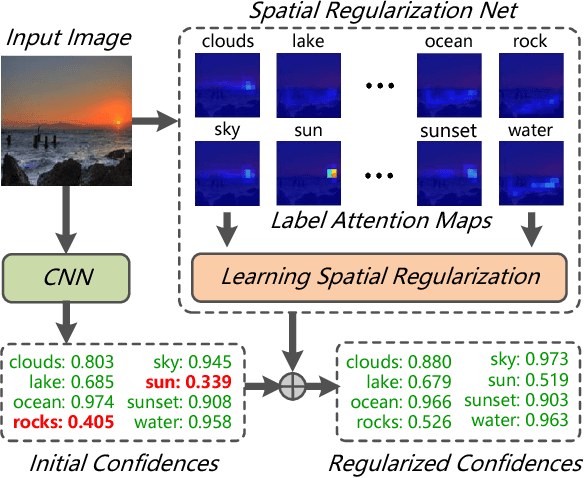
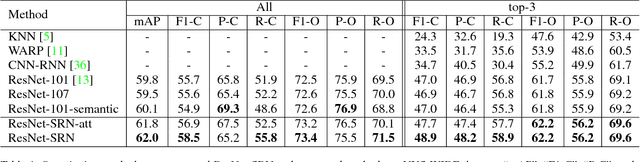
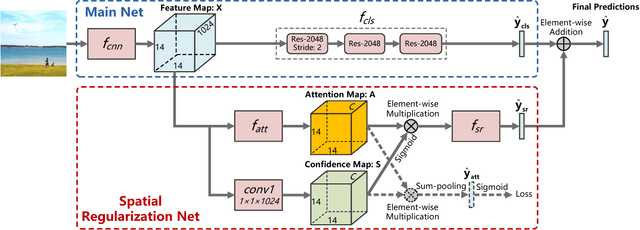
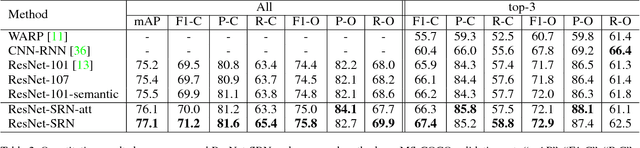
Multi-label image classification is a fundamental but challenging task in computer vision. Great progress has been achieved by exploiting semantic relations between labels in recent years. However, conventional approaches are unable to model the underlying spatial relations between labels in multi-label images, because spatial annotations of the labels are generally not provided. In this paper, we propose a unified deep neural network that exploits both semantic and spatial relations between labels with only image-level supervisions. Given a multi-label image, our proposed Spatial Regularization Network (SRN) generates attention maps for all labels and captures the underlying relations between them via learnable convolutions. By aggregating the regularized classification results with original results by a ResNet-101 network, the classification performance can be consistently improved. The whole deep neural network is trained end-to-end with only image-level annotations, thus requires no additional efforts on image annotations. Extensive evaluations on 3 public datasets with different types of labels show that our approach significantly outperforms state-of-the-arts and has strong generalization capability. Analysis of the learned SRN model demonstrates that it can effectively capture both semantic and spatial relations of labels for improving classification performance.
Person Search with Natural Language Description
Mar 30, 2017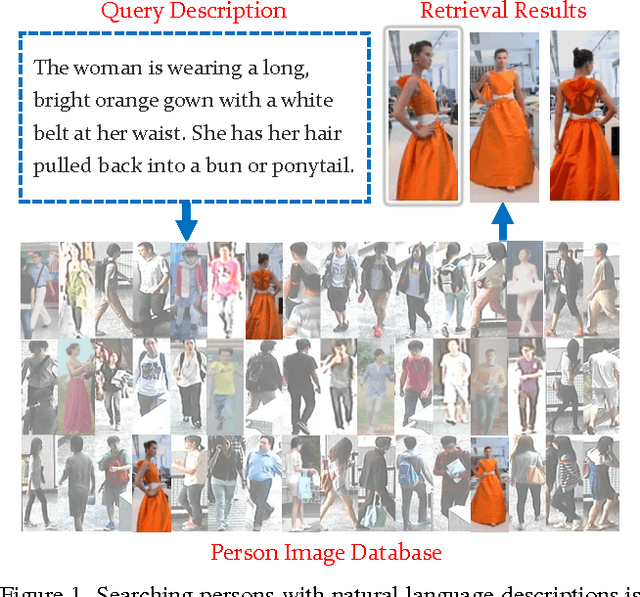
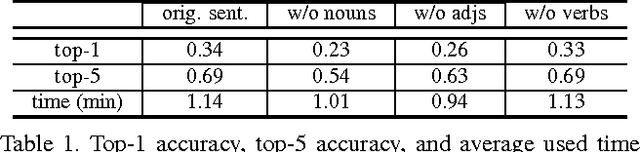


Searching persons in large-scale image databases with the query of natural language description has important applications in video surveillance. Existing methods mainly focused on searching persons with image-based or attribute-based queries, which have major limitations for a practical usage. In this paper, we study the problem of person search with natural language description. Given the textual description of a person, the algorithm of the person search is required to rank all the samples in the person database then retrieve the most relevant sample corresponding to the queried description. Since there is no person dataset or benchmark with textual description available, we collect a large-scale person description dataset with detailed natural language annotations and person samples from various sources, termed as CUHK Person Description Dataset (CUHK-PEDES). A wide range of possible models and baselines have been evaluated and compared on the person search benchmark. An Recurrent Neural Network with Gated Neural Attention mechanism (GNA-RNN) is proposed to establish the state-of-the art performance on person search.
Multi-Context Attention for Human Pose Estimation
Feb 24, 2017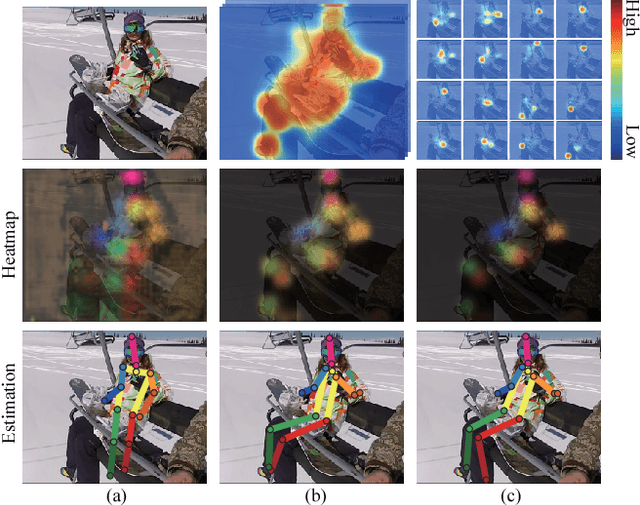
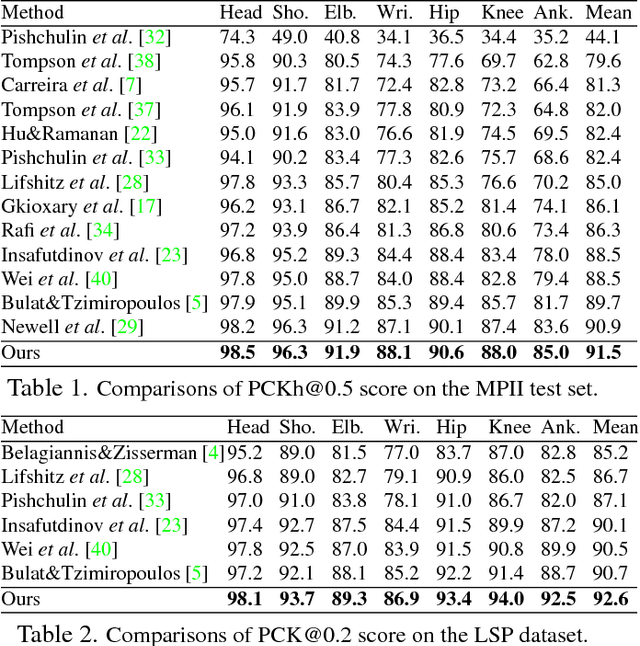
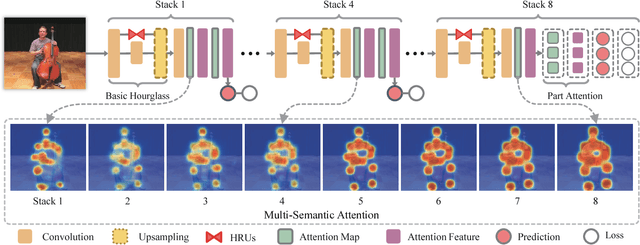
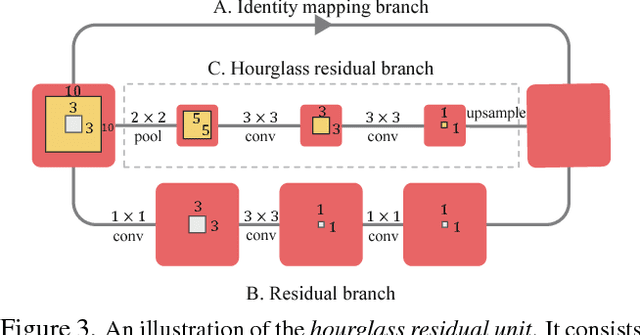
In this paper, we propose to incorporate convolutional neural networks with a multi-context attention mechanism into an end-to-end framework for human pose estimation. We adopt stacked hourglass networks to generate attention maps from features at multiple resolutions with various semantics. The Conditional Random Field (CRF) is utilized to model the correlations among neighboring regions in the attention map. We further combine the holistic attention model, which focuses on the global consistency of the full human body, and the body part attention model, which focuses on the detailed description for different body parts. Hence our model has the ability to focus on different granularity from local salient regions to global semantic-consistent spaces. Additionally, we design novel Hourglass Residual Units (HRUs) to increase the receptive field of the network. These units are extensions of residual units with a side branch incorporating filters with larger receptive fields, hence features with various scales are learned and combined within the HRUs. The effectiveness of the proposed multi-context attention mechanism and the hourglass residual units is evaluated on two widely used human pose estimation benchmarks. Our approach outperforms all existing methods on both benchmarks over all the body parts.
Learning Chained Deep Features and Classifiers for Cascade in Object Detection
Feb 23, 2017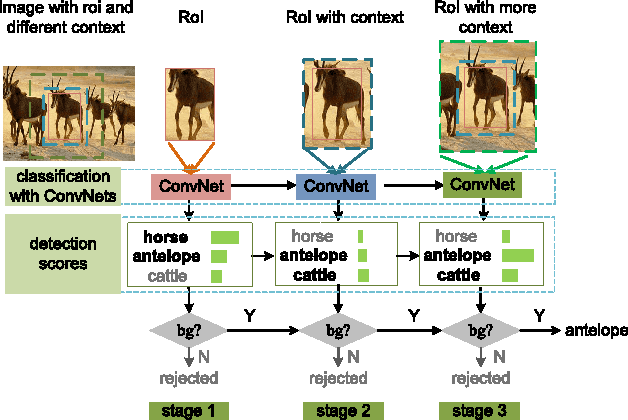
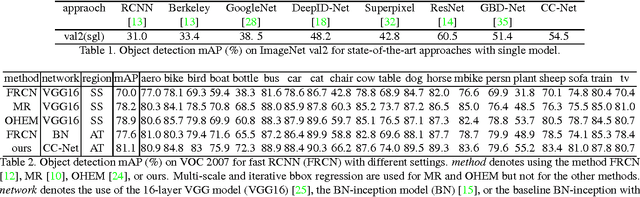
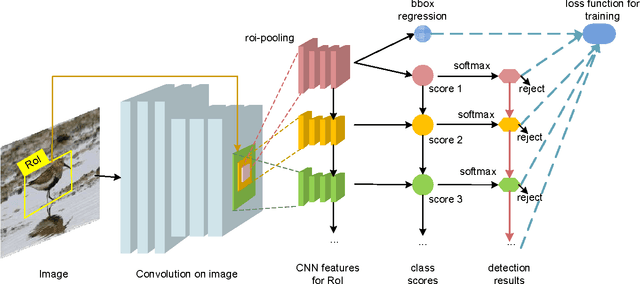
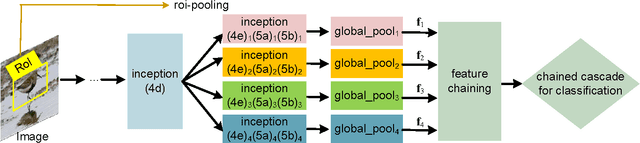
Cascade is a widely used approach that rejects obvious negative samples at early stages for learning better classifier and faster inference. This paper presents chained cascade network (CC-Net). In this CC-Net, the cascaded classifier at a stage is aided by the classification scores in previous stages. Feature chaining is further proposed so that the feature learning for the current cascade stage uses the features in previous stages as the prior information. The chained ConvNet features and classifiers of multiple stages are jointly learned in an end-to-end network. In this way, features and classifiers at latter stages handle more difficult samples with the help of features and classifiers in previous stages. It yields consistent boost in detection performance on benchmarks like PASCAL VOC 2007 and ImageNet. Combined with better region proposal, CC-Net leads to state-of-the-art result of 81.1% mAP on PASCAL VOC 2007.
Progressively Diffused Networks for Semantic Image Segmentation
Feb 20, 2017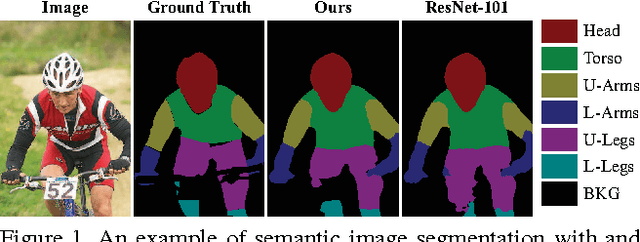
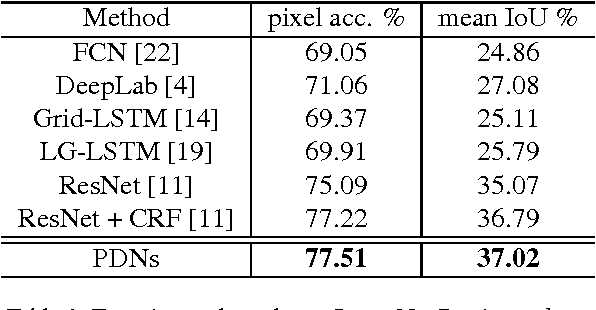
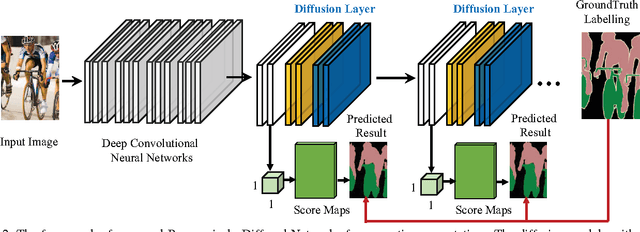
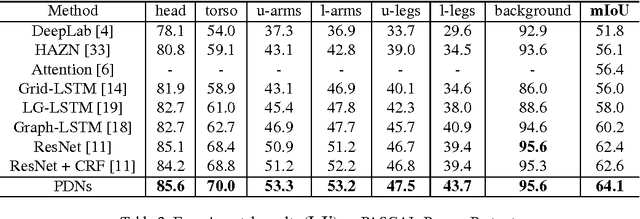
This paper introduces Progressively Diffused Networks (PDNs) for unifying multi-scale context modeling with deep feature learning, by taking semantic image segmentation as an exemplar application. Prior neural networks, such as ResNet, tend to enhance representational power by increasing the depth of architectures and driving the training objective across layers. However, we argue that spatial dependencies in different layers, which generally represent the rich contexts among data elements, are also critical to building deep and discriminative representations. To this end, our PDNs enables to progressively broadcast information over the learned feature maps by inserting a stack of information diffusion layers, each of which exploits multi-dimensional convolutional LSTMs (Long-Short-Term Memory Structures). In each LSTM unit, a special type of atrous filters are designed to capture the short range and long range dependencies from various neighbors to a certain site of the feature map and pass the accumulated information to the next layer. From the extensive experiments on semantic image segmentation benchmarks (e.g., ImageNet Parsing, PASCAL VOC2012 and PASCAL-Part), our framework demonstrates the effectiveness to substantially improve the performances over the popular existing neural network models, and achieves state-of-the-art on ImageNet Parsing for large scale semantic segmentation.
Zoom Out-and-In Network with Recursive Training for Object Proposal
Feb 19, 2017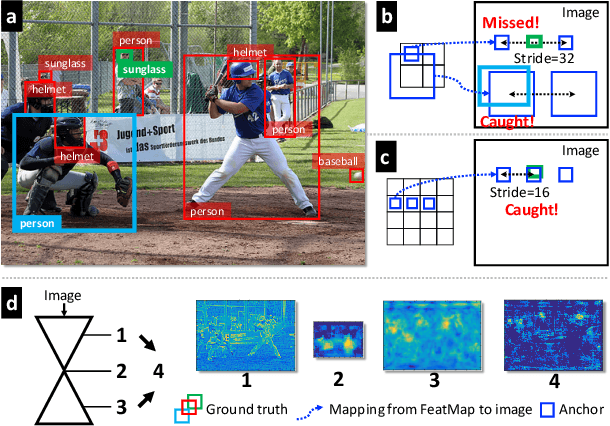
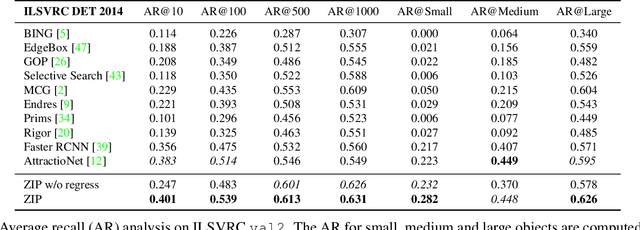
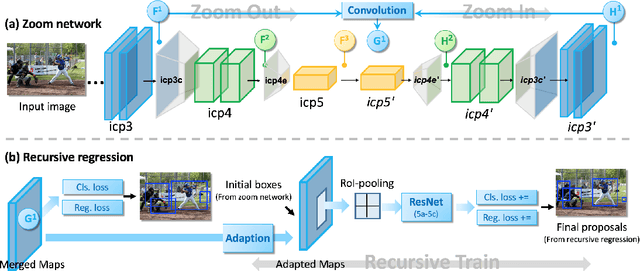
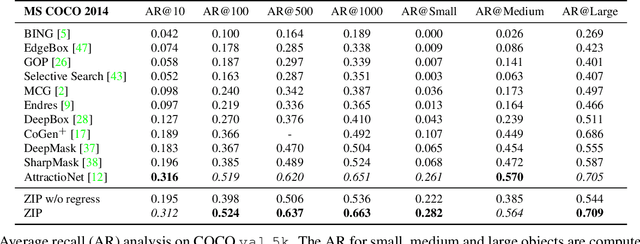
In this paper, we propose a zoom-out-and-in network for generating object proposals. We utilize different resolutions of feature maps in the network to detect object instances of various sizes. Specifically, we divide the anchor candidates into three clusters based on the scale size and place them on feature maps of distinct strides to detect small, medium and large objects, respectively. Deeper feature maps contain region-level semantics which can help shallow counterparts to identify small objects. Therefore we design a zoom-in sub-network to increase the resolution of high level features via a deconvolution operation. The high-level features with high resolution are then combined and merged with low-level features to detect objects. Furthermore, we devise a recursive training pipeline to consecutively regress region proposals at the training stage in order to match the iterative regression at the testing stage. We demonstrate the effectiveness of the proposed method on ILSVRC DET and MS COCO datasets, where our algorithm performs better than the state-of-the-arts in various evaluation metrics. It also increases average precision by around 2% in the detection system.
Automatic Discoveries of Physical and Semantic Concepts via Association Priors of Neuron Groups
Jan 12, 2017
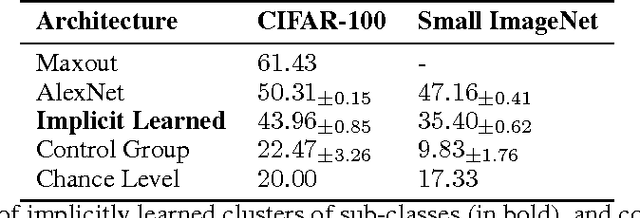
The recent successful deep neural networks are largely trained in a supervised manner. It {\it associates} complex patterns of input samples with neurons in the last layer, which form representations of {\it concepts}. In spite of their successes, the properties of complex patterns associated a learned concept remain elusive. In this work, by analyzing how neurons are associated with concepts in supervised networks, we hypothesize that with proper priors to regulate learning, neural networks can automatically associate neurons in the intermediate layers with concepts that are aligned with real world concepts, when trained only with labels that associate concepts with top level neurons, which is a plausible way for unsupervised learning. We develop a prior to verify the hypothesis and experimentally find the proposed prior help neural networks automatically learn both basic physical concepts at the lower layers, e.g., rotation of filters, and highly semantic concepts at the higher layers, e.g., fine-grained categories of an entry-level category.