 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination Begins Where Saliency Drops
Jan 28, 2026Recent studies have examined attention dynamics in large vision-language models (LVLMs) to detect hallucinations. However, existing approaches remain limited in reliably distinguishing hallucinated from factually grounded outputs, as they rely solely on forward-pass attention patterns and neglect gradient-based signals that reveal how token influence propagates through the network. To bridge this gap, we introduce LVLMs-Saliency, a gradient-aware diagnostic framework that quantifies the visual grounding strength of each output token by fusing attention weights with their input gradients. Our analysis uncovers a decisive pattern: hallucinations frequently arise when preceding output tokens exhibit low saliency toward the prediction of the next token, signaling a breakdown in contextual memory retention. Leveraging this insight, we propose a dual-mechanism inference-time framework to mitigate hallucinations: (1) Saliency-Guided Rejection Sampling (SGRS), which dynamically filters candidate tokens during autoregressive decoding by rejecting those whose saliency falls below a context-adaptive threshold, thereby preventing coherence-breaking tokens from entering the output sequence; and (2) Local Coherence Reinforcement (LocoRE), a lightweight, plug-and-play module that strengthens attention from the current token to its most recent predecessors, actively counteracting the contextual forgetting behavior identified by LVLMs-Saliency. Extensive experiments across multiple LVLMs demonstrate that our method significantly reduces hallucination rates while preserving fluency and task performance, offering a robust and interpretable solution for enhancing model reliability. Code is available at: https://github.com/zhangbaijin/LVLMs-Saliency
Context Tokens are Anchors: Understanding the Repetition Curse in dMLLMs from an Information Flow Perspective
Jan 28, 2026Recent diffusion-based Multimodal Large Language Models (dMLLMs) suffer from high inference latency and therefore rely on caching techniques to accelerate decoding. However, the application of cache mechanisms often introduces undesirable repetitive text generation, a phenomenon we term the \textbf{Repeat Curse}. To better investigate underlying mechanism behind this issue, we analyze repetition generation through the lens of information flow. Our work reveals three key findings: (1) context tokens aggregate semantic information as anchors and guide the final predictions; (2) as information propagates across layers, the entropy of context tokens converges in deeper layers, reflecting the model's growing prediction certainty; (3) Repetition is typically linked to disruptions in the information flow of context tokens and to the inability of their entropy to converge in deeper layers. Based on these insights, we present \textbf{CoTA}, a plug-and-play method for mitigating repetition. CoTA enhances the attention of context tokens to preserve intrinsic information flow patterns, while introducing a penalty term to the confidence score during decoding to avoid outputs driven by uncertain context tokens. With extensive experiments, CoTA demonstrates significant effectiveness in alleviating repetition and achieves consistent performance improvements on general tasks. Code is available at https://github.com/ErikZ719/CoTA
Inference-time Physics Alignment of Video Generative Models with Latent World Models
Jan 15, 2026State-of-the-art video generative models produce promising visual content yet often violate basic physics principles, limiting their utility. While some attribute this deficiency to insufficient physics understanding from pre-training, we find that the shortfall in physics plausibility also stems from suboptimal inference strategies. We therefore introduce WMReward and treat improving physics plausibility of video generation as an inference-time alignment problem. In particular, we leverage the strong physics prior of a latent world model (here, VJEPA-2) as a reward to search and steer multiple candidate denoising trajectories, enabling scaling test-time compute for better generation performance. Empirically, our approach substantially improves physics plausibility across image-conditioned, multiframe-conditioned, and text-conditioned generation settings, with validation from human preference study. Notably, in the ICCV 2025 Perception Test PhysicsIQ Challenge, we achieve a final score of 62.64%, winning first place and outperforming the previous state of the art by 7.42%. Our work demonstrates the viability of using latent world models to improve physics plausibility of video generation, beyond this specific instantiation or parameterization.
Diversity Recommendation via Causal Deconfounding of Co-purchase Relations and Counterfactual Exposure
Dec 19, 2025


Beyond user-item modeling, item-to-item relationships are increasingly used to enhance recommendation. However, common methods largely rely on co-occurrence, making them prone to item popularity bias and user attributes, which degrades embedding quality and performance. Meanwhile, although diversity is acknowledged as a key aspect of recommendation quality, existing research offers limited attention to it, with a notable lack of causal perspectives and theoretical grounding. To address these challenges, we propose Cadence: Diversity Recommendation via Causal Deconfounding of Co-purchase Relations and Counterfactual Exposure - a plug-and-play framework built upon LightGCN as the backbone, primarily designed to enhance recommendation diversity while preserving accuracy. First, we compute the Unbiased Asymmetric Co-purchase Relationship (UACR) between items - excluding item popularity and user attributes - to construct a deconfounded directed item graph, with an aggregation mechanism to refine embeddings. Second, we leverage UACR to identify diverse categories of items that exhibit strong causal relevance to a user's interacted items but have not yet been engaged with. We then simulate their behavior under high-exposure scenarios, thereby significantly enhancing recommendation diversity while preserving relevance. Extensive experiments on real-world datasets demonstrate that our method consistently outperforms state-of-the-art diversity models in both diversity and accuracy, and further validates its effectiveness, transferability, and efficiency over baselines.
D$^{3}$ToM: Decider-Guided Dynamic Token Merging for Accelerating Diffusion MLLMs
Nov 15, 2025Diffusion-based multimodal large language models (Diffusion MLLMs) have recently demonstrated impressive non-autoregressive generative capabilities across vision-and-language tasks. However, Diffusion MLLMs exhibit substantially slower inference than autoregressive models: Each denoising step employs full bidirectional self-attention over the entire sequence, resulting in cubic decoding complexity that becomes computationally impractical with thousands of visual tokens. To address this challenge, we propose D$^{3}$ToM, a Decider-guided dynamic token merging method that dynamically merges redundant visual tokens at different denoising steps to accelerate inference in Diffusion MLLMs. At each denoising step, D$^{3}$ToM uses decider tokens-the tokens generated in the previous denoising step-to build an importance map over all visual tokens. Then it maintains a proportion of the most salient tokens and merges the remainder through similarity-based aggregation. This plug-and-play module integrates into a single transformer layer, physically shortening the visual token sequence for all subsequent layers without altering model parameters. Moreover, D$^{3}$ToM employs a merge ratio that dynamically varies with each denoising step, aligns with the native decoding process of Diffusion MLLMs, achieving superior performance under equivalent computational budgets. Extensive experiments show that D$^{3}$ToM accelerates inference while preserving competitive performance. The code is released at https://github.com/bcmi/D3ToM-Diffusion-MLLM.
Remember Me: Bridging the Long-Range Gap in LVLMs with Three-Step Inference-Only Decay Resilience Strategies
Nov 13, 2025Large Vision-Language Models (LVLMs) have achieved impressive performance across a wide range of multimodal tasks. However, they still face critical challenges in modeling long-range dependencies under the usage of Rotary Positional Encoding (ROPE). Although it can facilitate precise modeling of token positions, it induces progressive attention decay as token distance increases, especially with progressive attention decay over distant token pairs, which severely impairs the model's ability to remember global context. To alleviate this issue, we propose inference-only Three-step Decay Resilience Strategies (T-DRS), comprising (1) Semantic-Driven DRS (SD-DRS), amplifying semantically meaningful but distant signals via content-aware residuals, (2) Distance-aware Control DRS (DC-DRS), which can purify attention by smoothly modulating weights based on positional distances, suppressing noise while preserving locality, and (3) re-Reinforce Distant DRS (reRD-DRS), consolidating the remaining informative remote dependencies to maintain global coherence. Together, the T-DRS recover suppressed long-range token pairs without harming local inductive biases. Extensive experiments on Vision Question Answering (VQA) benchmarks demonstrate that T-DRS can consistently improve performance in a training-free manner. The code can be accessed in https://github.com/labixiaoq-qq/Remember-me
CMAMRNet: A Contextual Mask-Aware Network Enhancing Mural Restoration Through Comprehensive Mask Guidance
Aug 10, 2025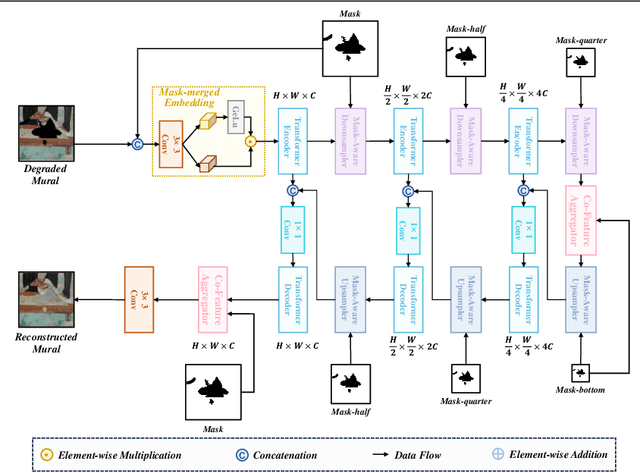
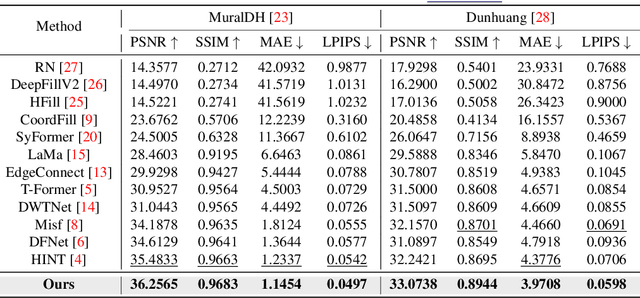
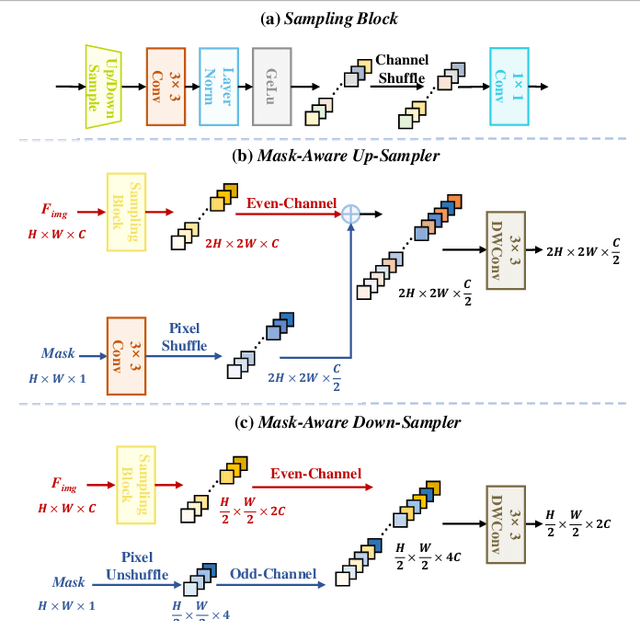
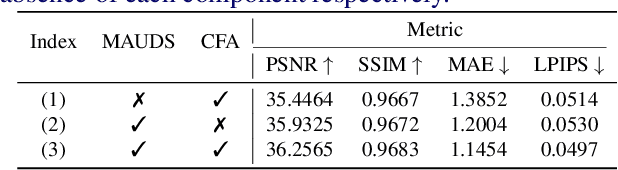
Murals, as invaluable cultural artifacts, face continuous deterioration from environmental factors and human activities. Digital restoration of murals faces unique challenges due to their complex degradation patterns and the critical need to preserve artistic authenticity. Existing learning-based methods struggle with maintaining consistent mask guidance throughout their networks, leading to insufficient focus on damaged regions and compromised restoration quality. We propose CMAMRNet, a Contextual Mask-Aware Mural Restoration Network that addresses these limitations through comprehensive mask guidance and multi-scale feature extraction. Our framework introduces two key components: (1) the Mask-Aware Up/Down-Sampler (MAUDS), which ensures consistent mask sensitivity across resolution scales through dedicated channel-wise feature selection and mask-guided feature fusion; and (2) the Co-Feature Aggregator (CFA), operating at both the highest and lowest resolutions to extract complementary features for capturing fine textures and global structures in degraded regions. Experimental results on benchmark datasets demonstrate that CMAMRNet outperforms state-of-the-art methods, effectively preserving both structural integrity and artistic details in restored murals. The code is available at~\href{https://github.com/CXH-Research/CMAMRNet}{https://github.com/CXH-Research/CMAMRNet}.
CulturalFrames: Assessing Cultural Expectation Alignment in Text-to-Image Models and Evaluation Metrics
Jun 10, 2025The increasing ubiquity of text-to-image (T2I) models as tools for visual content generation raises concerns about their ability to accurately represent diverse cultural contexts. In this work, we present the first study to systematically quantify the alignment of T2I models and evaluation metrics with respect to both explicit as well as implicit cultural expectations. To this end, we introduce CulturalFrames, a novel benchmark designed for rigorous human evaluation of cultural representation in visual generations. Spanning 10 countries and 5 socio-cultural domains, CulturalFrames comprises 983 prompts, 3637 corresponding images generated by 4 state-of-the-art T2I models, and over 10k detailed human annotations. We find that T2I models not only fail to meet the more challenging implicit expectations but also the less challenging explicit expectations. Across models and countries, cultural expectations are missed an average of 44% of the time. Among these failures, explicit expectations are missed at a surprisingly high average rate of 68%, while implicit expectation failures are also significant, averaging 49%. Furthermore, we demonstrate that existing T2I evaluation metrics correlate poorly with human judgments of cultural alignment, irrespective of their internal reasoning. Collectively, our findings expose critical gaps, providing actionable directions for developing more culturally informed T2I models and evaluation methodologies.
Bias Analysis in Unconditional Image Generative Models
Jun 10, 2025



The widespread adoption of generative AI models has raised growing concerns about representational harm and potential discriminatory outcomes. Yet, despite growing literature on this topic, the mechanisms by which bias emerges - especially in unconditional generation - remain disentangled. We define the bias of an attribute as the difference between the probability of its presence in the observed distribution and its expected proportion in an ideal reference distribution. In our analysis, we train a set of unconditional image generative models and adopt a commonly used bias evaluation framework to study bias shift between training and generated distributions. Our experiments reveal that the detected attribute shifts are small. We find that the attribute shifts are sensitive to the attribute classifier used to label generated images in the evaluation framework, particularly when its decision boundaries fall in high-density regions. Our empirical analysis indicates that this classifier sensitivity is often observed in attributes values that lie on a spectrum, as opposed to exhibiting a binary nature. This highlights the need for more representative labeling practices, understanding the shortcomings through greater scrutiny of evaluation frameworks, and recognizing the socially complex nature of attributes when evaluating bias.
AdaToken-3D: Dynamic Spatial Gating for Efficient 3D Large Multimodal-Models Reasoning
May 19, 2025Large Multimodal Models (LMMs) have become a pivotal research focus in deep learning, demonstrating remarkable capabilities in 3D scene understanding. However, current 3D LMMs employing thousands of spatial tokens for multimodal reasoning suffer from critical inefficiencies: excessive computational overhead and redundant information flows. Unlike 2D VLMs processing single images, 3D LMMs exhibit inherent architectural redundancy due to the heterogeneous mechanisms between spatial tokens and visual tokens. To address this challenge, we propose AdaToken-3D, an adaptive spatial token optimization framework that dynamically prunes redundant tokens through spatial contribution analysis. Our method automatically tailors pruning strategies to different 3D LMM architectures by quantifying token-level information flows via attention pattern mining. Extensive experiments on LLaVA-3D (a 7B parameter 3D-LMM) demonstrate that AdaToken-3D achieves 21\% faster inference speed and 63\% FLOPs reduction while maintaining original task accuracy. Beyond efficiency gains, this work systematically investigates redundancy patterns in multimodal spatial information flows through quantitative token interaction analysis. Our findings reveal that over 60\% of spatial tokens contribute minimally ($<$5\%) to the final predictions, establishing theoretical foundations for efficient 3D multimodal learning.