 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCULTURESCORE: Evaluating Cultural Faithfulness in Video Generation Models
Jun 05, 2026As video generation models like Veo 3.1 and LTX-2 advance, their ability to accurately represent diverse global cultures remains a critical yet understudied frontier. Current metrics, such as VideoScore, only measure visual quality but offer no mechanism for assessing cultural faithfulness. Consequently, a model that replaces a Namaste with a handshake receives the same score as one that generates the gesture correctly. We propose CultureScore, a compositional evaluation framework that decomposes cultural faithfulness into three granular dimensions: Identity (who is represented), Context (culturally localized background), and Behavior (normative gestures and interactions). We operationalize this framework through an evaluation suite spanning 10 countries, yielding 6,180 generated videos across three state-of-the-art models. Our evaluation reveals that no current model achieves culturally faithful video generation: the best-performing model reaches only 56.8\% overall CultureScore, with Behavior the most challenging dimension, which remains below 52\% across all models. Furthermore, human preference rankings align directionally with CultureScore but are inverted relative to VideoScore; the highest-scoring model on visual quality was ranked last by annotators, underscoring that cultural faithfulness is an essential criterion for equitable video generation.
Discovering Failure Modes in Vision-Language Models using RL
Apr 06, 2026Vision-language Models (VLMs), despite achieving strong performance on multimodal benchmarks, often misinterpret straightforward visual concepts that humans identify effortlessly, such as counting, spatial reasoning, and viewpoint understanding. Previous studies manually identified these weaknesses and found that they often stem from deficits in specific skills. However, such manual efforts are costly, unscalable, and subject to human bias, which often overlooks subtle details in favor of salient objects, resulting in an incomplete understanding of a model's vulnerabilities. To address these limitations, we propose a Reinforcement Learning (RL)-based framework to automatically discover the failure modes or blind spots of any candidate VLM on a given data distribution without human intervention. Our framework trains a questioner agent that adaptively generates queries based on the candidate VLM's responses to elicit incorrect answers. Our approach increases question complexity by focusing on fine-grained visual details and distinct skill compositions as training progresses, consequently identifying 36 novel failure modes in which VLMs struggle. We demonstrate the broad applicability of our framework by showcasing its generalizability across various model combinations.
CUA-Suite: Massive Human-annotated Video Demonstrations for Computer-Use Agents
Mar 25, 2026Computer-use agents (CUAs) hold great promise for automating complex desktop workflows, yet progress toward general-purpose agents is bottlenecked by the scarcity of continuous, high-quality human demonstration videos. Recent work emphasizes that continuous video, not sparse screenshots, is the critical missing ingredient for scaling these agents. However, the largest existing open dataset, ScaleCUA, contains only 2 million screenshots, equating to less than 20 hours of video. To address this bottleneck, we introduce CUA-Suite, a large-scale ecosystem of expert video demonstrations and dense annotations for professional desktop computer-use agents. At its core is VideoCUA, which provides approximately 10,000 human-demonstrated tasks across 87 diverse applications with continuous 30 fps screen recordings, kinematic cursor traces, and multi-layerfed reasoning annotations, totaling approximately 55 hours and 6 million frames of expert video. Unlike sparse datasets that capture only final click coordinates, these continuous video streams preserve the full temporal dynamics of human interaction, forming a superset of information that can be losslessly transformed into the formats required by existing agent frameworks. CUA-Suite further provides two complementary resources: UI-Vision, a rigorous benchmark for evaluating grounding and planning capabilities in CUAs, and GroundCUA, a large-scale grounding dataset with 56K annotated screenshots and over 3.6 million UI element annotations. Preliminary evaluation reveals that current foundation action models struggle substantially with professional desktop applications (~60% task failure rate). Beyond evaluation, CUA-Suite's rich multimodal corpus supports emerging research directions including generalist screen parsing, continuous spatial control, video-based reward modeling, and visual world models. All data and models are publicly released.
EnterpriseOps-Gym: Environments and Evaluations for Stateful Agentic Planning and Tool Use in Enterprise Settings
Mar 13, 2026Large language models are shifting from passive information providers to active agents intended for complex workflows. However, their deployment as reliable AI workers in enterprise is stalled by benchmarks that fail to capture the intricacies of professional environments, specifically, the need for long-horizon planning amidst persistent state changes and strict access protocols. In this work, we introduce EnterpriseOps-Gym, a benchmark designed to evaluate agentic planning in realistic enterprise settings. Specifically, EnterpriseOps-Gym features a containerized sandbox with 164 database tables and 512 functional tools to mimic real-world search friction. Within this environment, agents are evaluated on 1,150 expert-curated tasks across eight mission-critical verticals (including Customer Service, HR, and IT). Our evaluation of 14 frontier models reveals critical limitations in state-of-the-art models: the top-performing Claude Opus 4.5 achieves only 37.4% success. Further analysis shows that providing oracle human plans improves performance by 14-35 percentage points, pinpointing strategic reasoning as the primary bottleneck. Additionally, agents frequently fail to refuse infeasible tasks (best model achieves 53.9%), leading to unintended and potentially harmful side effects. Our findings underscore that current agents are not yet ready for autonomous enterprise deployment. More broadly, EnterpriseOps-Gym provides a concrete testbed to advance the robustness of agentic planning in professional workflows.
LatentLens: Revealing Highly Interpretable Visual Tokens in LLMs
Jan 31, 2026Transforming a large language model (LLM) into a Vision-Language Model (VLM) can be achieved by mapping the visual tokens from a vision encoder into the embedding space of an LLM. Intriguingly, this mapping can be as simple as a shallow MLP transformation. To understand why LLMs can so readily process visual tokens, we need interpretability methods that reveal what is encoded in the visual token representations at every layer of LLM processing. In this work, we introduce LatentLens, a novel approach for mapping latent representations to descriptions in natural language. LatentLens works by encoding a large text corpus and storing contextualized token representations for each token in that corpus. Visual token representations are then compared to their contextualized textual representations, with the top-k nearest neighbor representations providing descriptions of the visual token. We evaluate this method on 10 different VLMs, showing that commonly used methods, such as LogitLens, substantially underestimate the interpretability of visual tokens. With LatentLens instead, the majority of visual tokens are interpretable across all studied models and all layers. Qualitatively, we show that the descriptions produced by LatentLens are semantically meaningful and provide more fine-grained interpretations for humans compared to individual tokens. More broadly, our findings contribute new evidence on the alignment between vision and language representations, opening up new directions for analyzing latent representations.
Grammar Search for Multi-Agent Systems
Dec 16, 2025


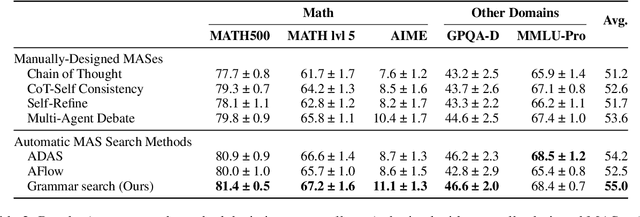
Automatic search for Multi-Agent Systems has recently emerged as a key focus in agentic AI research. Several prior approaches have relied on LLM-based free-form search over the code space. In this work, we propose a more structured framework that explores the same space through a fixed set of simple, composable components. We show that, despite lacking the generative flexibility of LLMs during the candidate generation stage, our method outperforms prior approaches on four out of five benchmarks across two domains: mathematics and question answering. Furthermore, our method offers additional advantages, including a more cost-efficient search process and the generation of modular, interpretable multi-agent systems with simpler logic.
Grounding Computer Use Agents on Human Demonstrations
Nov 10, 2025



Building reliable computer-use agents requires grounding: accurately connecting natural language instructions to the correct on-screen elements. While large datasets exist for web and mobile interactions, high-quality resources for desktop environments are limited. To address this gap, we introduce GroundCUA, a large-scale desktop grounding dataset built from expert human demonstrations. It covers 87 applications across 12 categories and includes 56K screenshots, with every on-screen element carefully annotated for a total of over 3.56M human-verified annotations. From these demonstrations, we generate diverse instructions that capture a wide range of real-world tasks, providing high-quality data for model training. Using GroundCUA, we develop the GroundNext family of models that map instructions to their target UI elements. At both 3B and 7B scales, GroundNext achieves state-of-the-art results across five benchmarks using supervised fine-tuning, while requiring less than one-tenth the training data of prior work. Reinforcement learning post-training further improves performance, and when evaluated in an agentic setting on the OSWorld benchmark using o3 as planner, GroundNext attains comparable or superior results to models trained with substantially more data,. These results demonstrate the critical role of high-quality, expert-driven datasets in advancing general-purpose computer-use agents.
Value Drifts: Tracing Value Alignment During LLM Post-Training
Oct 30, 2025As LLMs occupy an increasingly important role in society, they are more and more confronted with questions that require them not only to draw on their general knowledge but also to align with certain human value systems. Therefore, studying the alignment of LLMs with human values has become a crucial field of inquiry. Prior work, however, mostly focuses on evaluating the alignment of fully trained models, overlooking the training dynamics by which models learn to express human values. In this work, we investigate how and at which stage value alignment arises during the course of a model's post-training. Our analysis disentangles the effects of post-training algorithms and datasets, measuring both the magnitude and time of value drifts during training. Experimenting with Llama-3 and Qwen-3 models of different sizes and popular supervised fine-tuning (SFT) and preference optimization datasets and algorithms, we find that the SFT phase generally establishes a model's values, and subsequent preference optimization rarely re-aligns these values. Furthermore, using a synthetic preference dataset that enables controlled manipulation of values, we find that different preference optimization algorithms lead to different value alignment outcomes, even when preference data is held constant. Our findings provide actionable insights into how values are learned during post-training and help to inform data curation, as well as the selection of models and algorithms for preference optimization to improve model alignment to human values.
CulturalFrames: Assessing Cultural Expectation Alignment in Text-to-Image Models and Evaluation Metrics
Jun 10, 2025The increasing ubiquity of text-to-image (T2I) models as tools for visual content generation raises concerns about their ability to accurately represent diverse cultural contexts. In this work, we present the first study to systematically quantify the alignment of T2I models and evaluation metrics with respect to both explicit as well as implicit cultural expectations. To this end, we introduce CulturalFrames, a novel benchmark designed for rigorous human evaluation of cultural representation in visual generations. Spanning 10 countries and 5 socio-cultural domains, CulturalFrames comprises 983 prompts, 3637 corresponding images generated by 4 state-of-the-art T2I models, and over 10k detailed human annotations. We find that T2I models not only fail to meet the more challenging implicit expectations but also the less challenging explicit expectations. Across models and countries, cultural expectations are missed an average of 44% of the time. Among these failures, explicit expectations are missed at a surprisingly high average rate of 68%, while implicit expectation failures are also significant, averaging 49%. Furthermore, we demonstrate that existing T2I evaluation metrics correlate poorly with human judgments of cultural alignment, irrespective of their internal reasoning. Collectively, our findings expose critical gaps, providing actionable directions for developing more culturally informed T2I models and evaluation methodologies.
UI-Vision: A Desktop-centric GUI Benchmark for Visual Perception and Interaction
Mar 19, 2025Autonomous agents that navigate Graphical User Interfaces (GUIs) to automate tasks like document editing and file management can greatly enhance computer workflows. While existing research focuses on online settings, desktop environments, critical for many professional and everyday tasks, remain underexplored due to data collection challenges and licensing issues. We introduce UI-Vision, the first comprehensive, license-permissive benchmark for offline, fine-grained evaluation of computer use agents in real-world desktop environments. Unlike online benchmarks, UI-Vision provides: (i) dense, high-quality annotations of human demonstrations, including bounding boxes, UI labels, and action trajectories (clicks, drags, and keyboard inputs) across 83 software applications, and (ii) three fine-to-coarse grained tasks-Element Grounding, Layout Grounding, and Action Prediction-with well-defined metrics to rigorously evaluate agents' performance in desktop environments. Our evaluation reveals critical limitations in state-of-the-art models like UI-TARS-72B, including issues with understanding professional software, spatial reasoning, and complex actions like drag-and-drop. These findings highlight the challenges in developing fully autonomous computer use agents. By releasing UI-Vision as open-source, we aim to advance the development of more capable agents for real-world desktop tasks.