 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Speculative Decoding for Llama at Scale: Challenges and Solutions
Aug 11, 2025Speculative decoding is a standard method for accelerating the inference speed of large language models. However, scaling it for production environments poses several engineering challenges, including efficiently implementing different operations (e.g., tree attention and multi-round speculative decoding) on GPU. In this paper, we detail the training and inference optimization techniques that we have implemented to enable EAGLE-based speculative decoding at a production scale for Llama models. With these changes, we achieve a new state-of-the-art inference latency for Llama models. For example, Llama4 Maverick decodes at a speed of about 4 ms per token (with a batch size of one) on 8 NVIDIA H100 GPUs, which is 10% faster than the previously best known method. Furthermore, for EAGLE-based speculative decoding, our optimizations enable us to achieve a speed-up for large batch sizes between 1.4x and 2.0x at production scale.
Align-for-Fusion: Harmonizing Triple Preferences via Dual-oriented Diffusion for Cross-domain Sequential Recommendation
Aug 07, 2025Personalized sequential recommendation aims to predict appropriate items for users based on their behavioral sequences. To alleviate data sparsity and interest drift issues, conventional approaches typically incorporate auxiliary behaviors from other domains via cross-domain transition. However, existing cross-domain sequential recommendation (CDSR) methods often follow an align-then-fusion paradigm that performs representation-level alignment across multiple domains and combines them mechanically for recommendation, overlooking the fine-grained fusion of domain-specific preferences. Inspired by recent advances in diffusion models (DMs) for distribution matching, we propose an align-for-fusion framework for CDSR to harmonize triple preferences via dual-oriented DMs, termed HorizonRec. Specifically, we investigate the uncertainty injection of DMs and identify stochastic noise as a key source of instability in existing DM-based recommenders. To address this, we introduce a mixed-conditioned distribution retrieval strategy that leverages distributions retrieved from users' authentic behavioral logic as semantic bridges across domains, enabling consistent multi-domain preference modeling. Furthermore, we propose a dual-oriented preference diffusion method to suppress potential noise and emphasize target-relevant interests during multi-domain user representation fusion. Extensive experiments on four CDSR datasets from two distinct platforms demonstrate the effectiveness and robustness of HorizonRec in fine-grained triple-domain preference fusion.
Fast and Simplex: 2-Simplicial Attention in Triton
Jul 03, 2025Recent work has shown that training loss scales as a power law with both model size and the number of tokens, and that achieving compute-optimal models requires scaling model size and token count together. However, these scaling laws assume an infinite supply of data and apply primarily in compute-bound settings. As modern large language models increasingly rely on massive internet-scale datasets, the assumption that they are compute-bound is becoming less valid. This shift highlights the need for architectures that prioritize token efficiency. In this work, we investigate the use of the 2-simplicial Transformer, an architecture that generalizes standard dot-product attention to trilinear functions through an efficient Triton kernel implementation. We demonstrate that the 2-simplicial Transformer achieves better token efficiency than standard Transformers: for a fixed token budget, similarly sized models outperform their dot-product counterparts on tasks involving mathematics, coding, reasoning, and logic. We quantify these gains by demonstrating that $2$-simplicial attention changes the exponent in the scaling laws for knowledge and reasoning tasks compared to dot product attention.
LeanPO: Lean Preference Optimization for Likelihood Alignment in Video-LLMs
Jun 05, 2025Most Video Large Language Models (Video-LLMs) adopt preference alignment techniques, e.g., DPO~\citep{rafailov2024dpo}, to optimize the reward margin between a winning response ($y_w$) and a losing response ($y_l$). However, the likelihood displacement observed in DPO indicates that both $\log \pi_\theta (y_w\mid x)$ and $\log \pi_\theta (y_l\mid x) $ often decrease during training, inadvertently boosting the probabilities of non-target responses. In this paper, we systematically revisit this phenomenon from LLMs to Video-LLMs, showing that it intensifies when dealing with the redundant complexity of video content. To alleviate the impact of this phenomenon, we propose \emph{Lean Preference Optimization} (LeanPO), a reference-free approach that reformulates the implicit reward as the average likelihood of the response with respect to the policy model. A key component of LeanPO is the reward-trustworthiness correlated self-generated preference data pipeline, which carefully infuses relevant prior knowledge into the model while continuously refining the preference data via self-reflection. This allows the policy model to obtain high-quality paired data and accurately estimate the newly defined reward, thus mitigating the unintended drop. In addition, we introduce a dynamic label smoothing strategy that mitigates the impact of noise in responses from diverse video content, preventing the model from overfitting to spurious details. Extensive experiments demonstrate that LeanPO significantly enhances the performance of state-of-the-art Video-LLMs, consistently boosting baselines of varying capacities with minimal additional training overhead. Moreover, LeanPO offers a simple yet effective solution for aligning Video-LLM preferences with human trustworthiness, paving the way toward the reliable and efficient Video-LLMs.
Proximal Algorithm Unrolling: Flexible and Efficient Reconstruction Networks for Single-Pixel Imaging
May 29, 2025Deep-unrolling and plug-and-play (PnP) approaches have become the de-facto standard solvers for single-pixel imaging (SPI) inverse problem. PnP approaches, a class of iterative algorithms where regularization is implicitly performed by an off-the-shelf deep denoiser, are flexible for varying compression ratios (CRs) but are limited in reconstruction accuracy and speed. Conversely, unrolling approaches, a class of multi-stage neural networks where a truncated iterative optimization process is transformed into an end-to-end trainable network, typically achieve better accuracy with faster inference but require fine-tuning or even retraining when CR changes. In this paper, we address the challenge of integrating the strengths of both classes of solvers. To this end, we design an efficient deep image restorer (DIR) for the unrolling of HQS (half quadratic splitting) and ADMM (alternating direction method of multipliers). More importantly, a general proximal trajectory (PT) loss function is proposed to train HQS/ADMM-unrolling networks such that learned DIR approximates the proximal operator of an ideal explicit restoration regularizer. Extensive experiments demonstrate that, the resulting proximal unrolling networks can not only flexibly handle varying CRs with a single model like PnP algorithms, but also outperform previous CR-specific unrolling networks in both reconstruction accuracy and speed. Source codes and models are available at https://github.com/pwangcs/ProxUnroll.
ProphetDWM: A Driving World Model for Rolling Out Future Actions and Videos
May 24, 2025Real-world driving requires people to observe the current environment, anticipate the future, and make appropriate driving decisions. This requirement is aligned well with the capabilities of world models, which understand the environment and predict the future. However, recent world models in autonomous driving are built explicitly, where they could predict the future by controllable driving video generation. We argue that driving world models should have two additional abilities: action control and action prediction. Following this line, previous methods are limited because they predict the video requires given actions of the same length as the video and ignore the dynamical action laws. To address these issues, we propose ProphetDWM, a novel end-to-end driving world model that jointly predicts future videos and actions. Our world model has an action module to learn latent action from the present to the future period by giving the action sequence and observations. And a diffusion-model-based transition module to learn the state distribution. The model is jointly trained by learning latent actions given finite states and predicting action and video. The joint learning connects the action dynamics and states and enables long-term future prediction. We evaluate our method in video generation and action prediction tasks on the Nuscenes dataset. Compared to the state-of-the-art methods, our method achieves the best video consistency and best action prediction accuracy, while also enabling high-quality long-term video and action generation.
Multi-SpatialMLLM: Multi-Frame Spatial Understanding with Multi-Modal Large Language Models
May 22, 2025

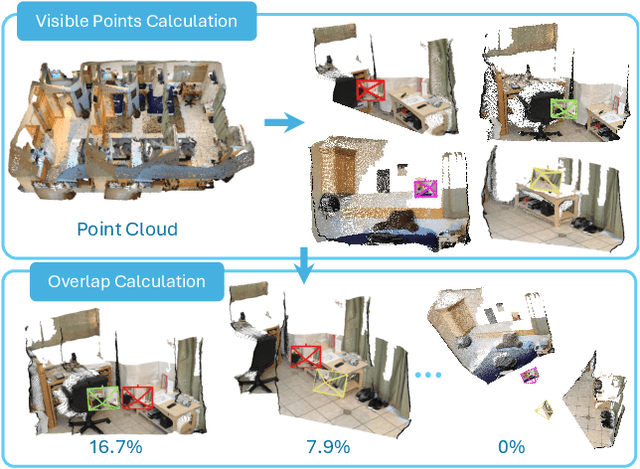
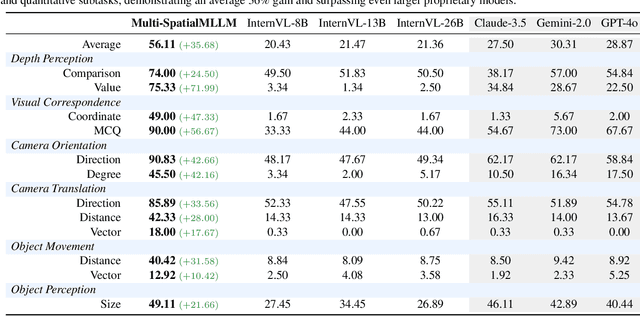
Multi-modal large language models (MLLMs) have rapidly advanced in visual tasks, yet their spatial understanding remains limited to single images, leaving them ill-suited for robotics and other real-world applications that require multi-frame reasoning. In this paper, we propose a framework to equip MLLMs with robust multi-frame spatial understanding by integrating depth perception, visual correspondence, and dynamic perception. Central to our approach is the MultiSPA dataset, a novel, large-scale collection of more than 27 million samples spanning diverse 3D and 4D scenes. Alongside MultiSPA, we introduce a comprehensive benchmark that tests a wide spectrum of spatial tasks under uniform metrics. Our resulting model, Multi-SpatialMLLM, achieves significant gains over baselines and proprietary systems, demonstrating scalable, generalizable multi-frame reasoning. We further observe multi-task benefits and early indications of emergent capabilities in challenging scenarios, and showcase how our model can serve as a multi-frame reward annotator for robotics.
Supporting renewable energy planning and operation with data-driven high-resolution ensemble weather forecast
May 07, 2025The planning and operation of renewable energy, especially wind power, depend crucially on accurate, timely, and high-resolution weather information. Coarse-grid global numerical weather forecasts are typically downscaled to meet these requirements, introducing challenges of scale inconsistency, process representation error, computation cost, and entanglement of distinct uncertainty sources from chaoticity, model bias, and large-scale forcing. We address these challenges by learning the climatological distribution of a target wind farm using its high-resolution numerical weather simulations. An optimal combination of this learned high-resolution climatological prior with coarse-grid large scale forecasts yields highly accurate, fine-grained, full-variable, large ensemble of weather pattern forecasts. Using observed meteorological records and wind turbine power outputs as references, the proposed methodology verifies advantageously compared to existing numerical/statistical forecasting-downscaling pipelines, regarding either deterministic/probabilistic skills or economic gains. Moreover, a 100-member, 10-day forecast with spatial resolution of 1 km and output frequency of 15 min takes < 1 hour on a moderate-end GPU, as contrast to $\mathcal{O}(10^3)$ CPU hours for conventional numerical simulation. By drastically reducing computational costs while maintaining accuracy, our method paves the way for more efficient and reliable renewable energy planning and operation.
PR-Attack: Coordinated Prompt-RAG Attacks on Retrieval-Augmented Generation in Large Language Models via Bilevel Optimization
Apr 10, 2025Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of applications, e.g., medical question-answering, mathematical sciences, and code generation. However, they also exhibit inherent limitations, such as outdated knowledge and susceptibility to hallucinations. Retrieval-Augmented Generation (RAG) has emerged as a promising paradigm to address these issues, but it also introduces new vulnerabilities. Recent efforts have focused on the security of RAG-based LLMs, yet existing attack methods face three critical challenges: (1) their effectiveness declines sharply when only a limited number of poisoned texts can be injected into the knowledge database, (2) they lack sufficient stealth, as the attacks are often detectable by anomaly detection systems, which compromises their effectiveness, and (3) they rely on heuristic approaches to generate poisoned texts, lacking formal optimization frameworks and theoretic guarantees, which limits their effectiveness and applicability. To address these issues, we propose coordinated Prompt-RAG attack (PR-attack), a novel optimization-driven attack that introduces a small number of poisoned texts into the knowledge database while embedding a backdoor trigger within the prompt. When activated, the trigger causes the LLM to generate pre-designed responses to targeted queries, while maintaining normal behavior in other contexts. This ensures both high effectiveness and stealth. We formulate the attack generation process as a bilevel optimization problem leveraging a principled optimization framework to develop optimal poisoned texts and triggers. Extensive experiments across diverse LLMs and datasets demonstrate the effectiveness of PR-Attack, achieving a high attack success rate even with a limited number of poisoned texts and significantly improved stealth compared to existing methods.
Learning Radiance Fields from a Single Snapshot Compressive Image
Dec 27, 2024In this paper, we explore the potential of Snapshot Compressive Imaging (SCI) technique for recovering the underlying 3D scene structure from a single temporal compressed image. SCI is a cost-effective method that enables the recording of high-dimensional data, such as hyperspectral or temporal information, into a single image using low-cost 2D imaging sensors. To achieve this, a series of specially designed 2D masks are usually employed, reducing storage and transmission requirements and offering potential privacy protection. Inspired by this, we take one step further to recover the encoded 3D scene information leveraging powerful 3D scene representation capabilities of neural radiance fields (NeRF). Specifically, we propose SCINeRF, in which we formulate the physical imaging process of SCI as part of the training of NeRF, allowing us to exploit its impressive performance in capturing complex scene structures. In addition, we further integrate the popular 3D Gaussian Splatting (3DGS) framework and propose SCISplat to improve 3D scene reconstruction quality and training/rendering speed by explicitly optimizing point clouds into 3D Gaussian representations. To assess the effectiveness of our method, we conduct extensive evaluations using both synthetic data and real data captured by our SCI system. Experimental results demonstrate that our proposed approach surpasses the state-of-the-art methods in terms of image reconstruction and novel view synthesis. Moreover, our method also exhibits the ability to render high frame-rate multi-view consistent images in real time by leveraging SCI and the rendering capabilities of 3DGS. Codes will be available at: https://github.com/WU- CVGL/SCISplat.