 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyramid R-CNN: Towards Better Performance and Adaptability for 3D Object Detection
Sep 06, 2021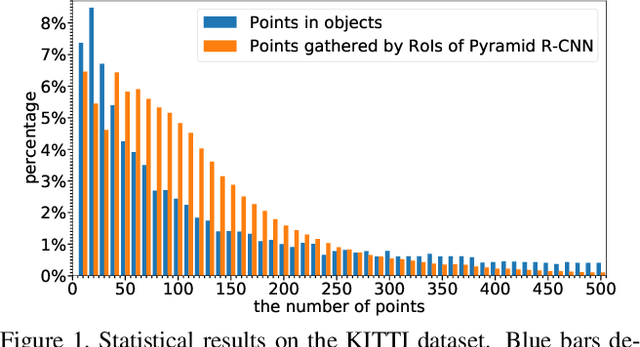
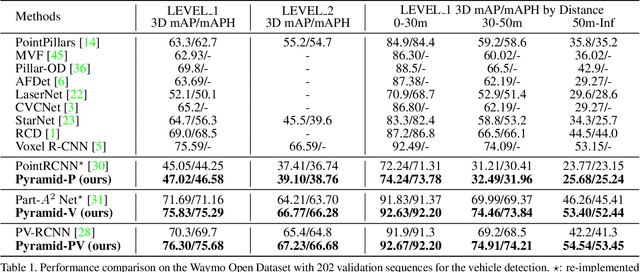
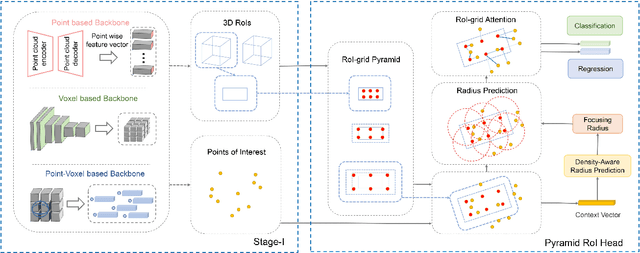

We present a flexible and high-performance framework, named Pyramid R-CNN, for two-stage 3D object detection from point clouds. Current approaches generally rely on the points or voxels of interest for RoI feature extraction on the second stage, but cannot effectively handle the sparsity and non-uniform distribution of those points, and this may result in failures in detecting objects that are far away. To resolve the problems, we propose a novel second-stage module, named pyramid RoI head, to adaptively learn the features from the sparse points of interest. The pyramid RoI head consists of three key components. Firstly, we propose the RoI-grid Pyramid, which mitigates the sparsity problem by extensively collecting points of interest for each RoI in a pyramid manner. Secondly, we propose RoI-grid Attention, a new operation that can encode richer information from sparse points by incorporating conventional attention-based and graph-based point operators into a unified formulation. Thirdly, we propose the Density-Aware Radius Prediction (DARP) module, which can adapt to different point density levels by dynamically adjusting the focusing range of RoIs. Combining the three components, our pyramid RoI head is robust to the sparse and imbalanced circumstances, and can be applied upon various 3D backbones to consistently boost the detection performance. Extensive experiments show that Pyramid R-CNN outperforms the state-of-the-art 3D detection models by a large margin on both the KITTI dataset and the Waymo Open dataset.
Pi-NAS: Improving Neural Architecture Search by Reducing Supernet Training Consistency Shift
Aug 22, 2021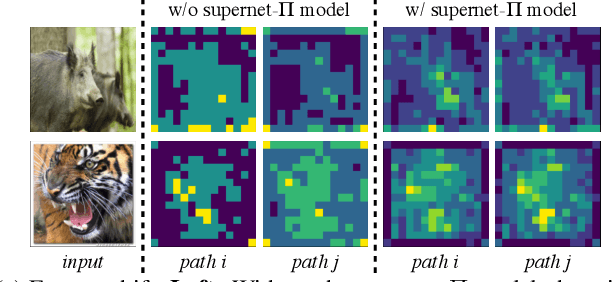
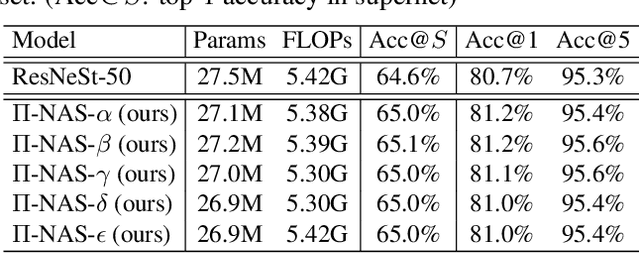
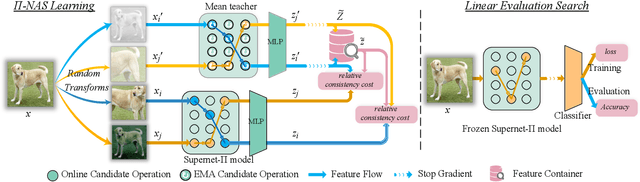
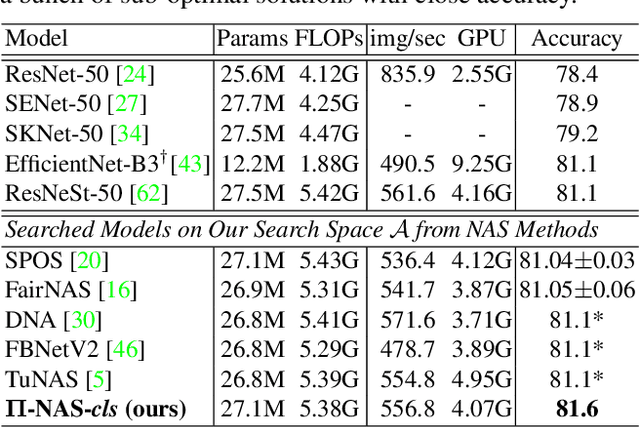
Recently proposed neural architecture search (NAS) methods co-train billions of architectures in a supernet and estimate their potential accuracy using the network weights detached from the supernet. However, the ranking correlation between the architectures' predicted accuracy and their actual capability is incorrect, which causes the existing NAS methods' dilemma. We attribute this ranking correlation problem to the supernet training consistency shift, including feature shift and parameter shift. Feature shift is identified as dynamic input distributions of a hidden layer due to random path sampling. The input distribution dynamic affects the loss descent and finally affects architecture ranking. Parameter shift is identified as contradictory parameter updates for a shared layer lay in different paths in different training steps. The rapidly-changing parameter could not preserve architecture ranking. We address these two shifts simultaneously using a nontrivial supernet-Pi model, called Pi-NAS. Specifically, we employ a supernet-Pi model that contains cross-path learning to reduce the feature consistency shift between different paths. Meanwhile, we adopt a novel nontrivial mean teacher containing negative samples to overcome parameter shift and model collision. Furthermore, our Pi-NAS runs in an unsupervised manner, which can search for more transferable architectures. Extensive experiments on ImageNet and a wide range of downstream tasks (e.g., COCO 2017, ADE20K, and Cityscapes) demonstrate the effectiveness and universality of our Pi-NAS compared to supervised NAS. See Codes: https://github.com/Ernie1/Pi-NAS.
Medical-VLBERT: Medical Visual Language BERT for COVID-19 CT Report Generation With Alternate Learning
Aug 18, 2021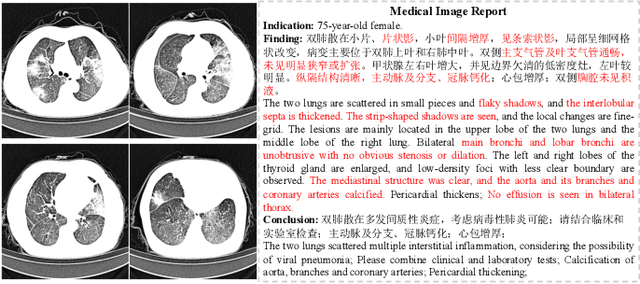
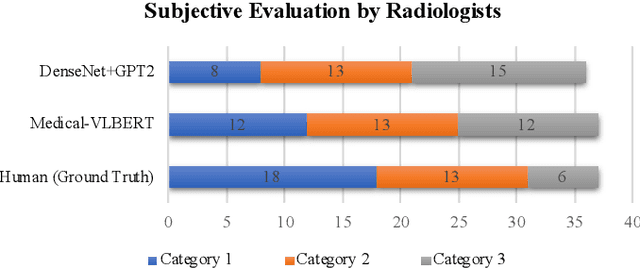
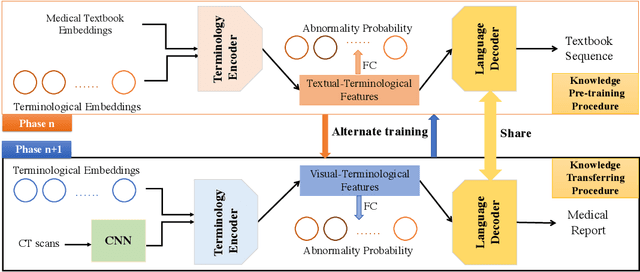
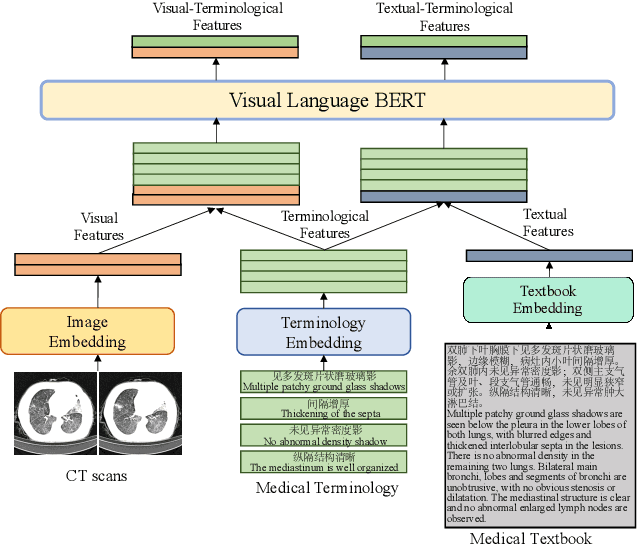
Medical imaging technologies, including computed tomography (CT) or chest X-Ray (CXR), are largely employed to facilitate the diagnosis of the COVID-19. Since manual report writing is usually too time-consuming, a more intelligent auxiliary medical system that could generate medical reports automatically and immediately is urgently needed. In this article, we propose to use the medical visual language BERT (Medical-VLBERT) model to identify the abnormality on the COVID-19 scans and generate the medical report automatically based on the detected lesion regions. To produce more accurate medical reports and minimize the visual-and-linguistic differences, this model adopts an alternate learning strategy with two procedures that are knowledge pretraining and transferring. To be more precise, the knowledge pretraining procedure is to memorize the knowledge from medical texts, while the transferring procedure is to utilize the acquired knowledge for professional medical sentences generations through observations of medical images. In practice, for automatic medical report generation on the COVID-19 cases, we constructed a dataset of 368 medical findings in Chinese and 1104 chest CT scans from The First Affiliated Hospital of Jinan University, Guangzhou, China, and The Fifth Affiliated Hospital of Sun Yat-sen University, Zhuhai, China. Besides, to alleviate the insufficiency of the COVID-19 training samples, our model was first trained on the large-scale Chinese CX-CHR dataset and then transferred to the COVID-19 CT dataset for further fine-tuning. The experimental results showed that Medical-VLBERT achieved state-of-the-art performances on terminology prediction and report generation with the Chinese COVID-19 CT dataset and the CX-CHR dataset. The Chinese COVID-19 CT dataset is available at https://covid19ct.github.io/.
M3D-VTON: A Monocular-to-3D Virtual Try-On Network
Aug 11, 2021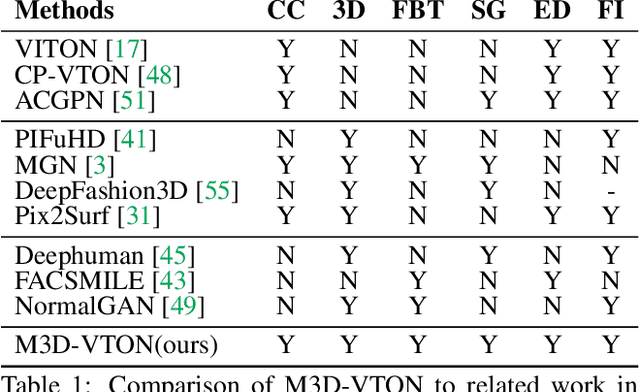
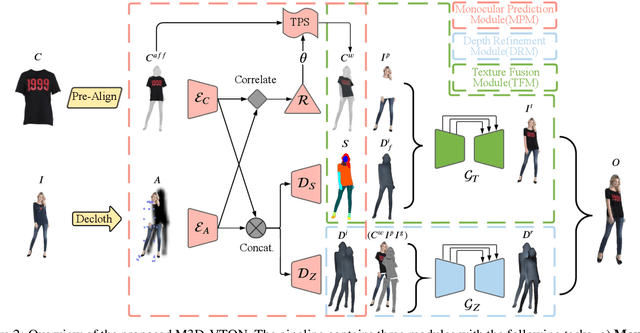
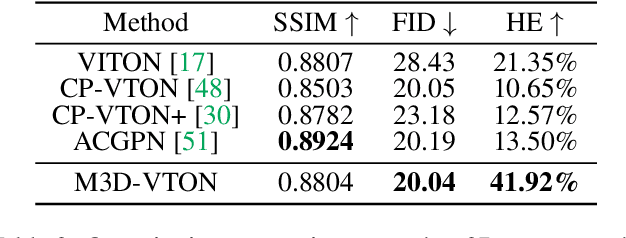
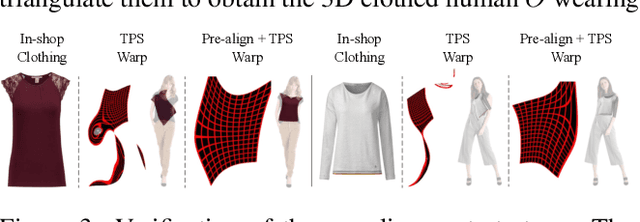
Virtual 3D try-on can provide an intuitive and realistic view for online shopping and has a huge potential commercial value. However, existing 3D virtual try-on methods mainly rely on annotated 3D human shapes and garment templates, which hinders their applications in practical scenarios. 2D virtual try-on approaches provide a faster alternative to manipulate clothed humans, but lack the rich and realistic 3D representation. In this paper, we propose a novel Monocular-to-3D Virtual Try-On Network (M3D-VTON) that builds on the merits of both 2D and 3D approaches. By integrating 2D information efficiently and learning a mapping that lifts the 2D representation to 3D, we make the first attempt to reconstruct a 3D try-on mesh only taking the target clothing and a person image as inputs. The proposed M3D-VTON includes three modules: 1) The Monocular Prediction Module (MPM) that estimates an initial full-body depth map and accomplishes 2D clothes-person alignment through a novel two-stage warping procedure; 2) The Depth Refinement Module (DRM) that refines the initial body depth to produce more detailed pleat and face characteristics; 3) The Texture Fusion Module (TFM) that fuses the warped clothing with the non-target body part to refine the results. We also construct a high-quality synthesized Monocular-to-3D virtual try-on dataset, in which each person image is associated with a front and a back depth map. Extensive experiments demonstrate that the proposed M3D-VTON can manipulate and reconstruct the 3D human body wearing the given clothing with compelling details and is more efficient than other 3D approaches.
Product1M: Towards Weakly Supervised Instance-Level Product Retrieval via Cross-modal Pretraining
Aug 09, 2021
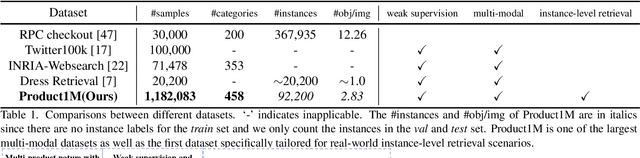
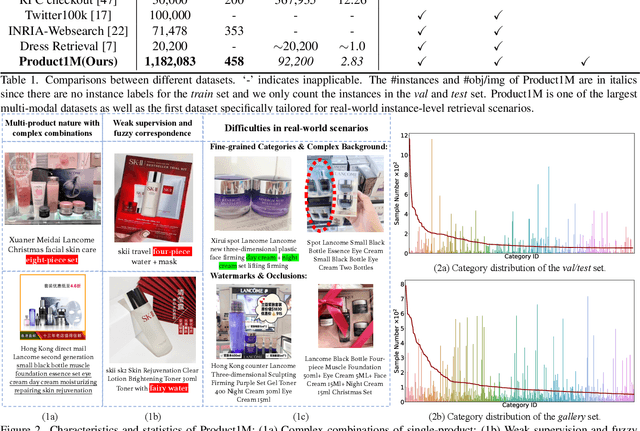
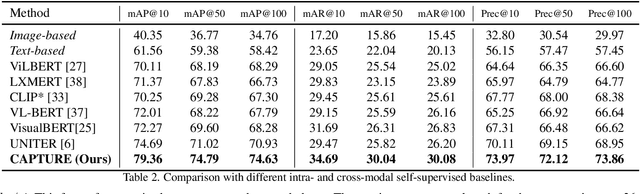
Nowadays, customer's demands for E-commerce are more diversified, which introduces more complications to the product retrieval industry. Previous methods are either subject to single-modal input or perform supervised image-level product retrieval, thus fail to accommodate real-life scenarios where enormous weakly annotated multi-modal data are present. In this paper, we investigate a more realistic setting that aims to perform weakly-supervised multi-modal instance-level product retrieval among fine-grained product categories. To promote the study of this challenging task, we contribute Product1M, one of the largest multi-modal cosmetic datasets for real-world instance-level retrieval. Notably, Product1M contains over 1 million image-caption pairs and consists of two sample types, i.e., single-product and multi-product samples, which encompass a wide variety of cosmetics brands. In addition to the great diversity, Product1M enjoys several appealing characteristics including fine-grained categories, complex combinations, and fuzzy correspondence that well mimic the real-world scenes. Moreover, we propose a novel model named Cross-modal contrAstive Product Transformer for instance-level prodUct REtrieval (CAPTURE), that excels in capturing the potential synergy between multi-modal inputs via a hybrid-stream transformer in a self-supervised manner.CAPTURE generates discriminative instance features via masked multi-modal learning as well as cross-modal contrastive pretraining and it outperforms several SOTA cross-modal baselines. Extensive ablation studies well demonstrate the effectiveness and the generalization capacity of our model. Dataset and codes are available at https: //github.com/zhanxlin/Product1M.
NASOA: Towards Faster Task-oriented Online Fine-tuning with a Zoo of Models
Aug 07, 2021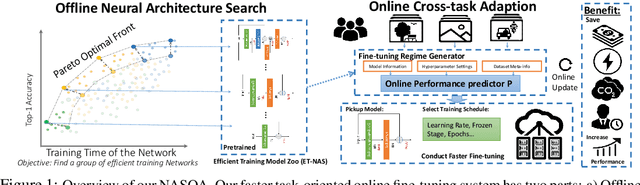

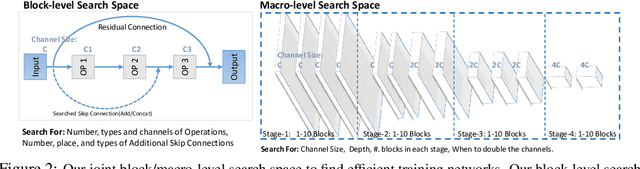
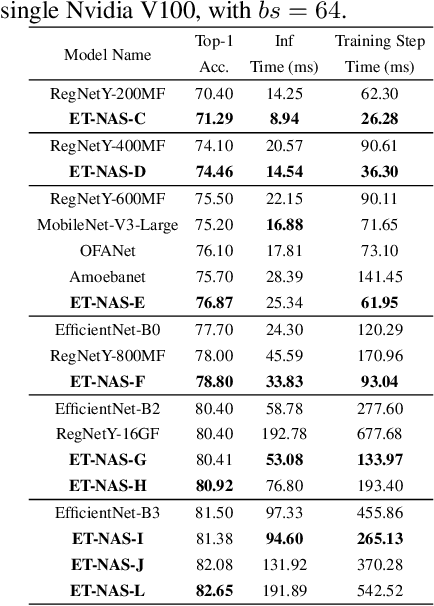
Fine-tuning from pre-trained ImageNet models has been a simple, effective, and popular approach for various computer vision tasks. The common practice of fine-tuning is to adopt a default hyperparameter setting with a fixed pre-trained model, while both of them are not optimized for specific tasks and time constraints. Moreover, in cloud computing or GPU clusters where the tasks arrive sequentially in a stream, faster online fine-tuning is a more desired and realistic strategy for saving money, energy consumption, and CO2 emission. In this paper, we propose a joint Neural Architecture Search and Online Adaption framework named NASOA towards a faster task-oriented fine-tuning upon the request of users. Specifically, NASOA first adopts an offline NAS to identify a group of training-efficient networks to form a pretrained model zoo. We propose a novel joint block and macro-level search space to enable a flexible and efficient search. Then, by estimating fine-tuning performance via an adaptive model by accumulating experience from the past tasks, an online schedule generator is proposed to pick up the most suitable model and generate a personalized training regime with respect to each desired task in a one-shot fashion. The resulting model zoo is more training efficient than SOTA models, e.g. 6x faster than RegNetY-16GF, and 1.7x faster than EfficientNetB3. Experiments on multiple datasets also show that NASOA achieves much better fine-tuning results, i.e. improving around 2.1% accuracy than the best performance in RegNet series under various constraints and tasks; 40x faster compared to the BOHB.
WAS-VTON: Warping Architecture Search for Virtual Try-on Network
Aug 01, 2021
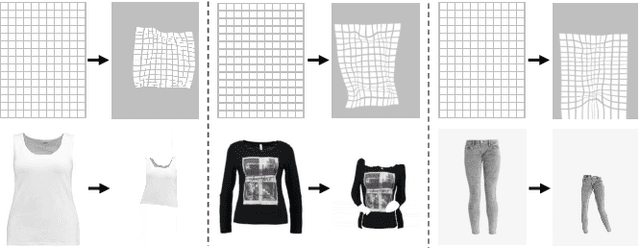

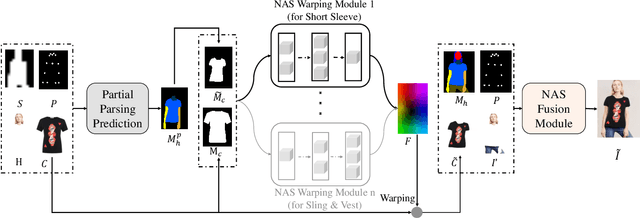
Despite recent progress on image-based virtual try-on, current methods are constraint by shared warping networks and thus fail to synthesize natural try-on results when faced with clothing categories that require different warping operations. In this paper, we address this problem by finding clothing category-specific warping networks for the virtual try-on task via Neural Architecture Search (NAS). We introduce a NAS-Warping Module and elaborately design a bilevel hierarchical search space to identify the optimal network-level and operation-level flow estimation architecture. Given the network-level search space, containing different numbers of warping blocks, and the operation-level search space with different convolution operations, we jointly learn a combination of repeatable warping cells and convolution operations specifically for the clothing-person alignment. Moreover, a NAS-Fusion Module is proposed to synthesize more natural final try-on results, which is realized by leveraging particular skip connections to produce better-fused features that are required for seamlessly fusing the warped clothing and the unchanged person part. We adopt an efficient and stable one-shot searching strategy to search the above two modules. Extensive experiments demonstrate that our WAS-VTON significantly outperforms the previous fixed-architecture try-on methods with more natural warping results and virtual try-on results.
Adversarial Reinforced Instruction Attacker for Robust Vision-Language Navigation
Jul 23, 2021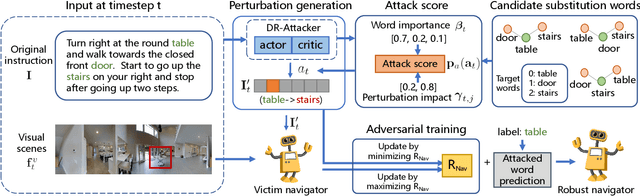
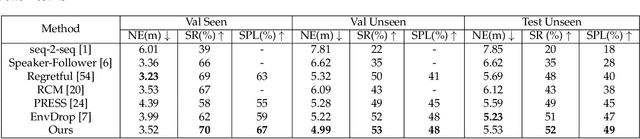
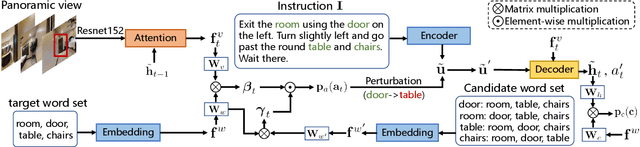

Language instruction plays an essential role in the natural language grounded navigation tasks. However, navigators trained with limited human-annotated instructions may have difficulties in accurately capturing key information from the complicated instruction at different timesteps, leading to poor navigation performance. In this paper, we exploit to train a more robust navigator which is capable of dynamically extracting crucial factors from the long instruction, by using an adversarial attacking paradigm. Specifically, we propose a Dynamic Reinforced Instruction Attacker (DR-Attacker), which learns to mislead the navigator to move to the wrong target by destroying the most instructive information in instructions at different timesteps. By formulating the perturbation generation as a Markov Decision Process, DR-Attacker is optimized by the reinforcement learning algorithm to generate perturbed instructions sequentially during the navigation, according to a learnable attack score. Then, the perturbed instructions, which serve as hard samples, are used for improving the robustness of the navigator with an effective adversarial training strategy and an auxiliary self-supervised reasoning task. Experimental results on both Vision-and-Language Navigation (VLN) and Navigation from Dialog History (NDH) tasks show the superiority of our proposed method over state-of-the-art methods. Moreover, the visualization analysis shows the effectiveness of the proposed DR-Attacker, which can successfully attack crucial information in the instructions at different timesteps. Code is available at https://github.com/expectorlin/DR-Attacker.
* Accepted by TPAMI 2021
Don't Take It Literally: An Edit-Invariant Sequence Loss for Text Generation
Jul 23, 2021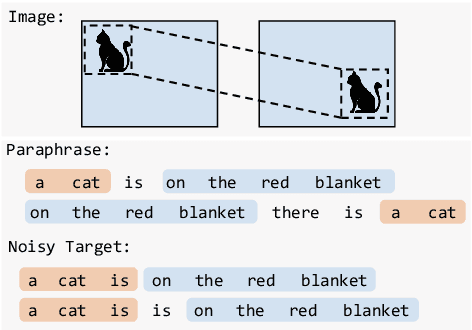
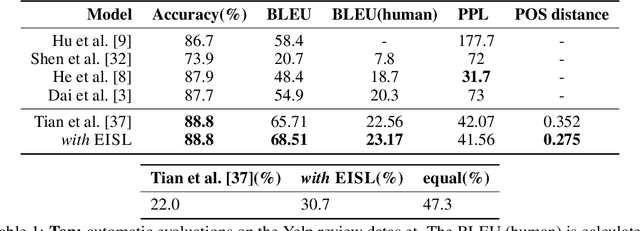
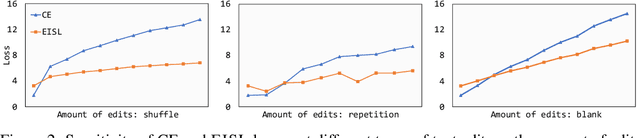
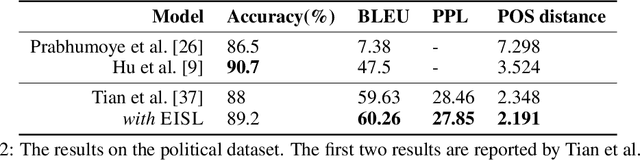
Neural text generation models are typically trained by maximizing log-likelihood with the sequence cross entropy loss, which encourages an exact token-by-token match between a target sequence with a generated sequence. Such training objective is sub-optimal when the target sequence not perfect, e.g., when the target sequence is corrupted with noises, or when only weak sequence supervision is available. To address this challenge, we propose a novel Edit-Invariant Sequence Loss (EISL), which computes the matching loss of a target n-gram with all n-grams in the generated sequence. EISL draws inspirations from convolutional networks (ConvNets) which are shift-invariant to images, hence is robust to the shift of n-grams to tolerate edits in the target sequences. Moreover, the computation of EISL is essentially a convolution operation with target n-grams as kernels, which is easy to implement with existing libraries. To demonstrate the effectiveness of EISL, we conduct experiments on three tasks: machine translation with noisy target sequences, unsupervised text style transfer, and non-autoregressive machine translation. Experimental results show our method significantly outperforms cross entropy loss on these three tasks.
AutoBERT-Zero: Evolving BERT Backbone from Scratch
Jul 15, 2021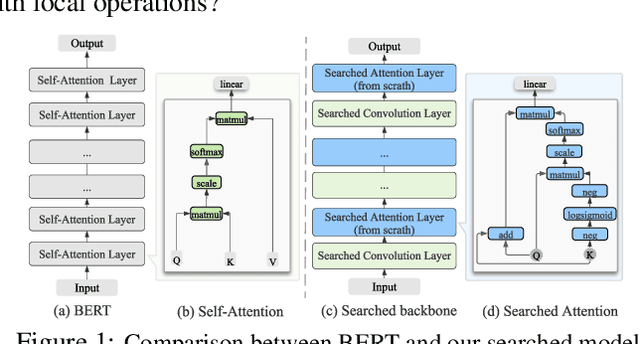

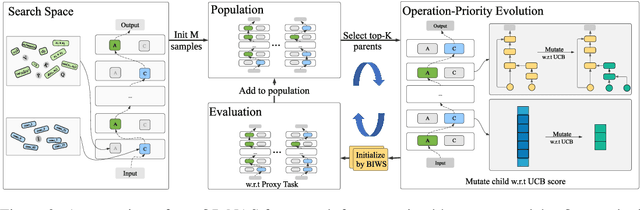
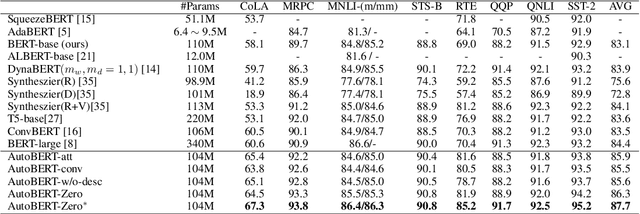
Transformer-based pre-trained language models like BERT and its variants have recently achieved promising performance in various natural language processing (NLP) tasks. However, the conventional paradigm constructs the backbone by purely stacking the manually designed global self-attention layers, introducing inductive bias and thus leading to sub-optimal. In this work, we propose an Operation-Priority Neural Architecture Search (OP-NAS) algorithm to automatically search for promising hybrid backbone architectures. Our well-designed search space (i) contains primitive math operations in the intra-layer level to explore novel attention structures, and (ii) leverages convolution blocks to be the supplementary for attention structure in the inter-layer level to better learn local dependency. We optimize both the search algorithm and evaluation of candidate models to boost the efficiency of our proposed OP-NAS. Specifically, we propose Operation-Priority (OP) evolution strategy to facilitate model search via balancing exploration and exploitation. Furthermore, we design a Bi-branch Weight-Sharing (BIWS) training strategy for fast model evaluation. Extensive experiments show that the searched architecture (named AutoBERT-Zero) significantly outperforms BERT and its variants of different model capacities in various downstream tasks, proving the architecture's transfer and generalization abilities. Remarkably, AutoBERT-Zero-base outperforms RoBERTa-base (using much more data) and BERT-large (with much larger model size) by 2.4 and 1.4 higher score on GLUE test set. Code and pre-trained models will be made publicly available.