 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCase-Guided Sequential Assay Planning in Drug Discovery
Jan 21, 2026Optimally sequencing experimental assays in drug discovery is a high-stakes planning problem under severe uncertainty and resource constraints. A primary obstacle for standard reinforcement learning (RL) is the absence of an explicit environment simulator or transition data $(s, a, s')$; planning must rely solely on a static database of historical outcomes. We introduce the Implicit Bayesian Markov Decision Process (IBMDP), a model-based RL framework designed for such simulator-free settings. IBMDP constructs a case-guided implicit model of transition dynamics by forming a nonparametric belief distribution using similar historical outcomes. This mechanism enables Bayesian belief updating as evidence accumulates and employs ensemble MCTS planning to generate stable policies that balance information gain toward desired outcomes with resource efficiency. We validate IBMDP through comprehensive experiments. On a real-world central nervous system (CNS) drug discovery task, IBMDP reduced resource consumption by up to 92\% compared to established heuristics while maintaining decision confidence. To rigorously assess decision quality, we also benchmarked IBMDP in a synthetic environment with a computable optimal policy. Our framework achieves significantly higher alignment with this optimal policy than a deterministic value iteration alternative that uses the same similarity-based model, demonstrating the superiority of our ensemble planner. IBMDP offers a practical solution for sequential experimental design in data-rich but simulator-poor domains.
Transformer-Based Approach for Automated Functional Group Replacement in Chemical Compounds
Jan 12, 2026Functional group replacement is a pivotal approach in cheminformatics to enable the design of novel chemical compounds with tailored properties. Traditional methods for functional group removal and replacement often rely on rule-based heuristics, which can be limited in their ability to generate diverse and novel chemical structures. Recently, transformer-based models have shown promise in improving the accuracy and efficiency of molecular transformations, but existing approaches typically focus on single-step modeling, lacking the guarantee of structural similarity. In this work, we seek to advance the state of the art by developing a novel two-stage transformer model for functional group removal and replacement. Unlike one-shot approaches that generate entire molecules in a single pass, our method generates the functional group to be removed and appended sequentially, ensuring strict substructure-level modifications. Using a matched molecular pairs (MMPs) dataset derived from ChEMBL, we trained an encoder-decoder transformer model with SMIRKS-based representations to capture transformation rules effectively. Extensive evaluations demonstrate our method's ability to generate chemically valid transformations, explore diverse chemical spaces, and maintain scalability across varying search sizes.
Unified Meta-Representation and Feedback Calibration for General Disturbance Estimation
Jan 06, 2026Precise control in modern robotic applications is always an open issue due to unknown time-varying disturbances. Existing meta-learning-based approaches require a shared representation of environmental structures, which lack flexibility for realistic non-structural disturbances. Besides, representation error and the distribution shifts can lead to heavy degradation in prediction accuracy. This work presents a generalizable disturbance estimation framework that builds on meta-learning and feedback-calibrated online adaptation. By extracting features from a finite time window of past observations, a unified representation that effectively captures general non-structural disturbances can be learned without predefined structural assumptions. The online adaptation process is subsequently calibrated by a state-feedback mechanism to attenuate the learning residual originating from the representation and generalizability limitations. Theoretical analysis shows that simultaneous convergence of both the online learning error and the disturbance estimation error can be achieved. Through the unified meta-representation, our framework effectively estimates multiple rapidly changing disturbances, as demonstrated by quadrotor flight experiments. See the project page for video, supplementary material and code: https://nonstructural-metalearn.github.io.
Optimizing Control-Friendly Trajectories with Self-Supervised Residual Learning
Jan 06, 2026Real-world physics can only be analytically modeled with a certain level of precision for modern intricate robotic systems. As a result, tracking aggressive trajectories accurately could be challenging due to the existence of residual physics during controller synthesis. This paper presents a self-supervised residual learning and trajectory optimization framework to address the aforementioned challenges. At first, unknown dynamic effects on the closed-loop model are learned and treated as residuals of the nominal dynamics, jointly forming a hybrid model. We show that learning with analytic gradients can be achieved using only trajectory-level data while enjoying accurate long-horizon prediction with an arbitrary integration step size. Subsequently, a trajectory optimizer is developed to compute the optimal reference trajectory with the residual physics along it minimized. It ends up with trajectories that are friendly to the following control level. The agile flight of quadrotors illustrates that by utilizing the hybrid dynamics, the proposed optimizer outputs aggressive motions that can be precisely tracked.
PepThink-R1: LLM for Interpretable Cyclic Peptide Optimization with CoT SFT and Reinforcement Learning
Aug 20, 2025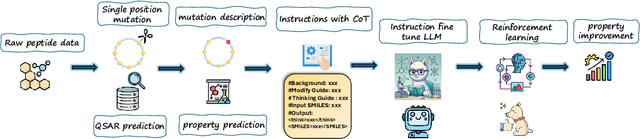
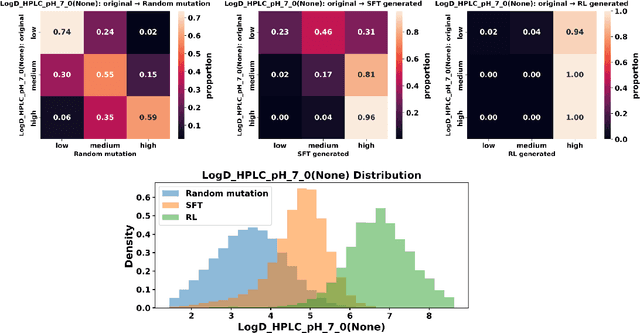
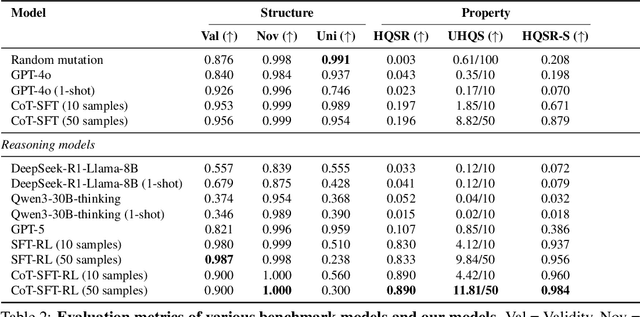
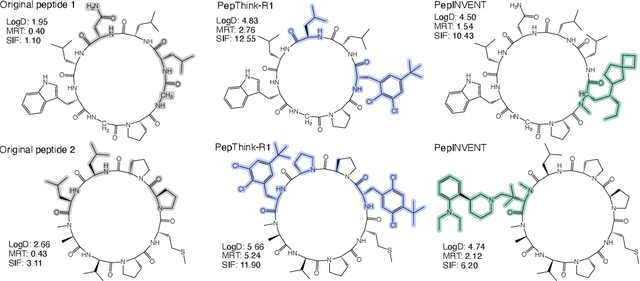
Designing therapeutic peptides with tailored properties is hindered by the vastness of sequence space, limited experimental data, and poor interpretability of current generative models. To address these challenges, we introduce PepThink-R1, a generative framework that integrates large language models (LLMs) with chain-of-thought (CoT) supervised fine-tuning and reinforcement learning (RL). Unlike prior approaches, PepThink-R1 explicitly reasons about monomer-level modifications during sequence generation, enabling interpretable design choices while optimizing for multiple pharmacological properties. Guided by a tailored reward function balancing chemical validity and property improvements, the model autonomously explores diverse sequence variants. We demonstrate that PepThink-R1 generates cyclic peptides with significantly enhanced lipophilicity, stability, and exposure, outperforming existing general LLMs (e.g., GPT-5) and domain-specific baseline in both optimization success and interpretability. To our knowledge, this is the first LLM-based peptide design framework that combines explicit reasoning with RL-driven property control, marking a step toward reliable and transparent peptide optimization for therapeutic discovery.
YOLOv8-SMOT: An Efficient and Robust Framework for Real-Time Small Object Tracking via Slice-Assisted Training and Adaptive Association
Jul 16, 2025



Tracking small, agile multi-objects (SMOT), such as birds, from an Unmanned Aerial Vehicle (UAV) perspective is a highly challenging computer vision task. The difficulty stems from three main sources: the extreme scarcity of target appearance features, the complex motion entanglement caused by the combined dynamics of the camera and the targets themselves, and the frequent occlusions and identity ambiguity arising from dense flocking behavior. This paper details our championship-winning solution in the MVA 2025 "Finding Birds" Small Multi-Object Tracking Challenge (SMOT4SB), which adopts the tracking-by-detection paradigm with targeted innovations at both the detection and association levels. On the detection side, we propose a systematic training enhancement framework named \textbf{SliceTrain}. This framework, through the synergy of 'deterministic full-coverage slicing' and 'slice-level stochastic augmentation, effectively addresses the problem of insufficient learning for small objects in high-resolution image training. On the tracking side, we designed a robust tracker that is completely independent of appearance information. By integrating a \textbf{motion direction maintenance (EMA)} mechanism and an \textbf{adaptive similarity metric} combining \textbf{bounding box expansion and distance penalty} into the OC-SORT framework, our tracker can stably handle irregular motion and maintain target identities. Our method achieves state-of-the-art performance on the SMOT4SB public test set, reaching an SO-HOTA score of \textbf{55.205}, which fully validates the effectiveness and advancement of our framework in solving complex real-world SMOT problems. The source code will be made available at https://github.com/Salvatore-Love/YOLOv8-SMOT.
Simple is what you need for efficient and accurate medical image segmentation
Jun 16, 2025While modern segmentation models often prioritize performance over practicality, we advocate a design philosophy prioritizing simplicity and efficiency, and attempted high performance segmentation model design. This paper presents SimpleUNet, a scalable ultra-lightweight medical image segmentation model with three key innovations: (1) A partial feature selection mechanism in skip connections for redundancy reduction while enhancing segmentation performance; (2) A fixed-width architecture that prevents exponential parameter growth across network stages; (3) An adaptive feature fusion module achieving enhanced representation with minimal computational overhead. With a record-breaking 16 KB parameter configuration, SimpleUNet outperforms LBUNet and other lightweight benchmarks across multiple public datasets. The 0.67 MB variant achieves superior efficiency (8.60 GFLOPs) and accuracy, attaining a mean DSC/IoU of 85.76%/75.60% on multi-center breast lesion datasets, surpassing both U-Net and TransUNet. Evaluations on skin lesion datasets (ISIC 2017/2018: mDice 84.86%/88.77%) and endoscopic polyp segmentation (KVASIR-SEG: 86.46%/76.48% mDice/mIoU) confirm consistent dominance over state-of-the-art models. This work demonstrates that extreme model compression need not compromise performance, providing new insights for efficient and accurate medical image segmentation. Codes can be found at https://github.com/Frankyu5666666/SimpleUNet.
Risk-sensitive Reinforcement Learning Based on Convex Scoring Functions
May 07, 2025



We propose a reinforcement learning (RL) framework under a broad class of risk objectives, characterized by convex scoring functions. This class covers many common risk measures, such as variance, Expected Shortfall, entropic Value-at-Risk, and mean-risk utility. To resolve the time-inconsistency issue, we consider an augmented state space and an auxiliary variable and recast the problem as a two-state optimization problem. We propose a customized Actor-Critic algorithm and establish some theoretical approximation guarantees. A key theoretical contribution is that our results do not require the Markov decision process to be continuous. Additionally, we propose an auxiliary variable sampling method inspired by the alternating minimization algorithm, which is convergent under certain conditions. We validate our approach in simulation experiments with a financial application in statistical arbitrage trading, demonstrating the effectiveness of the algorithm.
Multivariate Conformal Selection
May 01, 2025



Selecting high-quality candidates from large datasets is critical in applications such as drug discovery, precision medicine, and alignment of large language models (LLMs). While Conformal Selection (CS) provides rigorous uncertainty quantification, it is limited to univariate responses and scalar criteria. To address this issue, we propose Multivariate Conformal Selection (mCS), a generalization of CS designed for multivariate response settings. Our method introduces regional monotonicity and employs multivariate nonconformity scores to construct conformal p-values, enabling finite-sample False Discovery Rate (FDR) control. We present two variants: mCS-dist, using distance-based scores, and mCS-learn, which learns optimal scores via differentiable optimization. Experiments on simulated and real-world datasets demonstrate that mCS significantly improves selection power while maintaining FDR control, establishing it as a robust framework for multivariate selection tasks.
Towards Collaborative Anti-Money Laundering Among Financial Institutions
Feb 27, 2025



Money laundering is the process that intends to legalize the income derived from illicit activities, thus facilitating their entry into the monetary flow of the economy without jeopardizing their source. It is crucial to identify such activities accurately and reliably in order to enforce anti-money laundering (AML). Despite considerable efforts to AML, a large number of such activities still go undetected. Rule-based methods were first introduced and are still widely used in current detection systems. With the rise of machine learning, graph-based learning methods have gained prominence in detecting illicit accounts through the analysis of money transfer graphs. Nevertheless, these methods generally assume that the transaction graph is centralized, whereas in practice, money laundering activities usually span multiple financial institutions. Due to regulatory, legal, commercial, and customer privacy concerns, institutions tend not to share data, restricting their utility in practical usage. In this paper, we propose the first algorithm that supports performing AML over multiple institutions while protecting the security and privacy of local data. To evaluate, we construct Alipay-ECB, a real-world dataset comprising digital transactions from Alipay, the world's largest mobile payment platform, alongside transactions from E-Commerce Bank (ECB). The dataset includes over 200 million accounts and 300 million transactions, covering both intra-institution transactions and those between Alipay and ECB. This makes it the largest real-world transaction graph available for analysis. The experimental results demonstrate that our methods can effectively identify cross-institution money laundering subgroups. Additionally, experiments on synthetic datasets also demonstrate that our method is efficient, requiring only a few minutes on datasets with millions of transactions.