 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
Constructing Ophthalmic MLLM for Positioning-diagnosis Collaboration Through Clinical Cognitive Chain Reasoning
Jul 23, 2025Multimodal large language models (MLLMs) demonstrate significant potential in the field of medical diagnosis. However, they face critical challenges in specialized domains such as ophthalmology, particularly the fragmentation of annotation granularity and inconsistencies in clinical reasoning logic, which hinder precise cross-modal understanding. This paper introduces FundusExpert, an ophthalmology-specific MLLM with integrated positioning-diagnosis reasoning capabilities, along with FundusGen, a dataset constructed through the intelligent Fundus-Engine system. Fundus-Engine automates localization and leverages MLLM-based semantic expansion to integrate global disease classification, local object detection, and fine-grained feature analysis within a single fundus image. Additionally, by constructing a clinically aligned cognitive chain, it guides the model to generate interpretable reasoning paths. FundusExpert, fine-tuned with instruction data from FundusGen, achieves the best performance in ophthalmic question-answering tasks, surpassing the average accuracy of the 40B MedRegA by 26.6%. It also excels in zero-shot report generation tasks, achieving a clinical consistency of 77.0%, significantly outperforming GPT-4o's 47.6%. Furthermore, we reveal a scaling law between data quality and model capability ($L \propto N^{0.068}$), demonstrating that the cognitive alignment annotations in FundusGen enhance data utilization efficiency. By integrating region-level localization with diagnostic reasoning chains, our work develops a scalable, clinically-aligned MLLM and explores a pathway toward bridging the visual-language gap in specific MLLMs. Our project can be found at https://github.com/MeteorElf/FundusExpert.
YOLOv8-SMOT: An Efficient and Robust Framework for Real-Time Small Object Tracking via Slice-Assisted Training and Adaptive Association
Jul 16, 2025



Tracking small, agile multi-objects (SMOT), such as birds, from an Unmanned Aerial Vehicle (UAV) perspective is a highly challenging computer vision task. The difficulty stems from three main sources: the extreme scarcity of target appearance features, the complex motion entanglement caused by the combined dynamics of the camera and the targets themselves, and the frequent occlusions and identity ambiguity arising from dense flocking behavior. This paper details our championship-winning solution in the MVA 2025 "Finding Birds" Small Multi-Object Tracking Challenge (SMOT4SB), which adopts the tracking-by-detection paradigm with targeted innovations at both the detection and association levels. On the detection side, we propose a systematic training enhancement framework named \textbf{SliceTrain}. This framework, through the synergy of 'deterministic full-coverage slicing' and 'slice-level stochastic augmentation, effectively addresses the problem of insufficient learning for small objects in high-resolution image training. On the tracking side, we designed a robust tracker that is completely independent of appearance information. By integrating a \textbf{motion direction maintenance (EMA)} mechanism and an \textbf{adaptive similarity metric} combining \textbf{bounding box expansion and distance penalty} into the OC-SORT framework, our tracker can stably handle irregular motion and maintain target identities. Our method achieves state-of-the-art performance on the SMOT4SB public test set, reaching an SO-HOTA score of \textbf{55.205}, which fully validates the effectiveness and advancement of our framework in solving complex real-world SMOT problems. The source code will be made available at https://github.com/Salvatore-Love/YOLOv8-SMOT.
GPLQ: A General, Practical, and Lightning QAT Method for Vision Transformers
Jun 13, 2025Vision Transformers (ViTs) are essential in computer vision but are computationally intensive, too. Model quantization, particularly to low bit-widths like 4-bit, aims to alleviate this difficulty, yet existing Post-Training Quantization (PTQ) and Quantization-Aware Training (QAT) methods exhibit significant limitations. PTQ often incurs substantial accuracy drop, while QAT achieves high accuracy but suffers from prohibitive computational costs, limited generalization to downstream tasks, training instability, and lacking of open-source codebase. To address these challenges, this paper introduces General, Practical, and Lightning Quantization (GPLQ), a novel framework designed for efficient and effective ViT quantization. GPLQ is founded on two key empirical insights: the paramount importance of activation quantization and the necessity of preserving the model's original optimization ``basin'' to maintain generalization. Consequently, GPLQ employs a sequential ``activation-first, weights-later'' strategy. Stage 1 keeps weights in FP32 while quantizing activations with a feature mimicking loss in only 1 epoch to keep it stay in the same ``basin'', thereby preserving generalization. Stage 2 quantizes weights using a PTQ method. As a result, GPLQ is 100x faster than existing QAT methods, lowers memory footprint to levels even below FP32 training, and achieves 4-bit model performance that is highly competitive with FP32 models in terms of both accuracy on ImageNet and generalization to diverse downstream tasks, including fine-grained visual classification and object detection. We will release an easy-to-use open-source toolkit supporting multiple vision tasks.
A Pre-trained Data Deduplication Model based on Active Learning
Jul 31, 2023



In the era of big data, the issue of data quality has become increasingly prominent. One of the main challenges is the problem of duplicate data, which can arise from repeated entry or the merging of multiple data sources. These "dirty data" problems can significantly limit the effective application of big data. To address the issue of data deduplication, we propose a pre-trained deduplication model based on active learning, which is the first work that utilizes active learning to address the problem of deduplication at the semantic level. The model is built on a pre-trained Transformer and fine-tuned to solve the deduplication problem as a sequence to classification task, which firstly integrate the transformer with active learning into an end-to-end architecture to select the most valuable data for deduplication model training, and also firstly employ the R-Drop method to perform data augmentation on each round of labeled data, which can reduce the cost of manual labeling and improve the model's performance. Experimental results demonstrate that our proposed model outperforms previous state-of-the-art (SOTA) for deduplicated data identification, achieving up to a 28% improvement in Recall score on benchmark datasets.
MVA2023 Small Object Detection Challenge for Spotting Birds: Dataset, Methods, and Results
Jul 18, 2023



Small Object Detection (SOD) is an important machine vision topic because (i) a variety of real-world applications require object detection for distant objects and (ii) SOD is a challenging task due to the noisy, blurred, and less-informative image appearances of small objects. This paper proposes a new SOD dataset consisting of 39,070 images including 137,121 bird instances, which is called the Small Object Detection for Spotting Birds (SOD4SB) dataset. The detail of the challenge with the SOD4SB dataset is introduced in this paper. In total, 223 participants joined this challenge. This paper briefly introduces the award-winning methods. The dataset, the baseline code, and the website for evaluation on the public testset are publicly available.
A Missing Value Filling Model Based on Feature Fusion Enhanced Autoencoder
Aug 29, 2022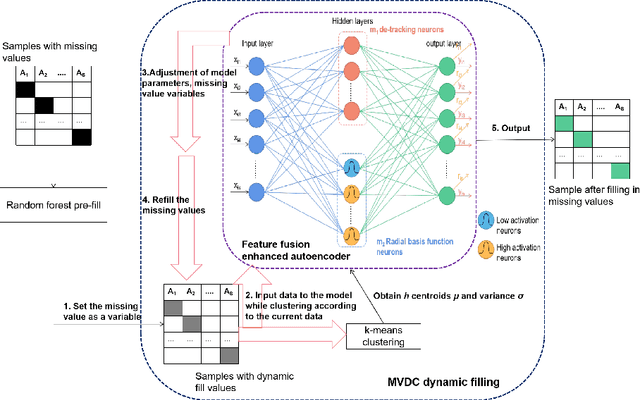
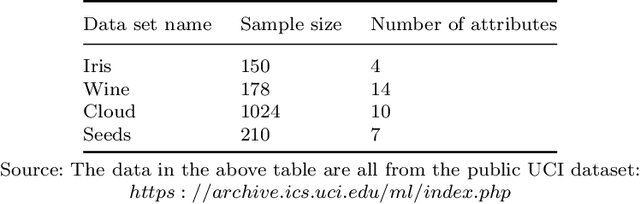
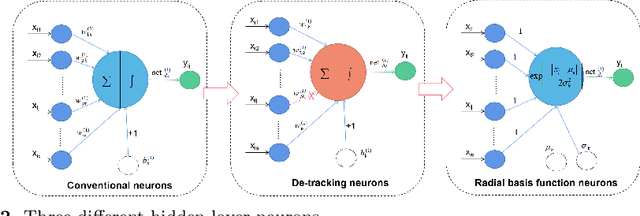
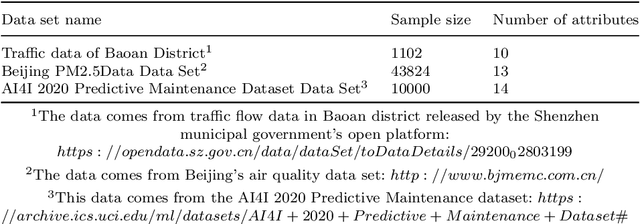
With the advent of the big data era, the data quality problem is becoming more and more crucial. Among many factors, data with missing values is one primary issue, and thus developing effective imputation models is a key topic in the research community. Recently, a major research direction is to employ neural network models such as selforganizing mappings or automatic encoders for filling missing values. However, these classical methods can hardly discover correlation features and common features simultaneously among data attributes. Especially,it is a very typical problem for classical autoencoders that they often learn invalid constant mappings, thus dramatically hurting the filling performance. To solve the above problems, we propose and develop a missing-value-filling model based on a feature-fusion-enhanced autoencoder. We first design and incorporate into an autoencoder a hidden layer that consists of de-tracking neurons and radial basis function neurons, which can enhance the ability to learn correlated features and common features. Besides, we develop a missing value filling strategy based on dynamic clustering (MVDC) that is incorporated into an iterative optimization process. This design can enhance the multi-dimensional feature fusion ability and thus improves the dynamic collaborative missing-value-filling performance. The effectiveness of our model is validated by experimental comparisons to many missing-value-filling methods that are tested on seven datasets with different missing rates.