 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinancial Risk Assessment via Long-term Payment Behavior Sequence Folding
Nov 22, 2024



Online inclusive financial services encounter significant financial risks due to their expansive user base and low default costs. By real-world practice, we reveal that utilizing longer-term user payment behaviors can enhance models' ability to forecast financial risks. However, learning long behavior sequences is non-trivial for deep sequential models. Additionally, the diverse fields of payment behaviors carry rich information, requiring thorough exploitation. These factors collectively complicate the task of long-term user behavior modeling. To tackle these challenges, we propose a Long-term Payment Behavior Sequence Folding method, referred to as LBSF. In LBSF, payment behavior sequences are folded based on merchants, using the merchant field as an intrinsic grouping criterion, which enables informative parallelism without reliance on external knowledge. Meanwhile, we maximize the utility of payment details through a multi-field behavior encoding mechanism. Subsequently, behavior aggregation at the merchant level followed by relational learning across merchants facilitates comprehensive user financial representation. We evaluate LBSF on the financial risk assessment task using a large-scale real-world dataset. The results demonstrate that folding long behavior sequences based on internal behavioral cues effectively models long-term patterns and changes, thereby generating more accurate user financial profiles for practical applications.
Adapting Vision-Language Models to Open Classes via Test-Time Prompt Tuning
Aug 29, 2024



Adapting pre-trained models to open classes is a challenging problem in machine learning. Vision-language models fully explore the knowledge of text modality, demonstrating strong zero-shot recognition performance, which is naturally suited for various open-set problems. More recently, some research focuses on fine-tuning such models to downstream tasks. Prompt tuning methods achieved huge improvements by learning context vectors on few-shot data. However, through the evaluation under open-set adaptation setting with the test data including new classes, we find that there exists a dilemma that learned prompts have worse generalization abilities than hand-crafted prompts. In this paper, we consider combining the advantages of both and come up with a test-time prompt tuning approach, which leverages the maximum concept matching (MCM) scores as dynamic weights to generate an input-conditioned prompt for each image during test. Through extensive experiments on 11 different datasets, we show that our proposed method outperforms all comparison methods on average considering both base and new classes. The code is available at https://github.com/gaozhengqing/TTPT
AlphaForge: A Framework to Mine and Dynamically Combine Formulaic Alpha Factors
Jun 26, 2024



The variability and low signal-to-noise ratio in financial data, combined with the necessity for interpretability, make the alpha factor mining workflow a crucial component of quantitative investment. Transitioning from early manual extraction to genetic programming, the most advanced approach in this domain currently employs reinforcement learning to mine a set of combination factors with fixed weights. However, the performance of resultant alpha factors exhibits inconsistency, and the inflexibility of fixed factor weights proves insufficient in adapting to the dynamic nature of financial markets. To address this issue, this paper proposes a two-stage formulaic alpha generating framework AlphaForge, for alpha factor mining and factor combination. This framework employs a generative-predictive neural network to generate factors, leveraging the robust spatial exploration capabilities inherent in deep learning while concurrently preserving diversity. The combination model within the framework incorporates the temporal performance of factors for selection and dynamically adjusts the weights assigned to each component alpha factor. Experiments conducted on real-world datasets demonstrate that our proposed model outperforms contemporary benchmarks in formulaic alpha factor mining. Furthermore, our model exhibits a notable enhancement in portfolio returns within the realm of quantitative investment.
LOGIN: A Large Language Model Consulted Graph Neural Network Training Framework
May 22, 2024



Recent prevailing works on graph machine learning typically follow a similar methodology that involves designing advanced variants of graph neural networks (GNNs) to maintain the superior performance of GNNs on different graphs. In this paper, we aim to streamline the GNN design process and leverage the advantages of Large Language Models (LLMs) to improve the performance of GNNs on downstream tasks. We formulate a new paradigm, coined "LLMs-as-Consultants," which integrates LLMs with GNNs in an interactive manner. A framework named LOGIN (LLM Consulted GNN training) is instantiated, empowering the interactive utilization of LLMs within the GNN training process. First, we attentively craft concise prompts for spotted nodes, carrying comprehensive semantic and topological information, and serving as input to LLMs. Second, we refine GNNs by devising a complementary coping mechanism that utilizes the responses from LLMs, depending on their correctness. We empirically evaluate the effectiveness of LOGIN on node classification tasks across both homophilic and heterophilic graphs. The results illustrate that even basic GNN architectures, when employed within the proposed LLMs-as-Consultants paradigm, can achieve comparable performance to advanced GNNs with intricate designs. Our codes are available at https://github.com/QiaoYRan/LOGIN.
EFSA: Towards Event-Level Financial Sentiment Analysis
Apr 08, 2024In this paper, we extend financial sentiment analysis~(FSA) to event-level since events usually serve as the subject of the sentiment in financial text. Though extracting events from the financial text may be conducive to accurate sentiment predictions, it has specialized challenges due to the lengthy and discontinuity of events in a financial text. To this end, we reconceptualize the event extraction as a classification task by designing a categorization comprising coarse-grained and fine-grained event categories. Under this setting, we formulate the \textbf{E}vent-Level \textbf{F}inancial \textbf{S}entiment \textbf{A}nalysis~(\textbf{EFSA} for short) task that outputs quintuples consisting of (company, industry, coarse-grained event, fine-grained event, sentiment) from financial text. A large-scale Chinese dataset containing $12,160$ news articles and $13,725$ quintuples is publicized as a brand new testbed for our task. A four-hop Chain-of-Thought LLM-based approach is devised for this task. Systematically investigations are conducted on our dataset, and the empirical results demonstrate the benchmarking scores of existing methods and our proposed method can reach the current state-of-the-art. Our dataset and framework implementation are available at https://anonymous.4open.science/r/EFSA-645E
Reliable Representations Make A Stronger Defender: Unsupervised Structure Refinement for Robust GNN
Jun 30, 2022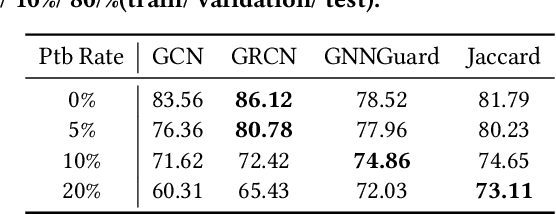
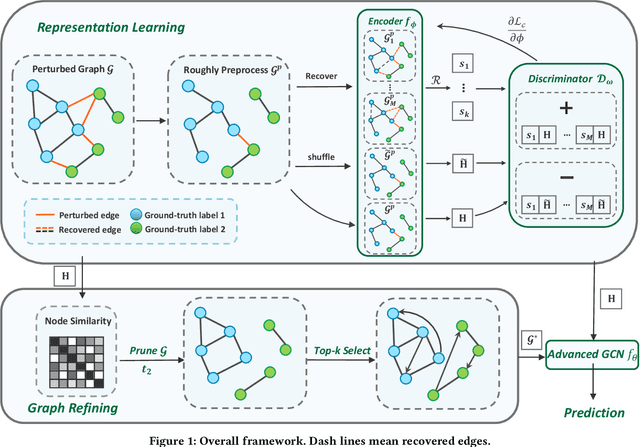
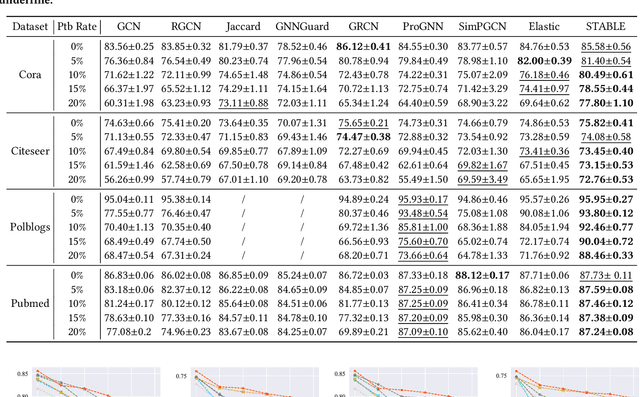
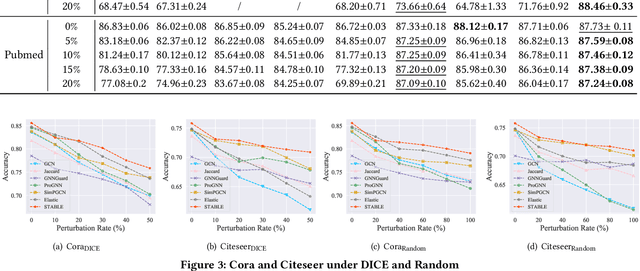
Benefiting from the message passing mechanism, Graph Neural Networks (GNNs) have been successful on flourish tasks over graph data. However, recent studies have shown that attackers can catastrophically degrade the performance of GNNs by maliciously modifying the graph structure. A straightforward solution to remedy this issue is to model the edge weights by learning a metric function between pairwise representations of two end nodes, which attempts to assign low weights to adversarial edges. The existing methods use either raw features or representations learned by supervised GNNs to model the edge weights. However, both strategies are faced with some immediate problems: raw features cannot represent various properties of nodes (e.g., structure information), and representations learned by supervised GNN may suffer from the poor performance of the classifier on the poisoned graph. We need representations that carry both feature information and as mush correct structure information as possible and are insensitive to structural perturbations. To this end, we propose an unsupervised pipeline, named STABLE, to optimize the graph structure. Finally, we input the well-refined graph into a downstream classifier. For this part, we design an advanced GCN that significantly enhances the robustness of vanilla GCN without increasing the time complexity. Extensive experiments on four real-world graph benchmarks demonstrate that STABLE outperforms the state-of-the-art methods and successfully defends against various attacks.
Selective Fairness in Recommendation via Prompts
May 10, 2022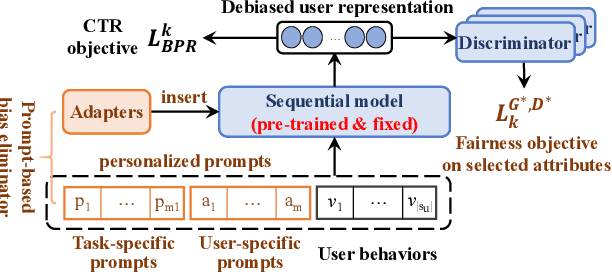

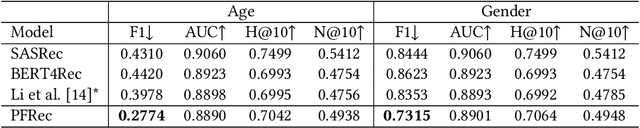
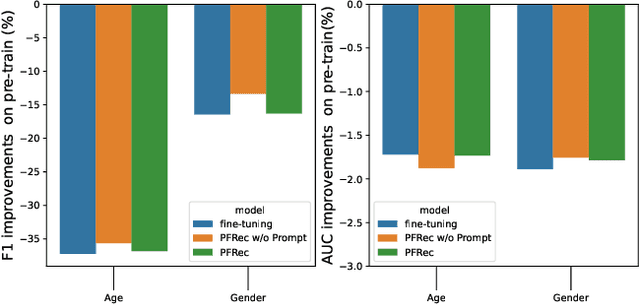
Recommendation fairness has attracted great attention recently. In real-world systems, users usually have multiple sensitive attributes (e.g. age, gender, and occupation), and users may not want their recommendation results influenced by those attributes. Moreover, which of and when these user attributes should be considered in fairness-aware modeling should depend on users' specific demands. In this work, we define the selective fairness task, where users can flexibly choose which sensitive attributes should the recommendation model be bias-free. We propose a novel parameter-efficient prompt-based fairness-aware recommendation (PFRec) framework, which relies on attribute-specific prompt-based bias eliminators with adversarial training, enabling selective fairness with different attribute combinations on sequential recommendation. Both task-specific and user-specific prompts are considered. We conduct extensive evaluations to verify PFRec's superiority in selective fairness. The source codes are released in \url{https://github.com/wyqing20/PFRec}.
User-Centric Conversational Recommendation with Multi-Aspect User Modeling
Apr 25, 2022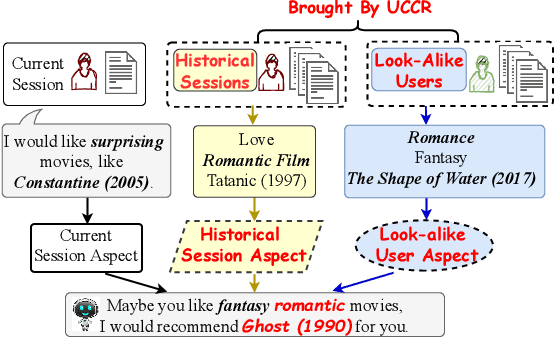
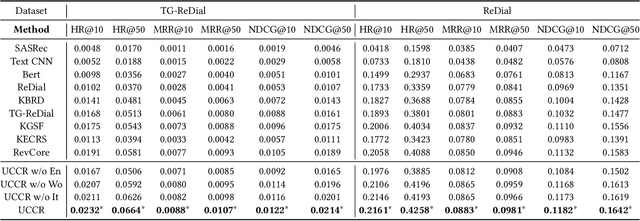
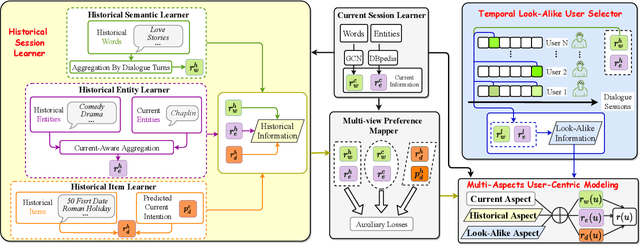
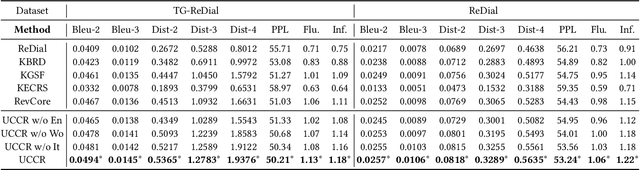
Conversational recommender systems (CRS) aim to provide highquality recommendations in conversations. However, most conventional CRS models mainly focus on the dialogue understanding of the current session, ignoring other rich multi-aspect information of the central subjects (i.e., users) in recommendation. In this work, we highlight that the user's historical dialogue sessions and look-alike users are essential sources of user preferences besides the current dialogue session in CRS. To systematically model the multi-aspect information, we propose a User-Centric Conversational Recommendation (UCCR) model, which returns to the essence of user preference learning in CRS tasks. Specifically, we propose a historical session learner to capture users' multi-view preferences from knowledge, semantic, and consuming views as supplements to the current preference signals. A multi-view preference mapper is conducted to learn the intrinsic correlations among different views in current and historical sessions via self-supervised objectives. We also design a temporal look-alike user selector to understand users via their similar users. The learned multi-aspect multi-view user preferences are then used for the recommendation and dialogue generation. In experiments, we conduct comprehensive evaluations on both Chinese and English CRS datasets. The significant improvements over competitive models in both recommendation and dialogue generation verify the superiority of UCCR.
Multi-view Multi-behavior Contrastive Learning in Recommendation
Mar 20, 2022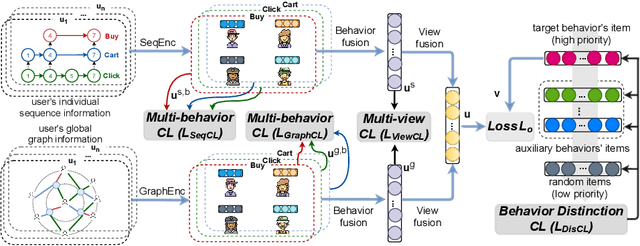
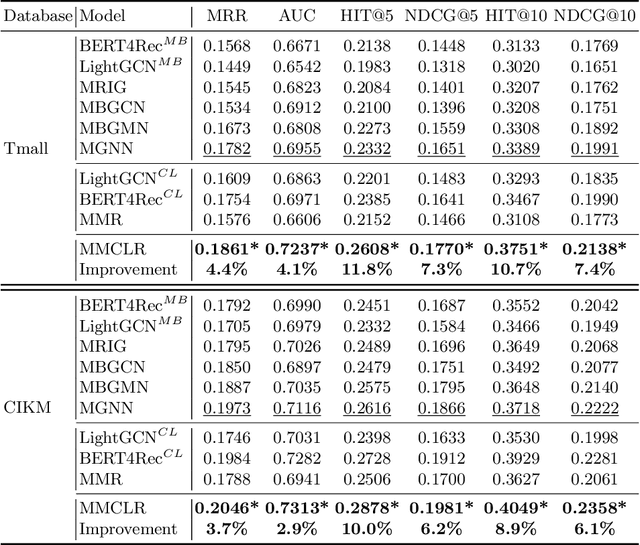
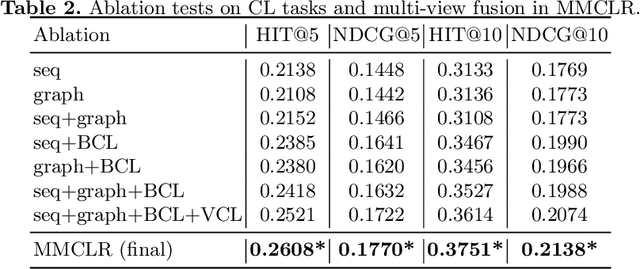
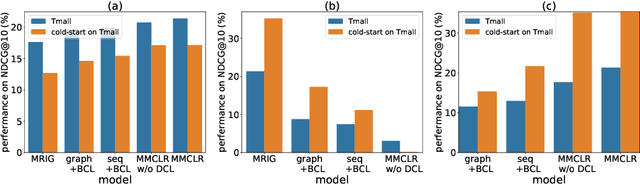
Multi-behavior recommendation (MBR) aims to jointly consider multiple behaviors to improve the target behavior's performance. We argue that MBR models should: (1) model the coarse-grained commonalities between different behaviors of a user, (2) consider both individual sequence view and global graph view in multi-behavior modeling, and (3) capture the fine-grained differences between multiple behaviors of a user. In this work, we propose a novel Multi-behavior Multi-view Contrastive Learning Recommendation (MMCLR) framework, including three new CL tasks to solve the above challenges, respectively. The multi-behavior CL aims to make different user single-behavior representations of the same user in each view to be similar. The multi-view CL attempts to bridge the gap between a user's sequence-view and graph-view representations. The behavior distinction CL focuses on modeling fine-grained differences of different behaviors. In experiments, we conduct extensive evaluations and ablation tests to verify the effectiveness of MMCLR and various CL tasks on two real-world datasets, achieving SOTA performance over existing baselines. Our code will be available on \url{https://github.com/wyqing20/MMCLR}
Highly sensitive fire alarm system based on cellulose paper with low temperature response and wireless signal conversion
Dec 28, 2021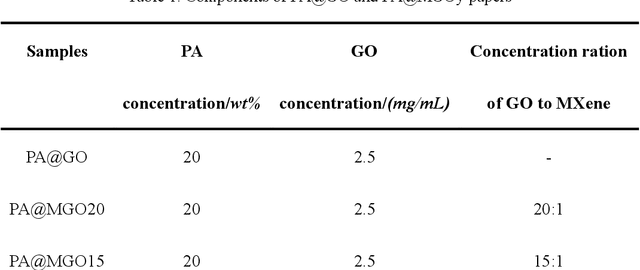
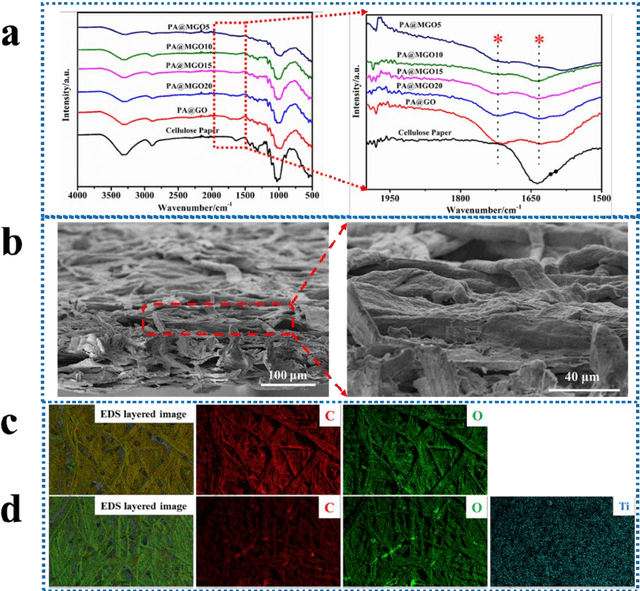
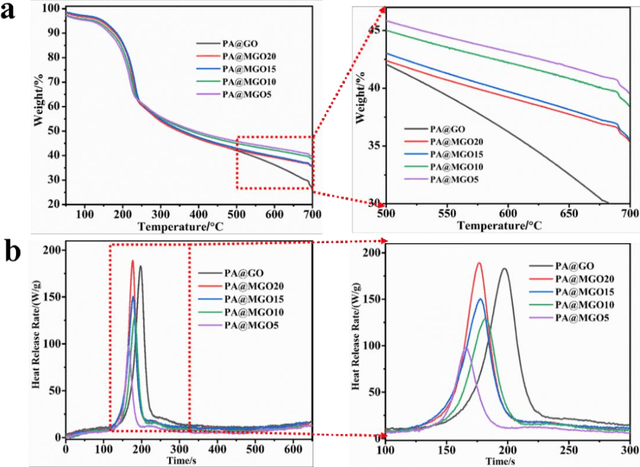
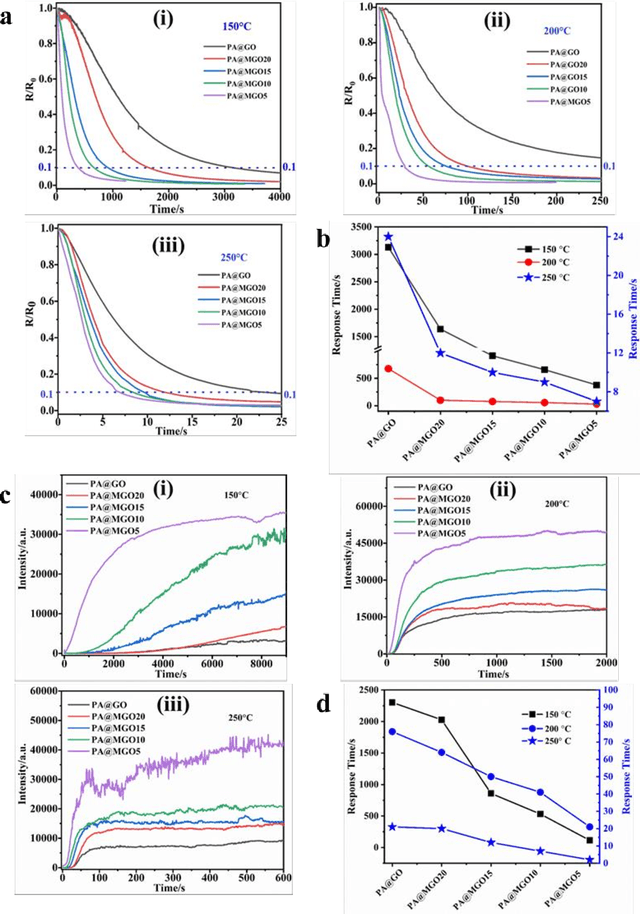
Highly sensitive smart sensors for early fire detection with remote warning capabilities are urgently required to improve the fire safety of combustible materials in diverse applications. The highly-sensitive fire alarm can detect fire situation within a short time quickly when a fire disaster is about to occur, which is conducive to achieve fire tuned. Herein, a novel fire alarm is designed by using flame-retardant cellulose paper loaded with graphene oxide (GO) and two-dimensional titanium carbide (Ti3C2, MXene). Owing to the excellent temperature dependent electrical resistance switching effect of GO, it acts as an electrical insulator at room temperature and becomes electrically conductive at high temperature. During a fire incident, the partial oxygen-containing groups on GO will undergo complete removal, which results in the conductivity transformation.Besides the use of GO feature, this work also introduces conductive MXene to enhance fire detection speed and warning at low temperature, especially below 300 {\deg}C. The designed flame-retardant fire alarm is sensitive enough to detect fire incident, showing a response time of 2 s at 250 {\deg}C, which is calculated by a novel and quantifiable technique. More importantly, the designed fire alarm sensor is coupled to a wireless communication interface to conveniently transmit fire signal remotely. Therefore, when an abnormal temperature is detected, the signal is wirelessly transmitted to a liquid crystal display (LCD) screen when displays a message such as "FIRE DANGER". The designed smart fire alarm paper is promising for use as a smart wallpaper for interior house decoration and other applications requiring early fire detection and warning.