 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Ended Learning Leads to Generally Capable Agents
Jul 31, 2021
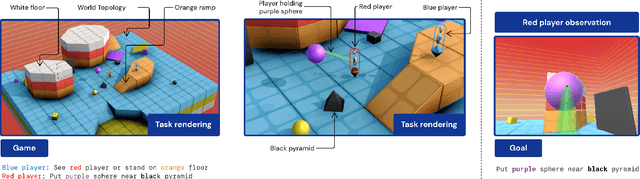

In this work we create agents that can perform well beyond a single, individual task, that exhibit much wider generalisation of behaviour to a massive, rich space of challenges. We define a universe of tasks within an environment domain and demonstrate the ability to train agents that are generally capable across this vast space and beyond. The environment is natively multi-agent, spanning the continuum of competitive, cooperative, and independent games, which are situated within procedurally generated physical 3D worlds. The resulting space is exceptionally diverse in terms of the challenges posed to agents, and as such, even measuring the learning progress of an agent is an open research problem. We propose an iterative notion of improvement between successive generations of agents, rather than seeking to maximise a singular objective, allowing us to quantify progress despite tasks being incomparable in terms of achievable rewards. We show that through constructing an open-ended learning process, which dynamically changes the training task distributions and training objectives such that the agent never stops learning, we achieve consistent learning of new behaviours. The resulting agent is able to score reward in every one of our humanly solvable evaluation levels, with behaviour generalising to many held-out points in the universe of tasks. Examples of this zero-shot generalisation include good performance on Hide and Seek, Capture the Flag, and Tag. Through analysis and hand-authored probe tasks we characterise the behaviour of our agent, and find interesting emergent heuristic behaviours such as trial-and-error experimentation, simple tool use, option switching, and cooperation. Finally, we demonstrate that the general capabilities of this agent could unlock larger scale transfer of behaviour through cheap finetuning.
Energy-based Generative Adversarial Network
Mar 06, 2017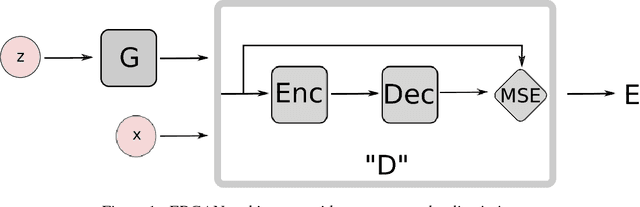

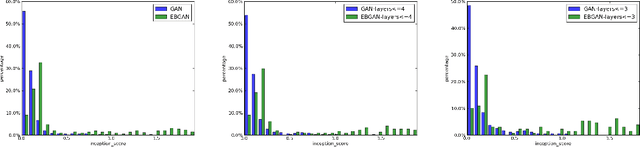

We introduce the "Energy-based Generative Adversarial Network" model (EBGAN) which views the discriminator as an energy function that attributes low energies to the regions near the data manifold and higher energies to other regions. Similar to the probabilistic GANs, a generator is seen as being trained to produce contrastive samples with minimal energies, while the discriminator is trained to assign high energies to these generated samples. Viewing the discriminator as an energy function allows to use a wide variety of architectures and loss functionals in addition to the usual binary classifier with logistic output. Among them, we show one instantiation of EBGAN framework as using an auto-encoder architecture, with the energy being the reconstruction error, in place of the discriminator. We show that this form of EBGAN exhibits more stable behavior than regular GANs during training. We also show that a single-scale architecture can be trained to generate high-resolution images.
Disentangling factors of variation in deep representations using adversarial training
Nov 10, 2016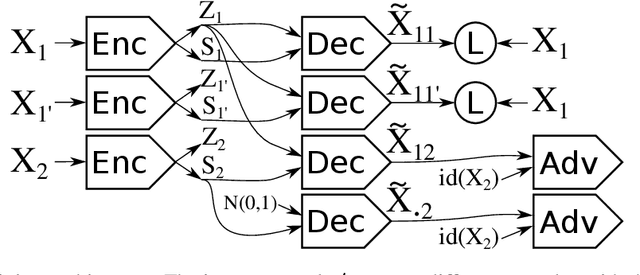



We introduce a conditional generative model for learning to disentangle the hidden factors of variation within a set of labeled observations, and separate them into complementary codes. One code summarizes the specified factors of variation associated with the labels. The other summarizes the remaining unspecified variability. During training, the only available source of supervision comes from our ability to distinguish among different observations belonging to the same class. Examples of such observations include images of a set of labeled objects captured at different viewpoints, or recordings of set of speakers dictating multiple phrases. In both instances, the intra-class diversity is the source of the unspecified factors of variation: each object is observed at multiple viewpoints, and each speaker dictates multiple phrases. Learning to disentangle the specified factors from the unspecified ones becomes easier when strong supervision is possible. Suppose that during training, we have access to pairs of images, where each pair shows two different objects captured from the same viewpoint. This source of alignment allows us to solve our task using existing methods. However, labels for the unspecified factors are usually unavailable in realistic scenarios where data acquisition is not strictly controlled. We address the problem of disentanglement in this more general setting by combining deep convolutional autoencoders with a form of adversarial training. Both factors of variation are implicitly captured in the organization of the learned embedding space, and can be used for solving single-image analogies. Experimental results on synthetic and real datasets show that the proposed method is capable of generalizing to unseen classes and intra-class variabilities.
Video (language) modeling: a baseline for generative models of natural videos
May 04, 2016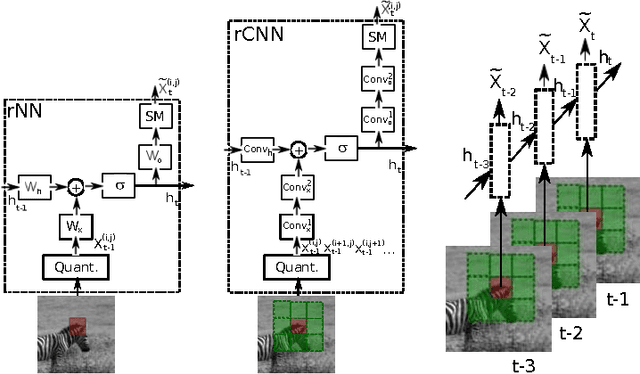



We propose a strong baseline model for unsupervised feature learning using video data. By learning to predict missing frames or extrapolate future frames from an input video sequence, the model discovers both spatial and temporal correlations which are useful to represent complex deformations and motion patterns. The models we propose are largely borrowed from the language modeling literature, and adapted to the vision domain by quantizing the space of image patches into a large dictionary. We demonstrate the approach on both a filling and a generation task. For the first time, we show that, after training on natural videos, such a model can predict non-trivial motions over short video sequences.
Deep multi-scale video prediction beyond mean square error
Feb 26, 2016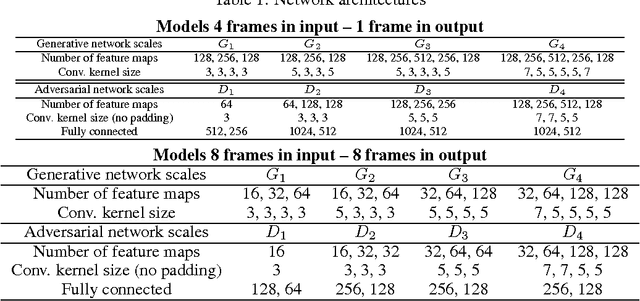
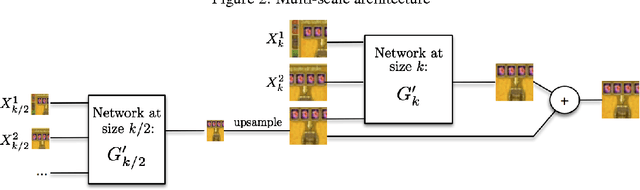
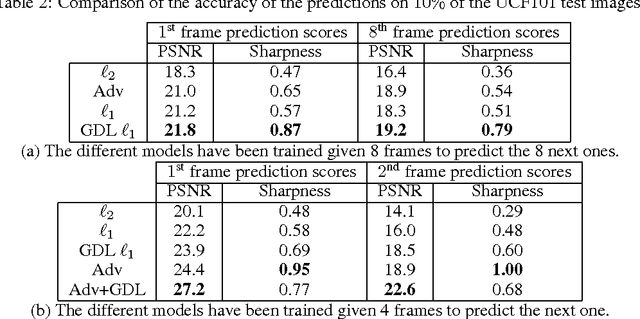

Learning to predict future images from a video sequence involves the construction of an internal representation that models the image evolution accurately, and therefore, to some degree, its content and dynamics. This is why pixel-space video prediction may be viewed as a promising avenue for unsupervised feature learning. In addition, while optical flow has been a very studied problem in computer vision for a long time, future frame prediction is rarely approached. Still, many vision applications could benefit from the knowledge of the next frames of videos, that does not require the complexity of tracking every pixel trajectories. In this work, we train a convolutional network to generate future frames given an input sequence. To deal with the inherently blurry predictions obtained from the standard Mean Squared Error (MSE) loss function, we propose three different and complementary feature learning strategies: a multi-scale architecture, an adversarial training method, and an image gradient difference loss function. We compare our predictions to different published results based on recurrent neural networks on the UCF101 dataset
Stacked What-Where Auto-encoders
Feb 14, 2016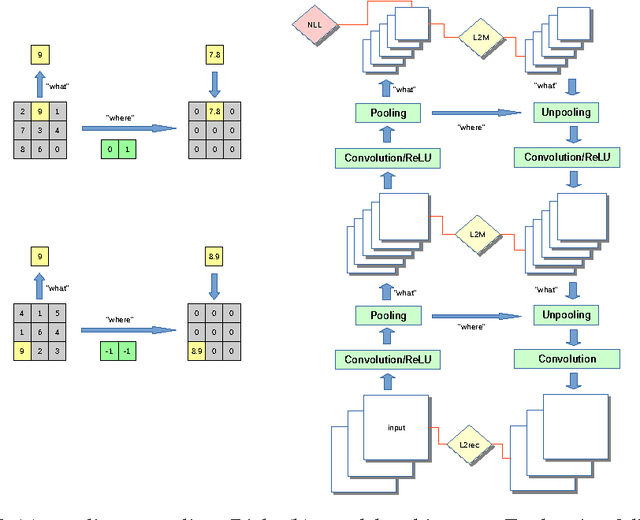



We present a novel architecture, the "stacked what-where auto-encoders" (SWWAE), which integrates discriminative and generative pathways and provides a unified approach to supervised, semi-supervised and unsupervised learning without relying on sampling during training. An instantiation of SWWAE uses a convolutional net (Convnet) (LeCun et al. (1998)) to encode the input, and employs a deconvolutional net (Deconvnet) (Zeiler et al. (2010)) to produce the reconstruction. The objective function includes reconstruction terms that induce the hidden states in the Deconvnet to be similar to those of the Convnet. Each pooling layer produces two sets of variables: the "what" which are fed to the next layer, and its complementary variable "where" that are fed to the corresponding layer in the generative decoder.
Learning to Linearize Under Uncertainty
Sep 10, 2015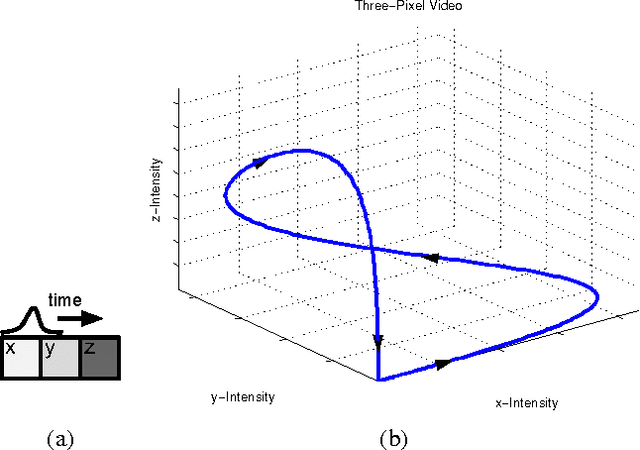
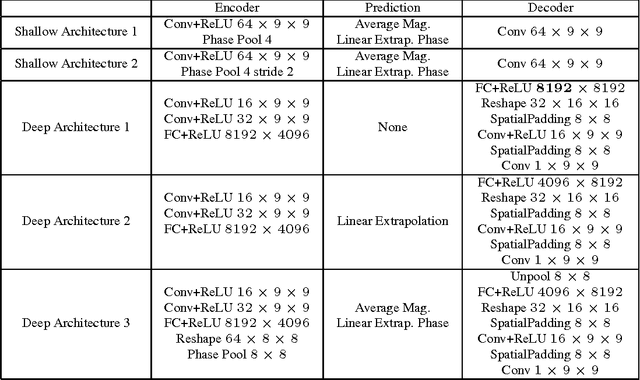
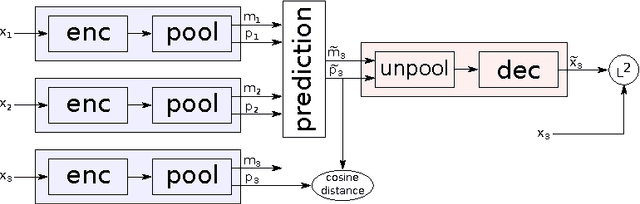

Training deep feature hierarchies to solve supervised learning tasks has achieved state of the art performance on many problems in computer vision. However, a principled way in which to train such hierarchies in the unsupervised setting has remained elusive. In this work we suggest a new architecture and loss for training deep feature hierarchies that linearize the transformations observed in unlabeled natural video sequences. This is done by training a generative model to predict video frames. We also address the problem of inherent uncertainty in prediction by introducing latent variables that are non-deterministic functions of the input into the network architecture.
Learning Longer Memory in Recurrent Neural Networks
Apr 16, 2015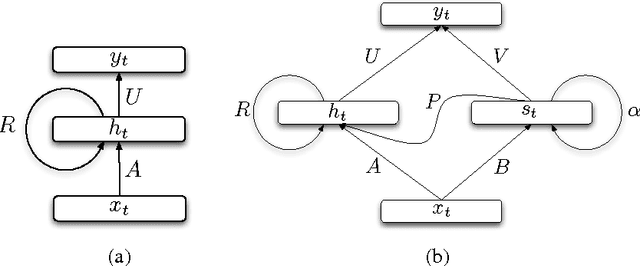
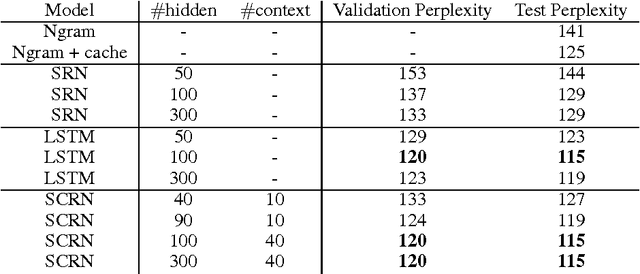
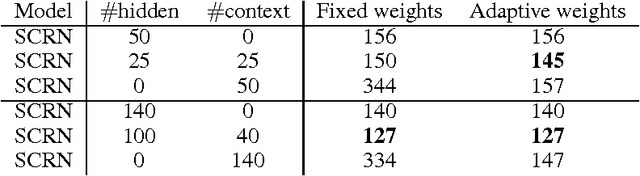
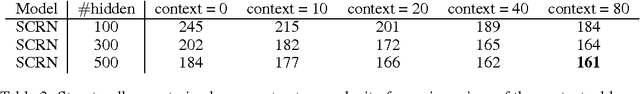
Recurrent neural network is a powerful model that learns temporal patterns in sequential data. For a long time, it was believed that recurrent networks are difficult to train using simple optimizers, such as stochastic gradient descent, due to the so-called vanishing gradient problem. In this paper, we show that learning longer term patterns in real data, such as in natural language, is perfectly possible using gradient descent. This is achieved by using a slight structural modification of the simple recurrent neural network architecture. We encourage some of the hidden units to change their state slowly by making part of the recurrent weight matrix close to identity, thus forming kind of a longer term memory. We evaluate our model in language modeling experiments, where we obtain similar performance to the much more complex Long Short Term Memory (LSTM) networks (Hochreiter & Schmidhuber, 1997).
Fast Convolutional Nets With fbfft: A GPU Performance Evaluation
Apr 10, 2015
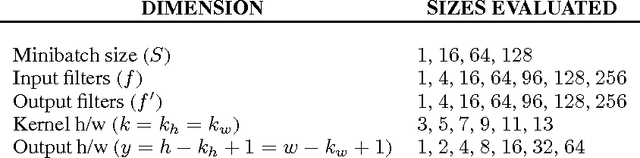
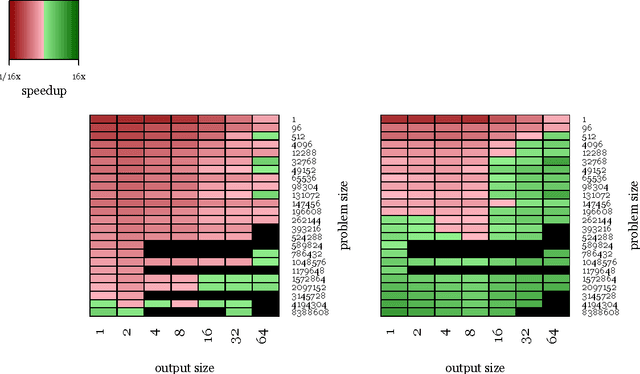
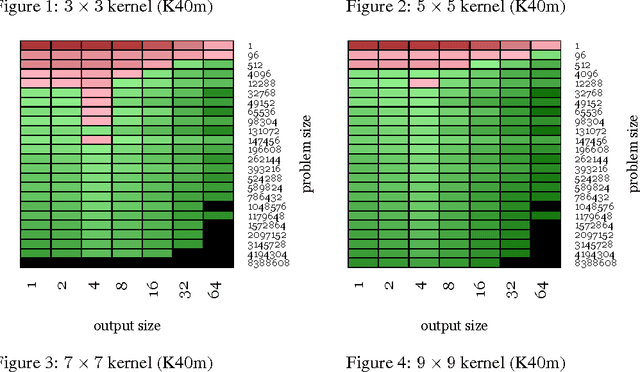
We examine the performance profile of Convolutional Neural Network training on the current generation of NVIDIA Graphics Processing Units. We introduce two new Fast Fourier Transform convolution implementations: one based on NVIDIA's cuFFT library, and another based on a Facebook authored FFT implementation, fbfft, that provides significant speedups over cuFFT (over 1.5x) for whole CNNs. Both of these convolution implementations are available in open source, and are faster than NVIDIA's cuDNN implementation for many common convolutional layers (up to 23.5x for some synthetic kernel configurations). We discuss different performance regimes of convolutions, comparing areas where straightforward time domain convolutions outperform Fourier frequency domain convolutions. Details on algorithmic applications of NVIDIA GPU hardware specifics in the implementation of fbfft are also provided.
The Loss Surfaces of Multilayer Networks
Jan 21, 2015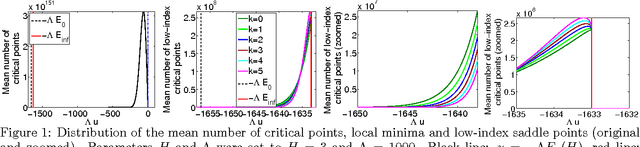

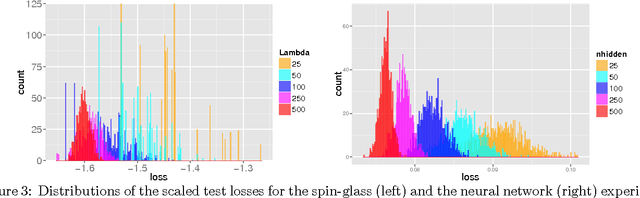
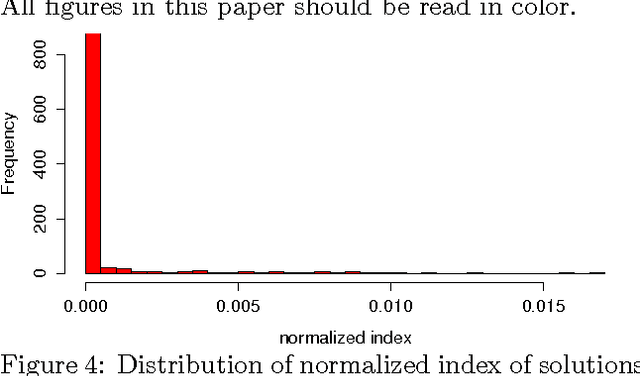
We study the connection between the highly non-convex loss function of a simple model of the fully-connected feed-forward neural network and the Hamiltonian of the spherical spin-glass model under the assumptions of: i) variable independence, ii) redundancy in network parametrization, and iii) uniformity. These assumptions enable us to explain the complexity of the fully decoupled neural network through the prism of the results from random matrix theory. We show that for large-size decoupled networks the lowest critical values of the random loss function form a layered structure and they are located in a well-defined band lower-bounded by the global minimum. The number of local minima outside that band diminishes exponentially with the size of the network. We empirically verify that the mathematical model exhibits similar behavior as the computer simulations, despite the presence of high dependencies in real networks. We conjecture that both simulated annealing and SGD converge to the band of low critical points, and that all critical points found there are local minima of high quality measured by the test error. This emphasizes a major difference between large- and small-size networks where for the latter poor quality local minima have non-zero probability of being recovered. Finally, we prove that recovering the global minimum becomes harder as the network size increases and that it is in practice irrelevant as global minimum often leads to overfitting.