 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Teacher Knowledge Distillation via Teacher-Informed Mixture Priors
May 27, 2026Knowledge distillation is a powerful method for model compression, enabling the efficient deployment of complex deep learning models (teachers), including large language models. However, its underlying statistical mechanisms remain unclear, and uncertainty evaluation is often overlooked, especially in real-world scenarios requiring diverse teacher expertise. To address these challenges, we introduce \textit{Multi-Teacher Bayesian Knowledge Distillation} (MT-BKD), where a distilled student model learns from multiple teachers within the Bayesian framework. Our approach leverages Bayesian inference to capture inherent uncertainty in the distillation process. We introduce a teacher-informed prior, integrating external knowledge from teacher models and task-specific training data, offering better generalization, robustness, and scalability. Additionally, an entropy-based weighting mechanism adaptively adjusts each teacher's influence, allowing the student to combine multiple sources of expertise effectively. MT-BKD enhances the interpretability of the student model's learning process, improves predictive accuracy, and provides uncertainty quantification. We validate MT-BKD on both synthetic and real-world tasks, including protein subcellular location prediction and image classification. Our experiments show improved performance and robust uncertainty quantification, highlighting the strengths of our MT-BKD framework.
Wahkon: A Statistically Principled Deep RKHS Superposition Network
May 13, 2026Deep learning excels at prediction but often lacks finite-sample guarantees and calibrated uncertainty; RKHS (Reproducing Kernel Hilbert Space)-based methods provide those guarantees but struggle to adapt in high dimensions. We propose Wahkon, a deep RKHS superposition network that unifies Kolmogorov's superposition principle with RKHS regularization in the smoothing-spline tradition of Wahba. This yields a finite-dimensional deep representer theorem that makes training tractable and provides explicit layerwise complexity control. We show the penalized estimator is exactly the MAP (maximum a posteriori) estimate under a hierarchical Gaussian-process prior, extending the spline/GP duality to deep compositions. Using metric-entropy arguments, we establish minimax-optimal convergence rates under mild smoothness and clarify how depth and width trade off with regularity. Empirically, Wahkon outperforms multilayer perceptrons, Neural Tangent Kernels, and Kolmogorov--Arnold Networks across simulation benchmarks and a single-cell CITE-seq study. By unifying Kolmogorov's superposition principle with RKHS regularization, Wahkon delivers accuracy, interpretability, and statistical rigor in a single framework.
A Single Revision Step Improves Token-Efficient LLM Reasoning
Feb 02, 2026Large language models (LLMs) achieve higher accuracy on challenging reasoning tasks by scaling test-time compute through multiple trajectory sampling. However, standard aggregation methods like majority voting or individual confidence-based filtering face a fundamental "blind spot": they evaluate each trace in isolation. As problems scale in difficulty, models often generate hallucinated paths that exhibit misleadingly high confidence, causing the true solution to be suppressed by a narrow margin in traditional voting. We ask: can we enable traces to "peer-review" each other to resolve these near-miss errors? We introduce Packet-Conditioned Revision (PACER), a training-free, inference-only framework that enables reasoning traces to revise their conclusions through a structured coordination step. After a preliminary screening of generated traces, PACER constructs a compact consensus packet containing (i) unique candidate answers, (ii) their aggregated confidence scores, and (iii) representative reasoning summaries for each candidate answer. Individual traces then perform a targeted self-review conditioned on this packet, allowing them to identify specific logical junctions where they diverged from the broader consensus and pivot if their original reasoning is found to be flawed. Final predictions are obtained via confidence-weighted voting over these revised trajectories. On challenging competitive math benchmarks such as AIME and BRUMO, PACER matches or exceeds the accuracy of 256-sample majority voting, significantly outperforming raw ensemble baselines by transforming simple consensus into a collaborative logical refinement process.
DCMM-Transformer: Degree-Corrected Mixed-Membership Attention for Medical Imaging
Nov 15, 2025Medical images exhibit latent anatomical groupings, such as organs, tissues, and pathological regions, that standard Vision Transformers (ViTs) fail to exploit. While recent work like SBM-Transformer attempts to incorporate such structures through stochastic binary masking, they suffer from non-differentiability, training instability, and the inability to model complex community structure. We present DCMM-Transformer, a novel ViT architecture for medical image analysis that incorporates a Degree-Corrected Mixed-Membership (DCMM) model as an additive bias in self-attention. Unlike prior approaches that rely on multiplicative masking and binary sampling, our method introduces community structure and degree heterogeneity in a fully differentiable and interpretable manner. Comprehensive experiments across diverse medical imaging datasets, including brain, chest, breast, and ocular modalities, demonstrate the superior performance and generalizability of the proposed approach. Furthermore, the learned group structure and structured attention modulation substantially enhance interpretability by yielding attention maps that are anatomically meaningful and semantically coherent.
S2MNet: Speckle-To-Mesh Net for Three-Dimensional Cardiac Morphology Reconstruction via Echocardiogram
May 09, 2025



Echocardiogram is the most commonly used imaging modality in cardiac assessment duo to its non-invasive nature, real-time capability, and cost-effectiveness. Despite its advantages, most clinical echocardiograms provide only two-dimensional views, limiting the ability to fully assess cardiac anatomy and function in three dimensions. While three-dimensional echocardiography exists, it often suffers from reduced resolution, limited availability, and higher acquisition costs. To overcome these challenges, we propose a deep learning framework S2MNet that reconstructs continuous and high-fidelity 3D heart models by integrating six slices of routinely acquired 2D echocardiogram views. Our method has three advantages. First, our method avoid the difficulties on training data acquasition by simulate six of 2D echocardiogram images from corresponding slices of a given 3D heart mesh. Second, we introduce a deformation field-based method, which avoid spatial discontinuities or structural artifacts in 3D echocardiogram reconstructions. We validate our method using clinically collected echocardiogram and demonstrate that our estimated left ventricular volume, a key clinical indicator of cardiac function, is strongly correlated with the doctor measured GLPS, a clinical measurement that should demonstrate a negative correlation with LVE in medical theory. This association confirms the reliability of our proposed 3D construction method.
Knowledge Distillation and Dataset Distillation of Large Language Models: Emerging Trends, Challenges, and Future Directions
Apr 20, 2025



The exponential growth of Large Language Models (LLMs) continues to highlight the need for efficient strategies to meet ever-expanding computational and data demands. This survey provides a comprehensive analysis of two complementary paradigms: Knowledge Distillation (KD) and Dataset Distillation (DD), both aimed at compressing LLMs while preserving their advanced reasoning capabilities and linguistic diversity. We first examine key methodologies in KD, such as task-specific alignment, rationale-based training, and multi-teacher frameworks, alongside DD techniques that synthesize compact, high-impact datasets through optimization-based gradient matching, latent space regularization, and generative synthesis. Building on these foundations, we explore how integrating KD and DD can produce more effective and scalable compression strategies. Together, these approaches address persistent challenges in model scalability, architectural heterogeneity, and the preservation of emergent LLM abilities. We further highlight applications across domains such as healthcare and education, where distillation enables efficient deployment without sacrificing performance. Despite substantial progress, open challenges remain in preserving emergent reasoning and linguistic diversity, enabling efficient adaptation to continually evolving teacher models and datasets, and establishing comprehensive evaluation protocols. By synthesizing methodological innovations, theoretical foundations, and practical insights, our survey charts a path toward sustainable, resource-efficient LLMs through the tighter integration of KD and DD principles.
Large Language Models for Bioinformatics
Jan 10, 2025
With the rapid advancements in large language model (LLM) technology and the emergence of bioinformatics-specific language models (BioLMs), there is a growing need for a comprehensive analysis of the current landscape, computational characteristics, and diverse applications. This survey aims to address this need by providing a thorough review of BioLMs, focusing on their evolution, classification, and distinguishing features, alongside a detailed examination of training methodologies, datasets, and evaluation frameworks. We explore the wide-ranging applications of BioLMs in critical areas such as disease diagnosis, drug discovery, and vaccine development, highlighting their impact and transformative potential in bioinformatics. We identify key challenges and limitations inherent in BioLMs, including data privacy and security concerns, interpretability issues, biases in training data and model outputs, and domain adaptation complexities. Finally, we highlight emerging trends and future directions, offering valuable insights to guide researchers and clinicians toward advancing BioLMs for increasingly sophisticated biological and clinical applications.
An optimal transport approach for selecting a representative subsample with application in efficient kernel density estimation
May 31, 2022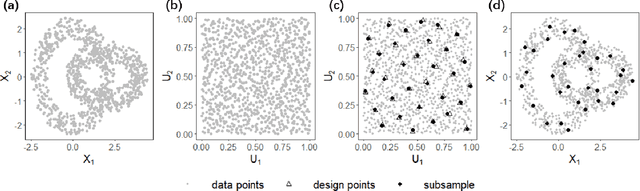
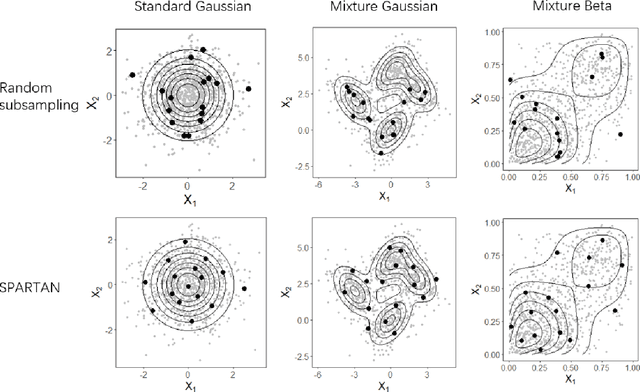
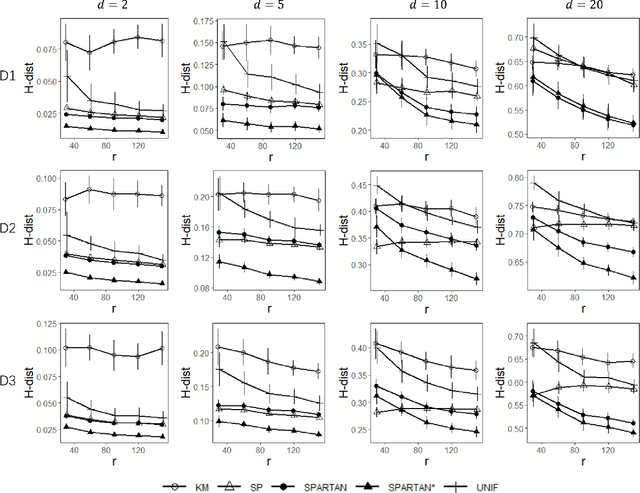
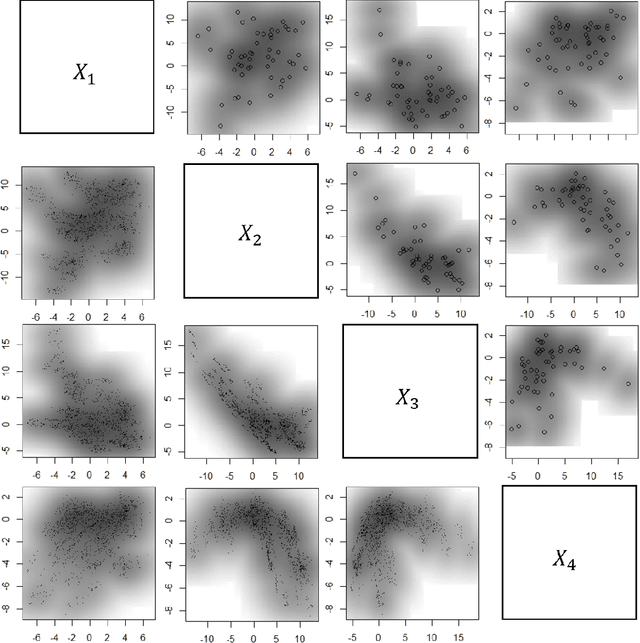
Subsampling methods aim to select a subsample as a surrogate for the observed sample. Such methods have been used pervasively in large-scale data analytics, active learning, and privacy-preserving analysis in recent decades. Instead of model-based methods, in this paper, we study model-free subsampling methods, which aim to identify a subsample that is not confined by model assumptions. Existing model-free subsampling methods are usually built upon clustering techniques or kernel tricks. Most of these methods suffer from either a large computational burden or a theoretical weakness. In particular, the theoretical weakness is that the empirical distribution of the selected subsample may not necessarily converge to the population distribution. Such computational and theoretical limitations hinder the broad applicability of model-free subsampling methods in practice. We propose a novel model-free subsampling method by utilizing optimal transport techniques. Moreover, we develop an efficient subsampling algorithm that is adaptive to the unknown probability density function. Theoretically, we show the selected subsample can be used for efficient density estimation by deriving the convergence rate for the proposed subsample kernel density estimator. We also provide the optimal bandwidth for the proposed estimator. Numerical studies on synthetic and real-world datasets demonstrate the performance of the proposed method is superior.
Large-scale optimal transport map estimation using projection pursuit
Jun 09, 2021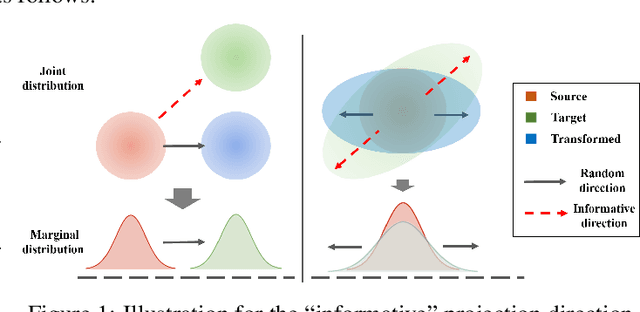

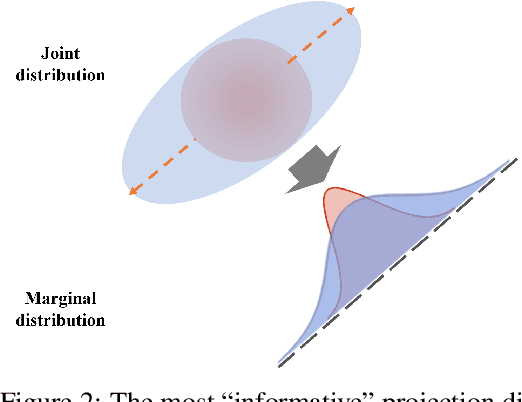

This paper studies the estimation of large-scale optimal transport maps (OTM), which is a well-known challenging problem owing to the curse of dimensionality. Existing literature approximates the large-scale OTM by a series of one-dimensional OTM problems through iterative random projection. Such methods, however, suffer from slow or none convergence in practice due to the nature of randomly selected projection directions. Instead, we propose an estimation method of large-scale OTM by combining the idea of projection pursuit regression and sufficient dimension reduction. The proposed method, named projection pursuit Monge map (PPMM), adaptively selects the most ``informative'' projection direction in each iteration. We theoretically show the proposed dimension reduction method can consistently estimate the most ``informative'' projection direction in each iteration. Furthermore, the PPMM algorithm weakly convergences to the target large-scale OTM in a reasonable number of steps. Empirically, PPMM is computationally easy and converges fast. We assess its finite sample performance through the applications of Wasserstein distance estimation and generative models.
Ensemble machine learning approach for screening of coronary heart disease based on echocardiography and risk factors
May 20, 2021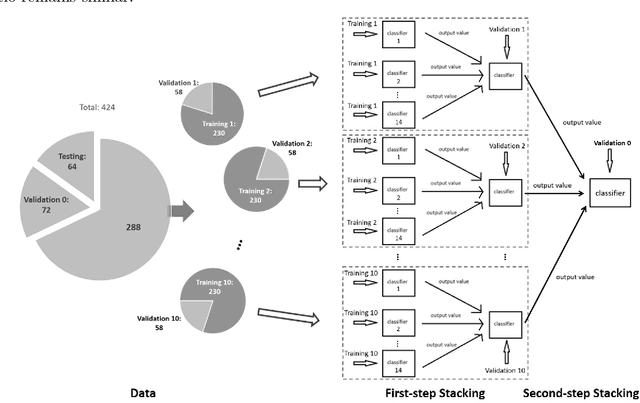
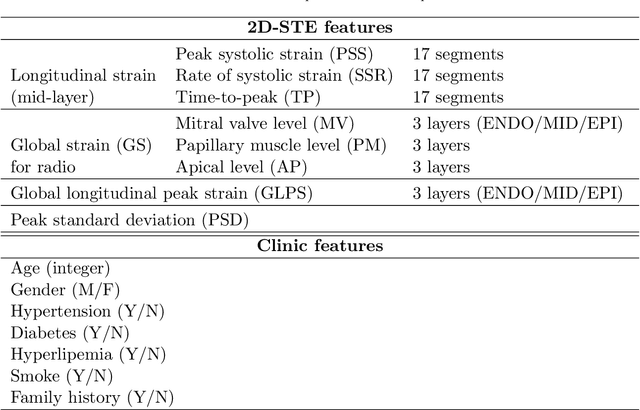
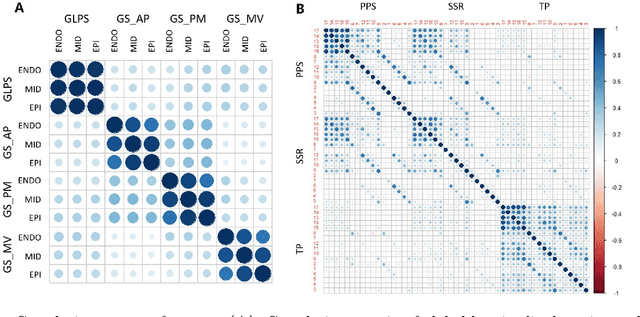
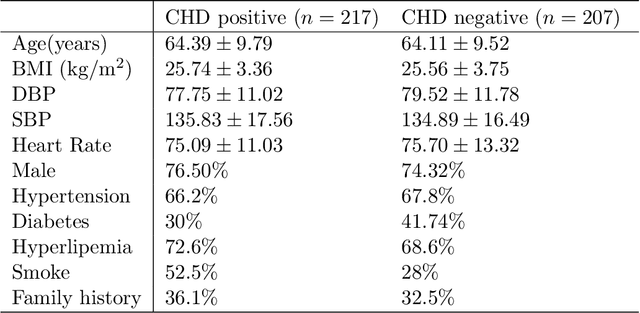
Background: Extensive clinical evidence suggests that a preventive screening of coronary heart disease (CHD) at an earlier stage can greatly reduce the mortality rate. We use 64 two-dimensional speckle tracking echocardiography (2D-STE) features and seven clinical features to predict whether one has CHD. Methods: We develop a machine learning approach that integrates a number of popular classification methods together by model stacking, and generalize the traditional stacking method to a two-step stacking method to improve the diagnostic performance. Results: By borrowing strengths from multiple classification models through the proposed method, we improve the CHD classification accuracy from around 70% to 87.7% on the testing set. The sensitivity of the proposed method is 0.903 and the specificity is 0.843, with an AUC of 0.904, which is significantly higher than those of the individual classification models. Conclusions: Our work lays a foundation for the deployment of speckle tracking echocardiography-based screening tools for coronary heart disease.