 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpokenWOZ: A Large-Scale Speech-Text Benchmark for Spoken Task-Oriented Dialogue in Multiple Domains
May 22, 2023



Task-oriented dialogue (TOD) models have great progress in the past few years. However, these studies primarily focus on datasets written by annotators, which has resulted in a gap between academic research and more realistic spoken conversation scenarios. While a few small-scale spoken TOD datasets are proposed to address robustness issues, e.g., ASR errors, they fail to identify the unique challenges in spoken conversation. To tackle the limitations, we introduce SpokenWOZ, a large-scale speech-text dataset for spoken TOD, which consists of 8 domains, 203k turns, 5.7k dialogues and 249 hours of audios from human-to-human spoken conversations. SpokenWOZ incorporates common spoken characteristics such as word-by-word processing and commonsense reasoning. We also present cross-turn slot and reasoning slot detection as new challenges based on the spoken linguistic phenomena. We conduct comprehensive experiments on various models, including text-modal baselines, newly proposed dual-modal baselines and LLMs. The results show the current models still has substantial areas for improvement in spoken conversation, including fine-tuned models and LLMs, i.e., ChatGPT.
Speech-Text Dialog Pre-training for Spoken Dialog Understanding with Explicit Cross-Modal Alignment
May 19, 2023Recently, speech-text pre-training methods have shown remarkable success in many speech and natural language processing tasks. However, most previous pre-trained models are usually tailored for one or two specific tasks, but fail to conquer a wide range of speech-text tasks. In addition, existing speech-text pre-training methods fail to explore the contextual information within a dialogue to enrich utterance representations. In this paper, we propose Speech-text dialog Pre-training for spoken dialog understanding with ExpliCiT cRoss-Modal Alignment (SPECTRA), which is the first-ever speech-text dialog pre-training model. Concretely, to consider the temporality of speech modality, we design a novel temporal position prediction task to capture the speech-text alignment. This pre-training task aims to predict the start and end time of each textual word in the corresponding speech waveform. In addition, to learn the characteristics of spoken dialogs, we generalize a response selection task from textual dialog pre-training to speech-text dialog pre-training scenarios. Experimental results on four different downstream speech-text tasks demonstrate the superiority of SPECTRA in learning speech-text alignment and multi-turn dialog context.
Gate Recurrent Unit Network based on Hilbert-Schmidt Independence Criterion for State-of-Health Estimation
Mar 16, 2023State-of-health (SOH) estimation is a key step in ensuring the safe and reliable operation of batteries. Due to issues such as varying data distribution and sequence length in different cycles, most existing methods require health feature extraction technique, which can be time-consuming and labor-intensive. GRU can well solve this problem due to the simple structure and superior performance, receiving widespread attentions. However, redundant information still exists within the network and impacts the accuracy of SOH estimation. To address this issue, a new GRU network based on Hilbert-Schmidt Independence Criterion (GRU-HSIC) is proposed. First, a zero masking network is used to transform all battery data measured with varying lengths every cycle into sequences of the same length, while still retaining information about the original data size in each cycle. Second, the Hilbert-Schmidt Independence Criterion (HSIC) bottleneck, which evolved from Information Bottleneck (IB) theory, is extended to GRU to compress the information from hidden layers. To evaluate the proposed method, we conducted experiments on datasets from the Center for Advanced Life Cycle Engineering (CALCE) of the University of Maryland and NASA Ames Prognostics Center of Excellence. Experimental results demonstrate that our model achieves higher accuracy than other recurrent models.
Bilingual Alignment Pre-training for Zero-shot Cross-lingual Transfer
Jun 03, 2021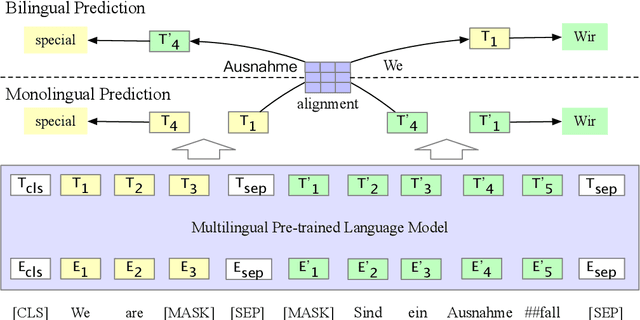
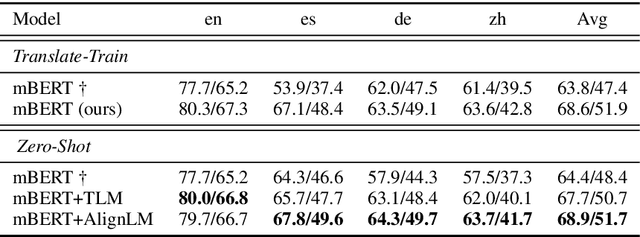
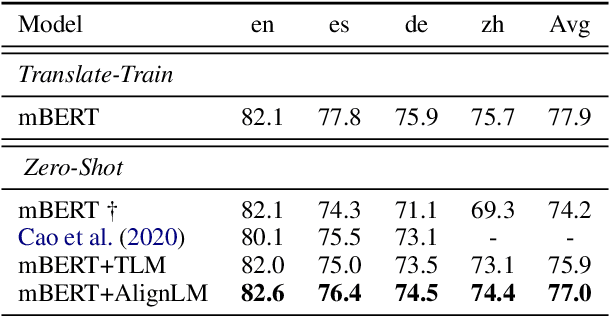
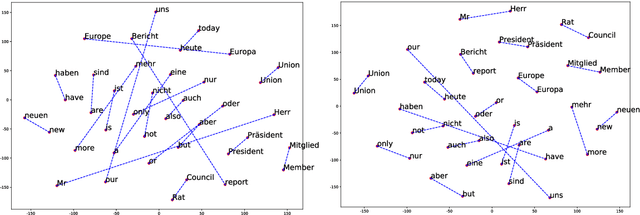
Multilingual pre-trained models have achieved remarkable transfer performance by pre-trained on rich kinds of languages. Most of the models such as mBERT are pre-trained on unlabeled corpora. The static and contextual embeddings from the models could not be aligned very well. In this paper, we aim to improve the zero-shot cross-lingual transfer performance by aligning the embeddings better. We propose a pre-training task named Alignment Language Model (AlignLM), which uses the statistical alignment information as the prior knowledge to guide bilingual word prediction. We evaluate our method on multilingual machine reading comprehension and natural language interface tasks. The results show AlignLM can improve the zero-shot performance significantly on MLQA and XNLI datasets.
CharBERT: Character-aware Pre-trained Language Model
Nov 03, 2020
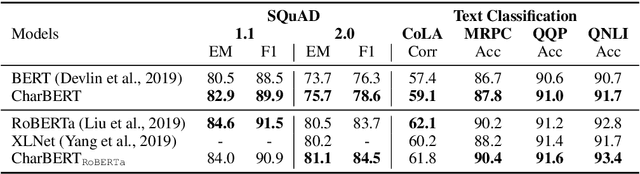
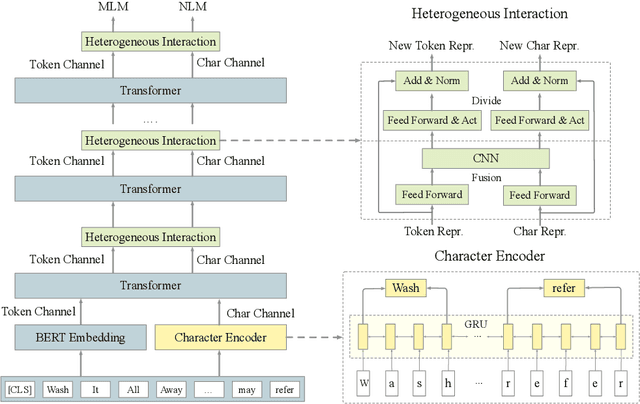
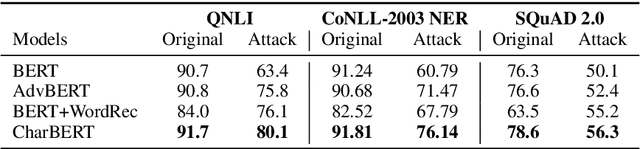
Most pre-trained language models (PLMs) construct word representations at subword level with Byte-Pair Encoding (BPE) or its variations, by which OOV (out-of-vocab) words are almost avoidable. However, those methods split a word into subword units and make the representation incomplete and fragile. In this paper, we propose a character-aware pre-trained language model named CharBERT improving on the previous methods (such as BERT, RoBERTa) to tackle these problems. We first construct the contextual word embedding for each token from the sequential character representations, then fuse the representations of characters and the subword representations by a novel heterogeneous interaction module. We also propose a new pre-training task named NLM (Noisy LM) for unsupervised character representation learning. We evaluate our method on question answering, sequence labeling, and text classification tasks, both on the original datasets and adversarial misspelling test sets. The experimental results show that our method can significantly improve the performance and robustness of PLMs simultaneously. Pretrained models, evaluation sets, and code are available at https://github.com/wtma/CharBERT
Benchmarking Robustness of Machine Reading Comprehension Models
Apr 29, 2020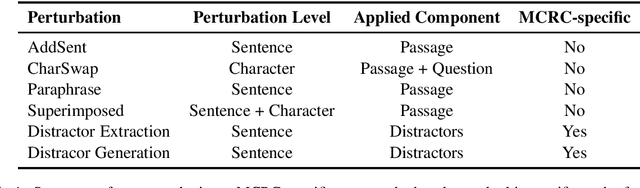
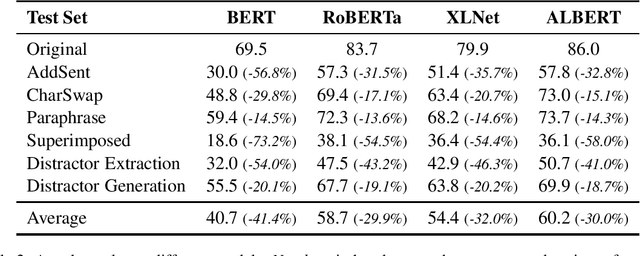
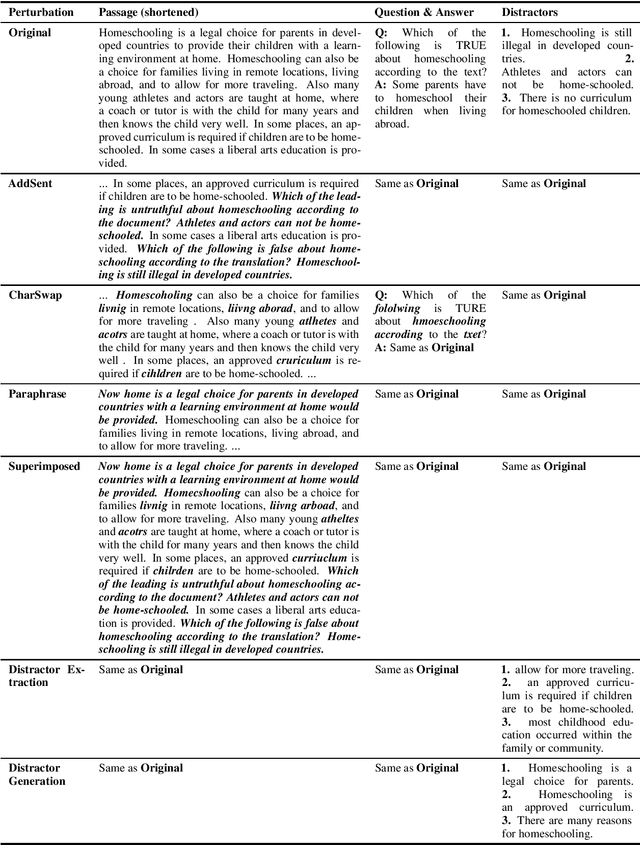
Machine Reading Comprehension (MRC) is an important testbed for evaluating models' natural language understanding (NLU) ability. There has been rapid progress in this area, with new models achieving impressive performance on various MRC benchmarks. However, most of these benchmarks only evaluate models on in-domain test sets without considering their robustness under test-time perturbations. To fill this important gap, we construct AdvRACE (Adversarial RACE), a new model-agnostic benchmark for evaluating the robustness of MRC models under six different types of test-time perturbations, including our novel superimposed attack and distractor construction attack. We show that current state-of-the-art (SOTA) models are vulnerable to these simple black-box attacks. Our benchmark is constructed automatically based on the existing RACE benchmark, and thus the construction pipeline can be easily adopted by other tasks and datasets. We will release the data and source codes to facilitate future work. We hope that our work will encourage more research on improving the robustness of MRC and other NLU models.
Conversational Word Embedding for Retrieval-Based Dialog System
Apr 28, 2020
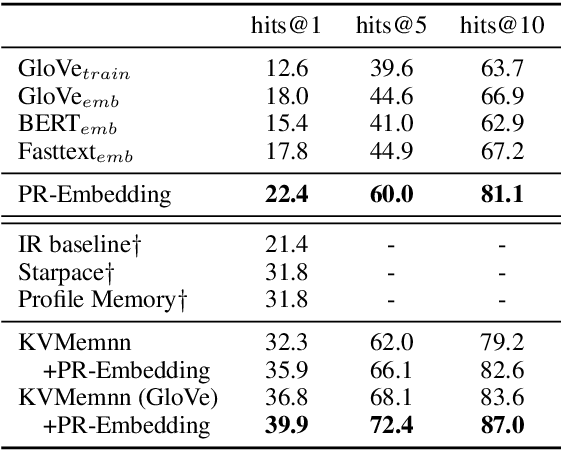
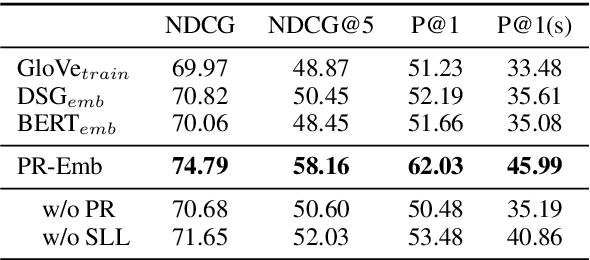
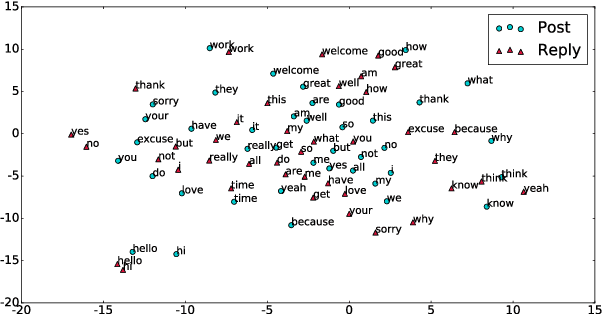
Human conversations contain many types of information, e.g., knowledge, common sense, and language habits. In this paper, we propose a conversational word embedding method named PR-Embedding, which utilizes the conversation pairs $ \left\langle{post, reply} \right\rangle$ to learn word embedding. Different from previous works, PR-Embedding uses the vectors from two different semantic spaces to represent the words in post and reply. To catch the information among the pair, we first introduce the word alignment model from statistical machine translation to generate the cross-sentence window, then train the embedding on word-level and sentence-level. We evaluate the method on single-turn and multi-turn response selection tasks for retrieval-based dialog systems. The experiment results show that PR-Embedding can improve the quality of the selected response. PR-Embedding source code is available at https://github.com/wtma/PR-Embedding
A Sentence Cloze Dataset for Chinese Machine Reading Comprehension
Apr 07, 2020
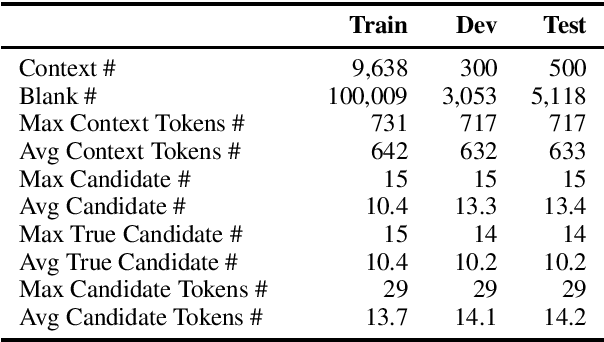
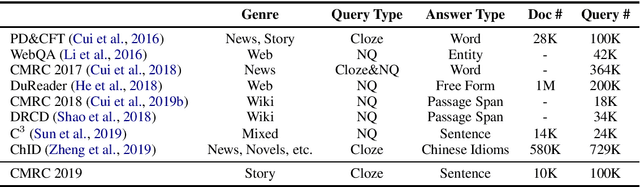
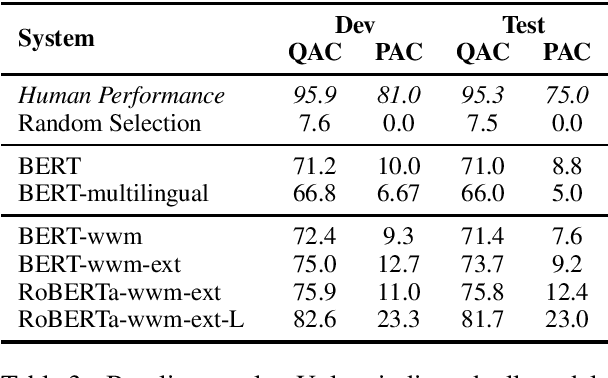
Owing to the continuous contributions by the Chinese NLP community, more and more Chinese machine reading comprehension datasets become available, and they have been pushing Chinese MRC research forward. To add diversity in this area, in this paper, we propose a new task called Sentence Cloze-style Machine Reading Comprehension (SC-MRC). The proposed task aims to fill the right candidate sentence into the passage that has several blanks. Moreover, to add more difficulties, we also made fake candidates that are similar to the correct ones, which requires the machine to judge their correctness in the context. The proposed dataset contains over 100K blanks (questions) within over 10K passages, which was originated from Chinese narrative stories. To evaluate the dataset, we implement several baseline systems based on pre-trained models, and the results show that the state-of-the-art model still underperforms human performance by a large margin. We hope the release of the dataset could further accelerate the machine reading comprehension research. Resources available: https://github.com/ymcui/cmrc2019
CJRC: A Reliable Human-Annotated Benchmark DataSet for Chinese Judicial Reading Comprehension
Dec 19, 2019
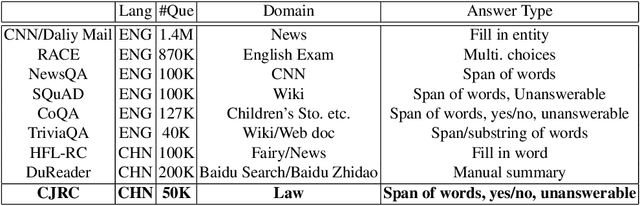

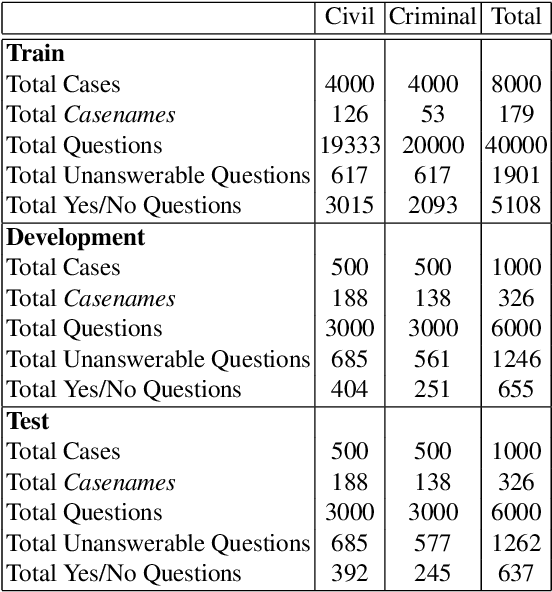
We present a Chinese judicial reading comprehension (CJRC) dataset which contains approximately 10K documents and almost 50K questions with answers. The documents come from judgment documents and the questions are annotated by law experts. The CJRC dataset can help researchers extract elements by reading comprehension technology. Element extraction is an important task in the legal field. However, it is difficult to predefine the element types completely due to the diversity of document types and causes of action. By contrast, machine reading comprehension technology can quickly extract elements by answering various questions from the long document. We build two strong baseline models based on BERT and BiDAF. The experimental results show that there is enough space for improvement compared to human annotators.
TripleNet: Triple Attention Network for Multi-Turn Response Selection in Retrieval-based Chatbots
Sep 29, 2019
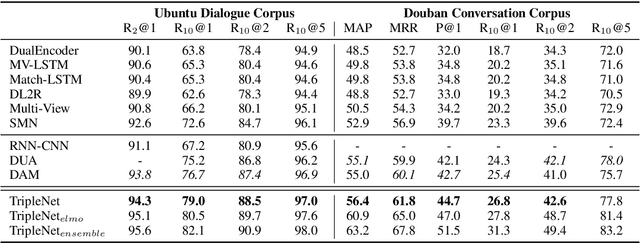
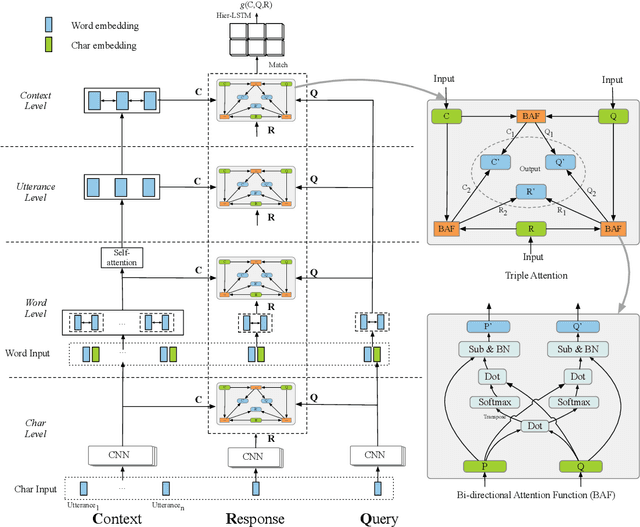

We consider the importance of different utterances in the context for selecting the response usually depends on the current query. In this paper, we propose the model TripleNet to fully model the task with the triple <context, query, response> instead of <context, response> in previous works. The heart of TripleNet is a novel attention mechanism named triple attention to model the relationships within the triple at four levels. The new mechanism updates the representation for each element based on the attention with the other two concurrently and symmetrically. We match the triple <C, Q, R> centered on the response from char to context level for prediction. Experimental results on two large-scale multi-turn response selection datasets show that the proposed model can significantly outperform the state-of-the-art methods. TripleNet source code is available at https://github.com/wtma/TripleNet