 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA AI Aerial: AI-Native Wireless Communications
Oct 02, 2025



6G brings a paradigm shift towards AI-native wireless systems, necessitating the seamless integration of digital signal processing (DSP) and machine learning (ML) within the software stacks of cellular networks. This transformation brings the life cycle of modern networks closer to AI systems, where models and algorithms are iteratively trained, simulated, and deployed across adjacent environments. In this work, we propose a robust framework that compiles Python-based algorithms into GPU-runnable blobs. The result is a unified approach that ensures efficiency, flexibility, and the highest possible performance on NVIDIA GPUs. As an example of the capabilities of the framework, we demonstrate the efficacy of performing the channel estimation function in the PUSCH receiver through a convolutional neural network (CNN) trained in Python. This is done in a digital twin first, and subsequently in a real-time testbed. Our proposed methodology, realized in the NVIDIA AI Aerial platform, lays the foundation for scalable integration of AI/ML models into next-generation cellular systems, and is essential for realizing the vision of natively intelligent 6G networks.
Tool-R1: Sample-Efficient Reinforcement Learning for Agentic Tool Use
Sep 16, 2025Large language models (LLMs) have demonstrated strong capabilities in language understanding and reasoning, yet they remain limited when tackling real-world tasks that require up-to-date knowledge, precise operations, or specialized tool use. To address this, we propose Tool-R1, a reinforcement learning framework that enables LLMs to perform general, compositional, and multi-step tool use by generating executable Python code. Tool-R1 supports integration of user-defined tools and standard libraries, with variable sharing across steps to construct coherent workflows. An outcome-based reward function, combining LLM-based answer judgment and code execution success, guides policy optimization. To improve training efficiency, we maintain a dynamic sample queue to cache and reuse high-quality trajectories, reducing the overhead of costly online sampling. Experiments on the GAIA benchmark show that Tool-R1 substantially improves both accuracy and robustness, achieving about 10\% gain over strong baselines, with larger improvements on complex multi-step tasks. These results highlight the potential of Tool-R1 for enabling reliable and efficient tool-augmented reasoning in real-world applications. Our code will be available at https://github.com/YBYBZhang/Tool-R1.
CoMeDi Shared Task: Models as Annotators in Lexical Semantics Disagreements
Nov 19, 2024



We present the results of our system for the CoMeDi Shared Task, which predicts majority votes (Subtask 1) and annotator disagreements (Subtask 2). Our approach combines model ensemble strategies with MLP-based and threshold-based methods trained on pretrained language models. Treating individual models as virtual annotators, we simulate the annotation process by designing aggregation measures that incorporate continuous similarity scores and discrete classification labels to capture both majority and disagreement. Additionally, we employ anisotropy removal techniques to enhance performance. Experimental results demonstrate the effectiveness of our methods, particularly for Subtask 2. Notably, we find that continuous similarity scores, even within the same model, align better with human disagreement patterns compared to aggregated discrete labels.
Uncertainty Quantification in Machine Learning for Engineering Design and Health Prognostics: A Tutorial
May 07, 2023



On top of machine learning models, uncertainty quantification (UQ) functions as an essential layer of safety assurance that could lead to more principled decision making by enabling sound risk assessment and management. The safety and reliability improvement of ML models empowered by UQ has the potential to significantly facilitate the broad adoption of ML solutions in high-stakes decision settings, such as healthcare, manufacturing, and aviation, to name a few. In this tutorial, we aim to provide a holistic lens on emerging UQ methods for ML models with a particular focus on neural networks and the applications of these UQ methods in tackling engineering design as well as prognostics and health management problems. Toward this goal, we start with a comprehensive classification of uncertainty types, sources, and causes pertaining to UQ of ML models. Next, we provide a tutorial-style description of several state-of-the-art UQ methods: Gaussian process regression, Bayesian neural network, neural network ensemble, and deterministic UQ methods focusing on spectral-normalized neural Gaussian process. Established upon the mathematical formulations, we subsequently examine the soundness of these UQ methods quantitatively and qualitatively (by a toy regression example) to examine their strengths and shortcomings from different dimensions. Then, we review quantitative metrics commonly used to assess the quality of predictive uncertainty in classification and regression problems. Afterward, we discuss the increasingly important role of UQ of ML models in solving challenging problems in engineering design and health prognostics. Two case studies with source codes available on GitHub are used to demonstrate these UQ methods and compare their performance in the life prediction of lithium-ion batteries at the early stage and the remaining useful life prediction of turbofan engines.
A Comprehensive Review of Digital Twin -- Part 2: Roles of Uncertainty Quantification and Optimization, a Battery Digital Twin, and Perspectives
Aug 27, 2022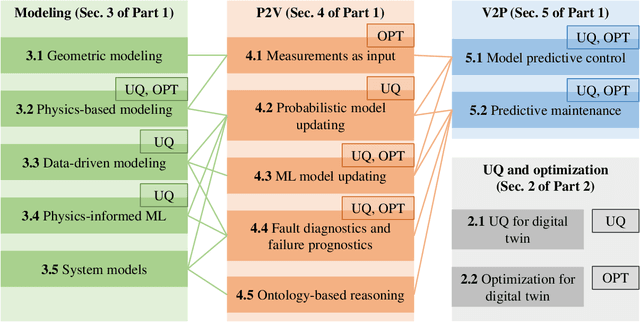
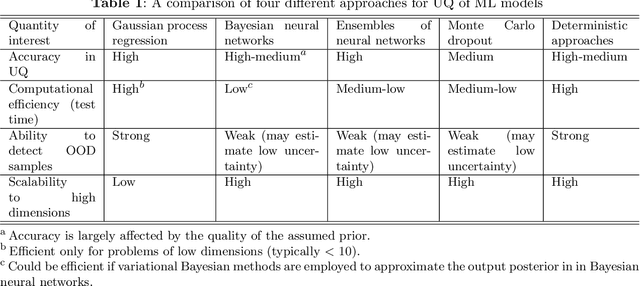
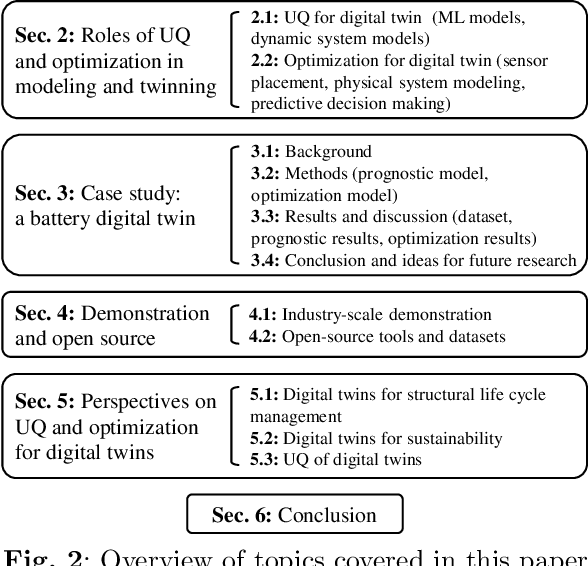
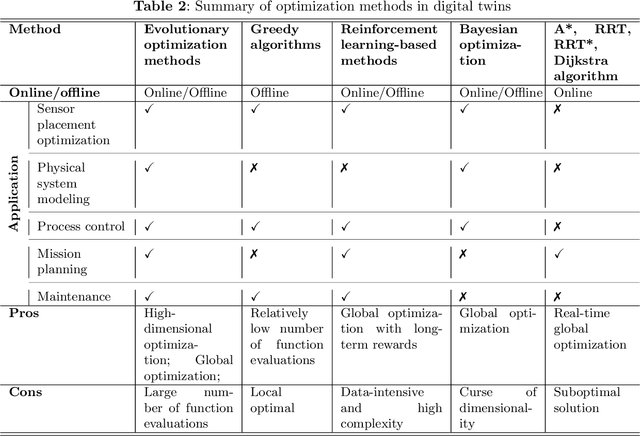
As an emerging technology in the era of Industry 4.0, digital twin is gaining unprecedented attention because of its promise to further optimize process design, quality control, health monitoring, decision and policy making, and more, by comprehensively modeling the physical world as a group of interconnected digital models. In a two-part series of papers, we examine the fundamental role of different modeling techniques, twinning enabling technologies, and uncertainty quantification and optimization methods commonly used in digital twins. This second paper presents a literature review of key enabling technologies of digital twins, with an emphasis on uncertainty quantification, optimization methods, open source datasets and tools, major findings, challenges, and future directions. Discussions focus on current methods of uncertainty quantification and optimization and how they are applied in different dimensions of a digital twin. Additionally, this paper presents a case study where a battery digital twin is constructed and tested to illustrate some of the modeling and twinning methods reviewed in this two-part review. Code and preprocessed data for generating all the results and figures presented in the case study are available on GitHub.
A Comprehensive Review of Digital Twin -- Part 1: Modeling and Twinning Enabling Technologies
Aug 26, 2022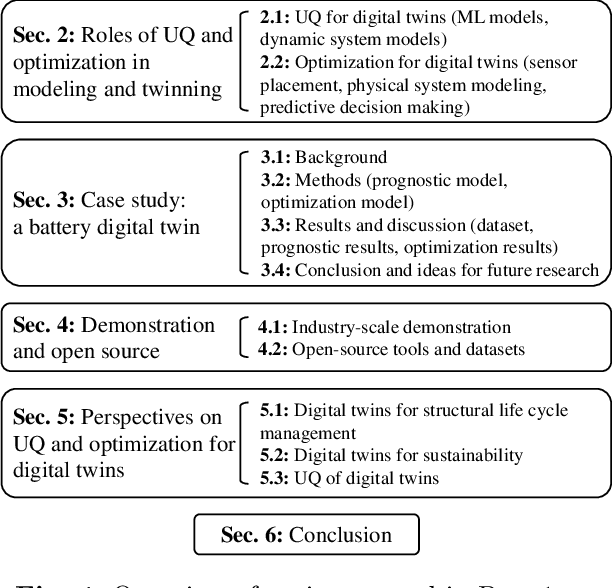
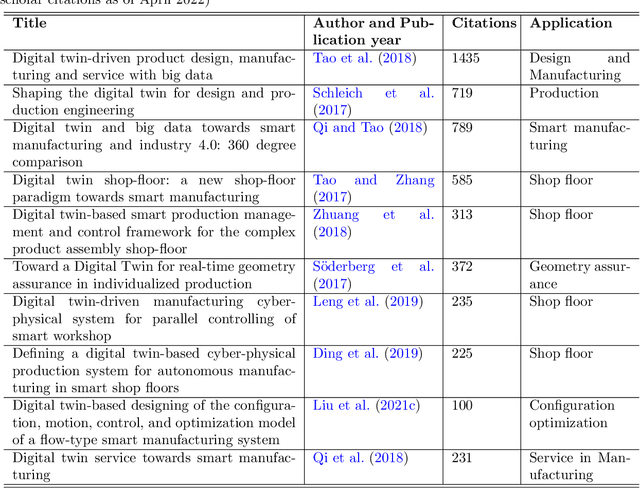
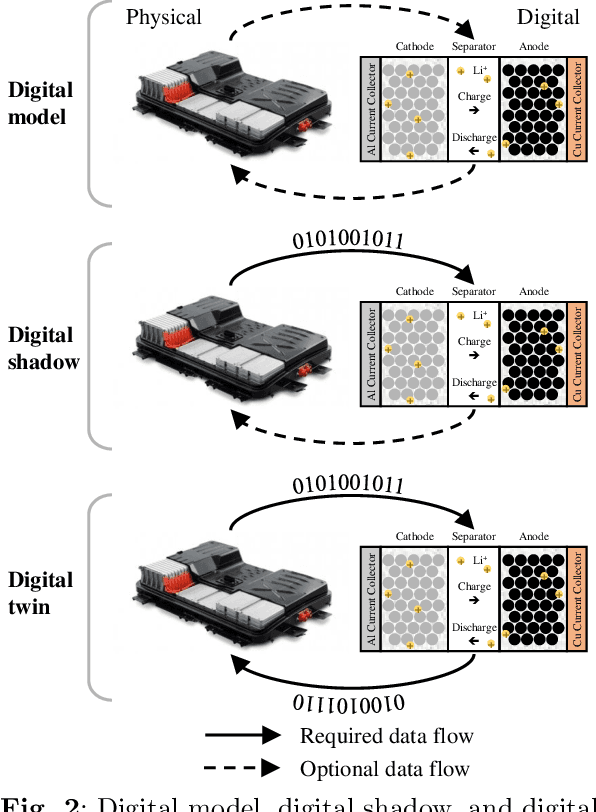
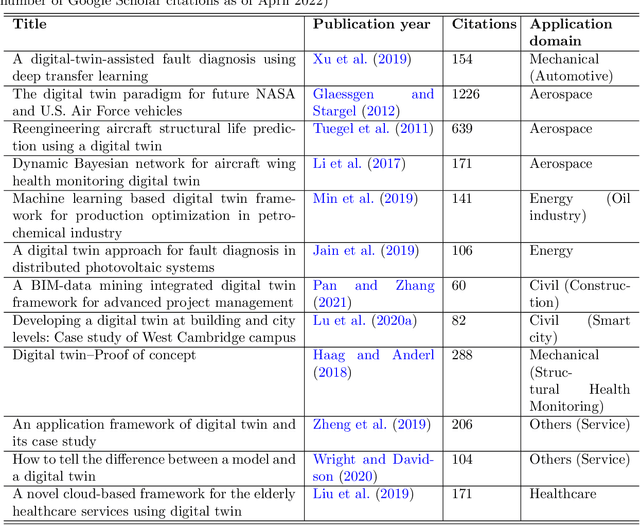
As an emerging technology in the era of Industry 4.0, digital twin is gaining unprecedented attention because of its promise to further optimize process design, quality control, health monitoring, decision and policy making, and more, by comprehensively modeling the physical world as a group of interconnected digital models. In a two-part series of papers, we examine the fundamental role of different modeling techniques, twinning enabling technologies, and uncertainty quantification and optimization methods commonly used in digital twins. This first paper presents a thorough literature review of digital twin trends across many disciplines currently pursuing this area of research. Then, digital twin modeling and twinning enabling technologies are further analyzed by classifying them into two main categories: physical-to-virtual, and virtual-to-physical, based on the direction in which data flows. Finally, this paper provides perspectives on the trajectory of digital twin technology over the next decade, and introduces a few emerging areas of research which will likely be of great use in future digital twin research. In part two of this review, the role of uncertainty quantification and optimization are discussed, a battery digital twin is demonstrated, and more perspectives on the future of digital twin are shared.
Deep Transfer Convolutional Neural Network and Extreme Learning Machine for Lung Nodule Diagnosis on CT images
Jan 05, 2020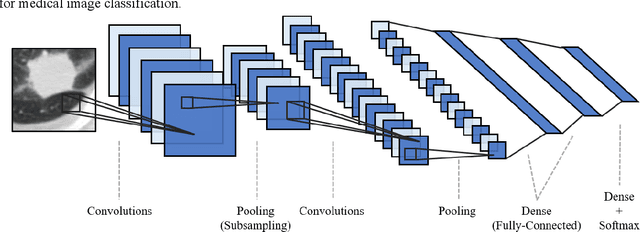
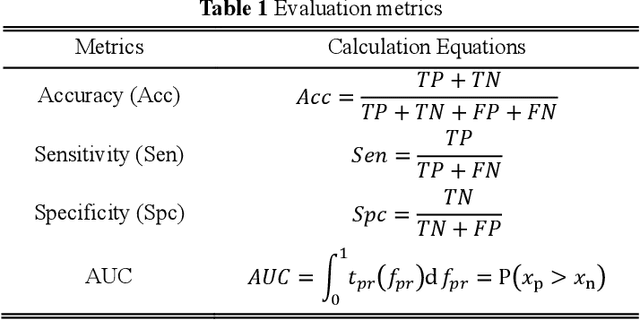
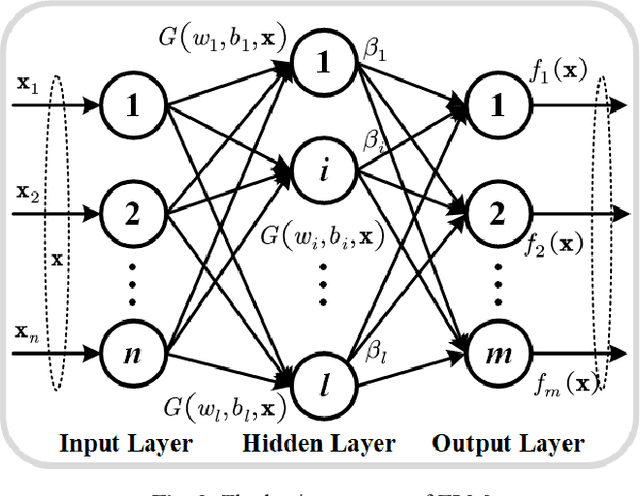
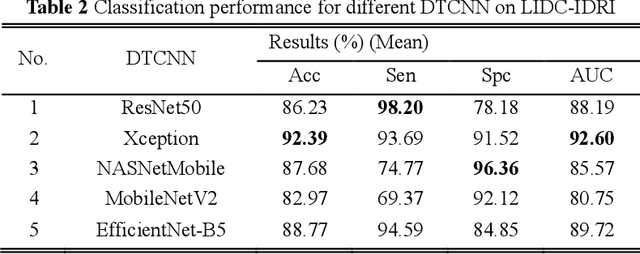
Diagnosis of benign-malignant nodules in the lung on Computed Tomography (CT) images is critical for determining tumor level and reducing patient mortality. Deep learning-based diagnosis of nodules in lung CT images, however, is time-consuming and less accurate due to redundant structure and the lack of adequate training data. In this paper, a novel diagnosis method based on Deep Transfer Convolutional Neural Network (DTCNN) and Extreme Learning Machine (ELM) is explored, which merges the synergy of two algorithms to deal with benign-malignant nodules classification. An optimal DTCNN is first adopted to extract high level features of lung nodules, which has been trained with the ImageNet dataset beforehand. After that, an ELM classifier is further developed to classify benign and malignant lung nodules. Two datasets, including the Lung Image Database Consortium and Image Database Resource Initiative (LIDC-IDRI) public dataset and a private dataset from the First Affiliated Hospital of Guangzhou Medical University in China (FAH-GMU), have been conducted to verify the efficiency and effectiveness of the proposed approach. The experimental results show that our novel DTCNN-ELM model provides the most reliable results compared with current state-of-the-art methods.
CJRC: A Reliable Human-Annotated Benchmark DataSet for Chinese Judicial Reading Comprehension
Dec 19, 2019
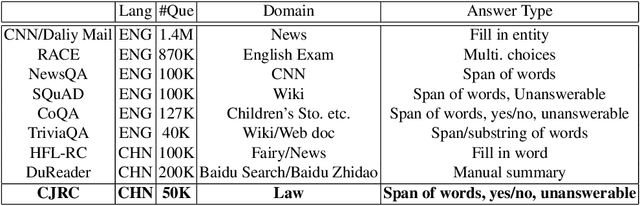

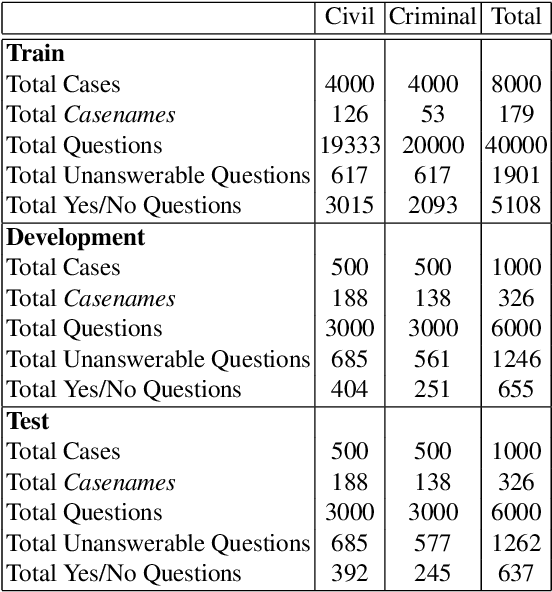
We present a Chinese judicial reading comprehension (CJRC) dataset which contains approximately 10K documents and almost 50K questions with answers. The documents come from judgment documents and the questions are annotated by law experts. The CJRC dataset can help researchers extract elements by reading comprehension technology. Element extraction is an important task in the legal field. However, it is difficult to predefine the element types completely due to the diversity of document types and causes of action. By contrast, machine reading comprehension technology can quickly extract elements by answering various questions from the long document. We build two strong baseline models based on BERT and BiDAF. The experimental results show that there is enough space for improvement compared to human annotators.
CAIL2019-SCM: A Dataset of Similar Case Matching in Legal Domain
Nov 25, 2019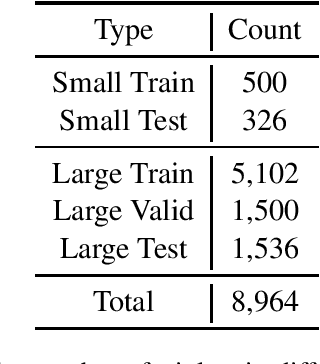
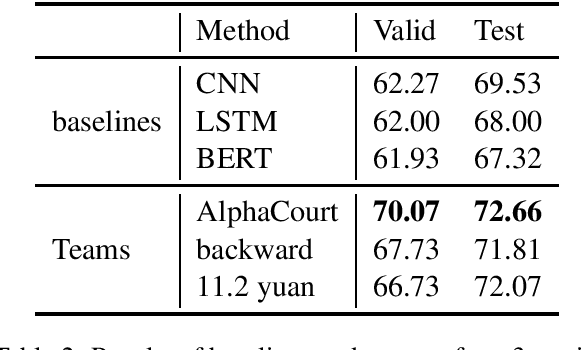
In this paper, we introduce CAIL2019-SCM, Chinese AI and Law 2019 Similar Case Matching dataset. CAIL2019-SCM contains 8,964 triplets of cases published by the Supreme People's Court of China. CAIL2019-SCM focuses on detecting similar cases, and the participants are required to check which two cases are more similar in the triplets. There are 711 teams who participated in this year's competition, and the best team has reached a score of 71.88. We have also implemented several baselines to help researchers better understand this task. The dataset and more details can be found from https://github.com/china-ai-law-challenge/CAIL2019/tree/master/scm.
Overview of CAIL2018: Legal Judgment Prediction Competition
Oct 13, 2018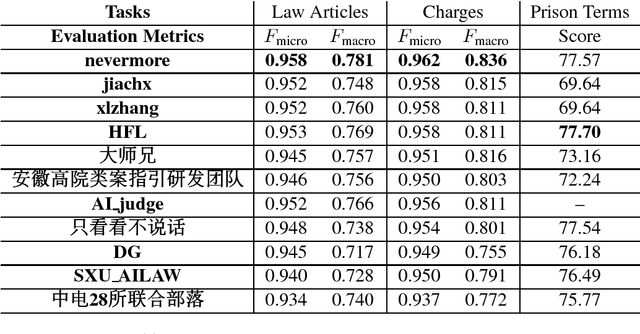
In this paper, we give an overview of the Legal Judgment Prediction (LJP) competition at Chinese AI and Law challenge (CAIL2018). This competition focuses on LJP which aims to predict the judgment results according to the given facts. Specifically, in CAIL2018 , we proposed three subtasks of LJP for the contestants, i.e., predicting relevant law articles, charges and prison terms given the fact descriptions. CAIL2018 has attracted several hundreds participants (601 teams, 1, 144 contestants from 269 organizations). In this paper, we provide a detailed overview of the task definition, related works, outstanding methods and competition results in CAIL2018.