 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFood-R1: A Unified Multi-Task Food Vision-Language Model with Reinforcement Learning
Jun 03, 2026Recent studies have explored Vision-Language Models (VLMs) for food analysis. However, most existing methods rely primarily on supervised fine-tuning (SFT), which often limits reasoning and generalization capabilities. Moreover, high-quality large-scale nutritional annotations remain scarce. To address these issues, we introduce CalorieBench-80K, a large-scale benchmark with curated calorie labels and dietary advice annotations. To the best of our knowledge, it is the first food image benchmark to incorporate Chain-of-Thought (CoT) annotations for calorie reasoning. We also propose Food-R1, a unified food VLM trained in a multi-task learning paradigm to equip the model with broad capabilities. Food-R1 undergoes CoT-based cold-start instruction tuning, followed by reinforcement fine-tuning (RFT) using Group Relative Policy Optimization (GRPO) to improve reasoning and performance. Experiments on CalorieBench-80K and representative benchmarks show that Food-R1 consistently outperforms strong baselines across food-related tasks. The code, model weights, and benchmark annotations are available at the project repository.
XMusic: Towards a Generalized and Controllable Symbolic Music Generation Framework
Jan 15, 2025



In recent years, remarkable advancements in artificial intelligence-generated content (AIGC) have been achieved in the fields of image synthesis and text generation, generating content comparable to that produced by humans. However, the quality of AI-generated music has not yet reached this standard, primarily due to the challenge of effectively controlling musical emotions and ensuring high-quality outputs. This paper presents a generalized symbolic music generation framework, XMusic, which supports flexible prompts (i.e., images, videos, texts, tags, and humming) to generate emotionally controllable and high-quality symbolic music. XMusic consists of two core components, XProjector and XComposer. XProjector parses the prompts of various modalities into symbolic music elements (i.e., emotions, genres, rhythms and notes) within the projection space to generate matching music. XComposer contains a Generator and a Selector. The Generator generates emotionally controllable and melodious music based on our innovative symbolic music representation, whereas the Selector identifies high-quality symbolic music by constructing a multi-task learning scheme involving quality assessment, emotion recognition, and genre recognition tasks. In addition, we build XMIDI, a large-scale symbolic music dataset that contains 108,023 MIDI files annotated with precise emotion and genre labels. Objective and subjective evaluations show that XMusic significantly outperforms the current state-of-the-art methods with impressive music quality. Our XMusic has been awarded as one of the nine Highlights of Collectibles at WAIC 2023. The project homepage of XMusic is https://xmusic-project.github.io.
LAPT: Label-driven Automated Prompt Tuning for OOD Detection with Vision-Language Models
Jul 12, 2024Out-of-distribution (OOD) detection is crucial for model reliability, as it identifies samples from unknown classes and reduces errors due to unexpected inputs. Vision-Language Models (VLMs) such as CLIP are emerging as powerful tools for OOD detection by integrating multi-modal information. However, the practical application of such systems is challenged by manual prompt engineering, which demands domain expertise and is sensitive to linguistic nuances. In this paper, we introduce Label-driven Automated Prompt Tuning (LAPT), a novel approach to OOD detection that reduces the need for manual prompt engineering. We develop distribution-aware prompts with in-distribution (ID) class names and negative labels mined automatically. Training samples linked to these class labels are collected autonomously via image synthesis and retrieval methods, allowing for prompt learning without manual effort. We utilize a simple cross-entropy loss for prompt optimization, with cross-modal and cross-distribution mixing strategies to reduce image noise and explore the intermediate space between distributions, respectively. The LAPT framework operates autonomously, requiring only ID class names as input and eliminating the need for manual intervention. With extensive experiments, LAPT consistently outperforms manually crafted prompts, setting a new standard for OOD detection. Moreover, LAPT not only enhances the distinction between ID and OOD samples, but also improves the ID classification accuracy and strengthens the generalization robustness to covariate shifts, resulting in outstanding performance in challenging full-spectrum OOD detection tasks. Codes are available at \url{https://github.com/YBZh/LAPT}.
Dual Memory Networks: A Versatile Adaptation Approach for Vision-Language Models
Mar 26, 2024With the emergence of pre-trained vision-language models like CLIP, how to adapt them to various downstream classification tasks has garnered significant attention in recent research. The adaptation strategies can be typically categorized into three paradigms: zero-shot adaptation, few-shot adaptation, and the recently-proposed training-free few-shot adaptation. Most existing approaches are tailored for a specific setting and can only cater to one or two of these paradigms. In this paper, we introduce a versatile adaptation approach that can effectively work under all three settings. Specifically, we propose the dual memory networks that comprise dynamic and static memory components. The static memory caches training data knowledge, enabling training-free few-shot adaptation, while the dynamic memory preserves historical test features online during the testing process, allowing for the exploration of additional data insights beyond the training set. This novel capability enhances model performance in the few-shot setting and enables model usability in the absence of training data. The two memory networks employ the same flexible memory interactive strategy, which can operate in a training-free mode and can be further enhanced by incorporating learnable projection layers. Our approach is tested across 11 datasets under the three task settings. Remarkably, in the zero-shot scenario, it outperforms existing methods by over 3\% and even shows superior results against methods utilizing external training data. Additionally, our method exhibits robust performance against natural distribution shifts. Codes are available at \url{https://github.com/YBZh/DMN}.
Edge Computing Enabled Real-Time Video Analysis via Adaptive Spatial-Temporal Semantic Filtering
Feb 29, 2024



This paper proposes a novel edge computing enabled real-time video analysis system for intelligent visual devices. The proposed system consists of a tracking-assisted object detection module (TAODM) and a region of interesting module (ROIM). TAODM adaptively determines the offloading decision to process each video frame locally with a tracking algorithm or to offload it to the edge server inferred by an object detection model. ROIM determines each offloading frame's resolution and detection model configuration to ensure that the analysis results can return in time. TAODM and ROIM interact jointly to filter the repetitive spatial-temporal semantic information to maximize the processing rate while ensuring high video analysis accuracy. Unlike most existing works, this paper investigates the real-time video analysis systems where the intelligent visual device connects to the edge server through a wireless network with fluctuating network conditions. We decompose the real-time video analysis problem into the offloading decision and configurations selection sub-problems. To solve these two sub-problems, we introduce a double deep Q network (DDQN) based offloading approach and a contextual multi-armed bandit (CMAB) based adaptive configurations selection approach, respectively. A DDQN-CMAB reinforcement learning (DCRL) training framework is further developed to integrate these two approaches to improve the overall video analyzing performance. Extensive simulations are conducted to evaluate the performance of the proposed solution, and demonstrate its superiority over counterparts.
On the Efficacy of Small Self-Supervised Contrastive Models without Distillation Signals
Jul 30, 2021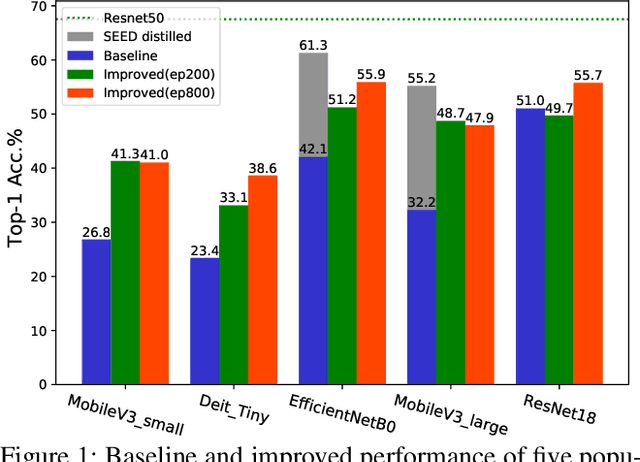
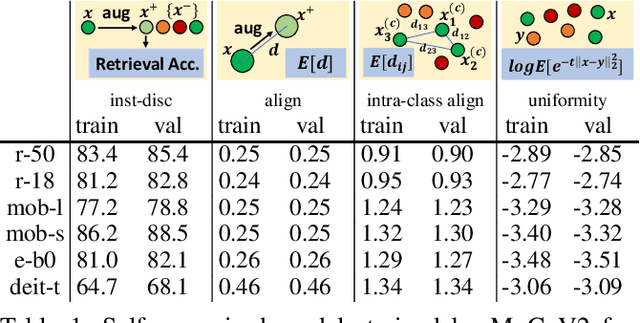

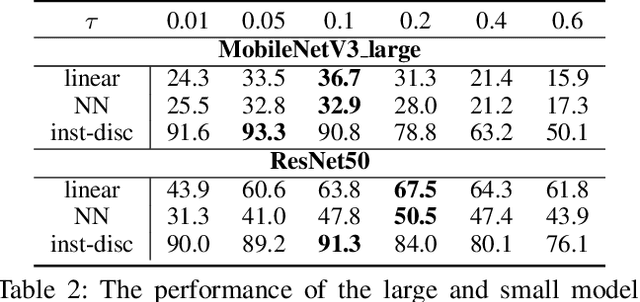
It is a consensus that small models perform quite poorly under the paradigm of self-supervised contrastive learning. Existing methods usually adopt a large off-the-shelf model to transfer knowledge to the small one via knowledge distillation. Despite their effectiveness, distillation-based methods may not be suitable for some resource-restricted scenarios due to the huge computational expenses of deploying a large model. In this paper, we study the issue of training self-supervised small models without distillation signals. We first evaluate the representation spaces of the small models and make two non-negligible observations: (i) small models can complete the pretext task without overfitting despite its limited capacity; (ii) small models universally suffer the problem of over-clustering. Then we verify multiple assumptions that are considered to alleviate the over-clustering phenomenon. Finally, we combine the validated techniques and improve the baseline of five small architectures with considerable margins, which indicates that training small self-supervised contrastive models is feasible even without distillation signals.