 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Augmentations for Video Representation Learning
Apr 01, 2022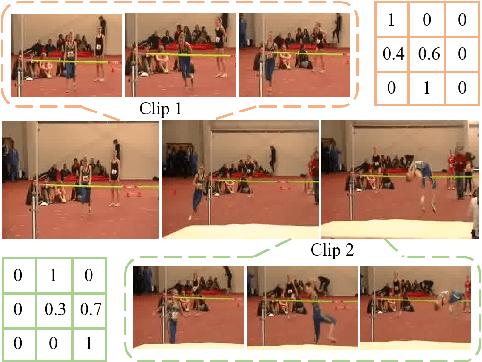
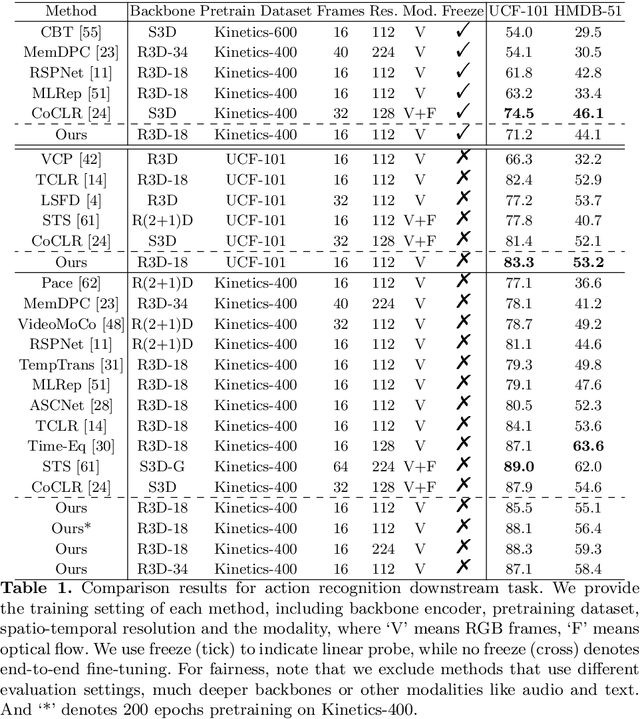
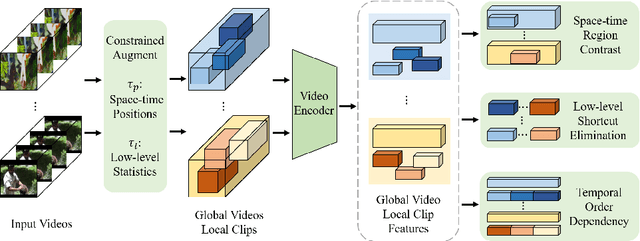
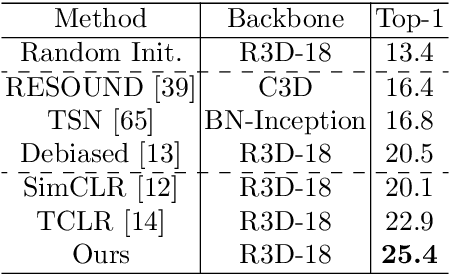
This paper focuses on self-supervised video representation learning. Most existing approaches follow the contrastive learning pipeline to construct positive and negative pairs by sampling different clips. However, this formulation tends to bias to static background and have difficulty establishing global temporal structures. The major reason is that the positive pairs, i.e., different clips sampled from the same video, have limited temporal receptive field, and usually share similar background but differ in motions. To address these problems, we propose a framework to jointly utilize local clips and global videos to learn from detailed region-level correspondence as well as general long-term temporal relations. Based on a set of controllable augmentations, we achieve accurate appearance and motion pattern alignment through soft spatio-temporal region contrast. Our formulation is able to avoid the low-level redundancy shortcut by mutual information minimization to improve the generalization. We also introduce local-global temporal order dependency to further bridge the gap between clip-level and video-level representations for robust temporal modeling. Extensive experiments demonstrate that our framework is superior on three video benchmarks in action recognition and video retrieval, capturing more accurate temporal dynamics.
End-to-end video instance segmentation via spatial-temporal graph neural networks
Mar 07, 2022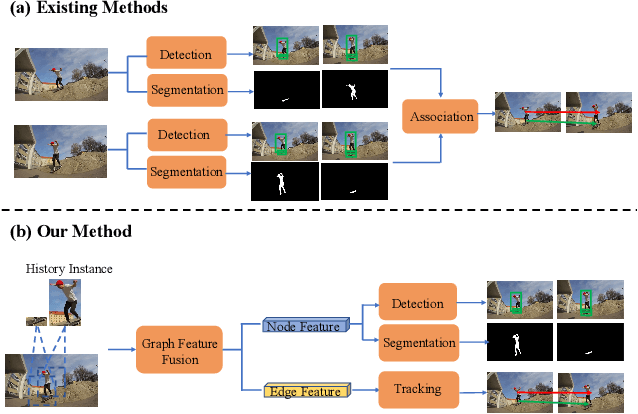
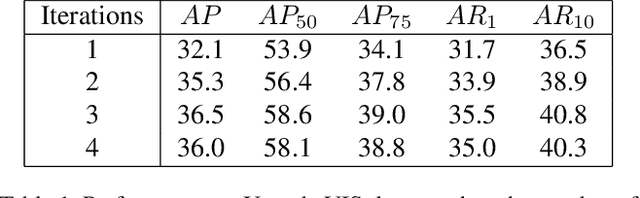
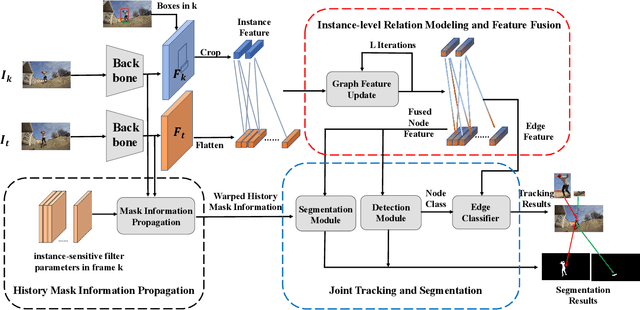
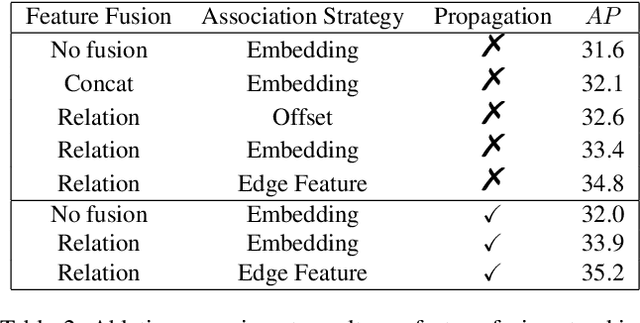
Video instance segmentation is a challenging task that extends image instance segmentation to the video domain. Existing methods either rely only on single-frame information for the detection and segmentation subproblems or handle tracking as a separate post-processing step, which limit their capability to fully leverage and share useful spatial-temporal information for all the subproblems. In this paper, we propose a novel graph-neural-network (GNN) based method to handle the aforementioned limitation. Specifically, graph nodes representing instance features are used for detection and segmentation while graph edges representing instance relations are used for tracking. Both inter and intra-frame information is effectively propagated and shared via graph updates and all the subproblems (i.e. detection, segmentation and tracking) are jointly optimized in an unified framework. The performance of our method shows great improvement on the YoutubeVIS validation dataset compared to existing methods and achieves 35.2% AP with a ResNet-50 backbone, operating at 22 FPS. Code is available at http://github.com/lucaswithai/visgraph.git .
Visual Sound Localization in the Wild by Cross-Modal Interference Erasing
Feb 13, 2022
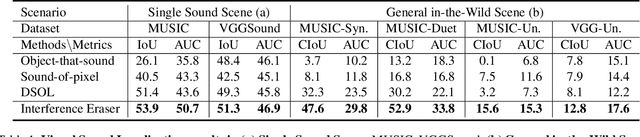
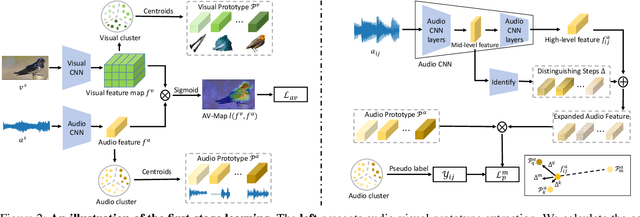

The task of audio-visual sound source localization has been well studied under constrained scenes, where the audio recordings are clean. However, in real-world scenarios, audios are usually contaminated by off-screen sound and background noise. They will interfere with the procedure of identifying desired sources and building visual-sound connections, making previous studies non-applicable. In this work, we propose the Interference Eraser (IEr) framework, which tackles the problem of audio-visual sound source localization in the wild. The key idea is to eliminate the interference by redefining and carving discriminative audio representations. Specifically, we observe that the previous practice of learning only a single audio representation is insufficient due to the additive nature of audio signals. We thus extend the audio representation with our Audio-Instance-Identifier module, which clearly distinguishes sounding instances when audio signals of different volumes are unevenly mixed. Then we erase the influence of the audible but off-screen sounds and the silent but visible objects by a Cross-modal Referrer module with cross-modality distillation. Quantitative and qualitative evaluations demonstrate that our proposed framework achieves superior results on sound localization tasks, especially under real-world scenarios. Code is available at https://github.com/alvinliu0/Visual-Sound-Localization-in-the-Wild.
Uni-EDEN: Universal Encoder-Decoder Network by Multi-Granular Vision-Language Pre-training
Jan 11, 2022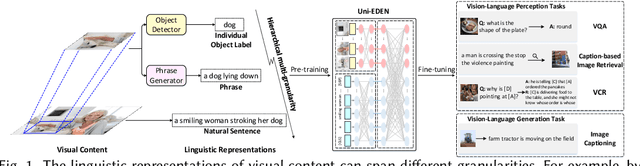
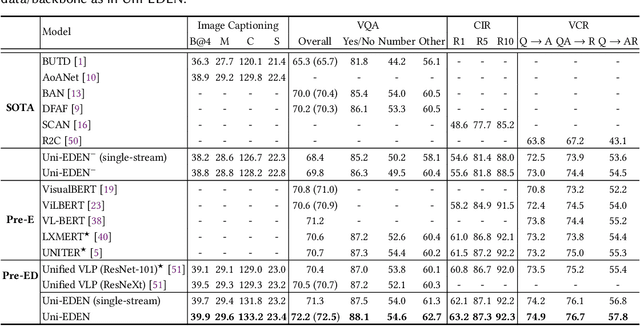
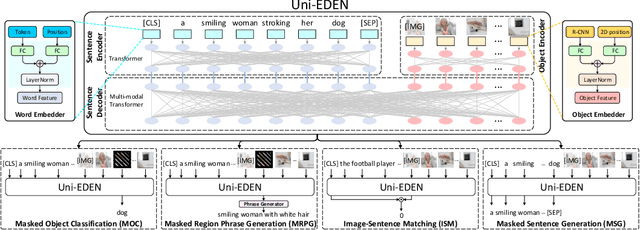
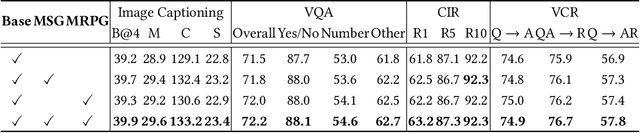
Vision-language pre-training has been an emerging and fast-developing research topic, which transfers multi-modal knowledge from rich-resource pre-training task to limited-resource downstream tasks. Unlike existing works that predominantly learn a single generic encoder, we present a pre-trainable Universal Encoder-DEcoder Network (Uni-EDEN) to facilitate both vision-language perception (e.g., visual question answering) and generation (e.g., image captioning). Uni-EDEN is a two-stream Transformer based structure, consisting of three modules: object and sentence encoders that separately learns the representations of each modality, and sentence decoder that enables both multi-modal reasoning and sentence generation via inter-modal interaction. Considering that the linguistic representations of each image can span different granularities in this hierarchy including, from simple to comprehensive, individual label, a phrase, and a natural sentence, we pre-train Uni-EDEN through multi-granular vision-language proxy tasks: Masked Object Classification (MOC), Masked Region Phrase Generation (MRPG), Image-Sentence Matching (ISM), and Masked Sentence Generation (MSG). In this way, Uni-EDEN is endowed with the power of both multi-modal representation extraction and language modeling. Extensive experiments demonstrate the compelling generalizability of Uni-EDEN by fine-tuning it to four vision-language perception and generation downstream tasks.
Class-aware Sounding Objects Localization via Audiovisual Correspondence
Dec 22, 2021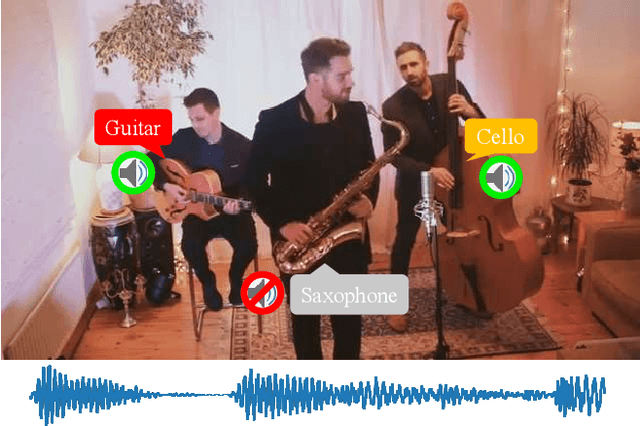

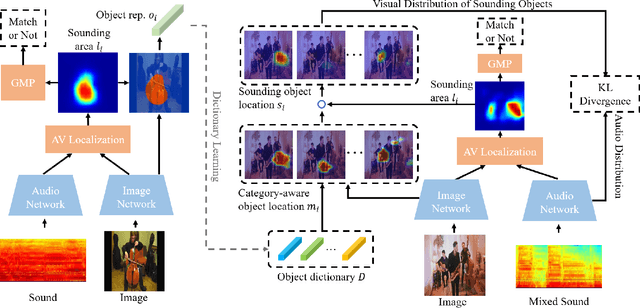
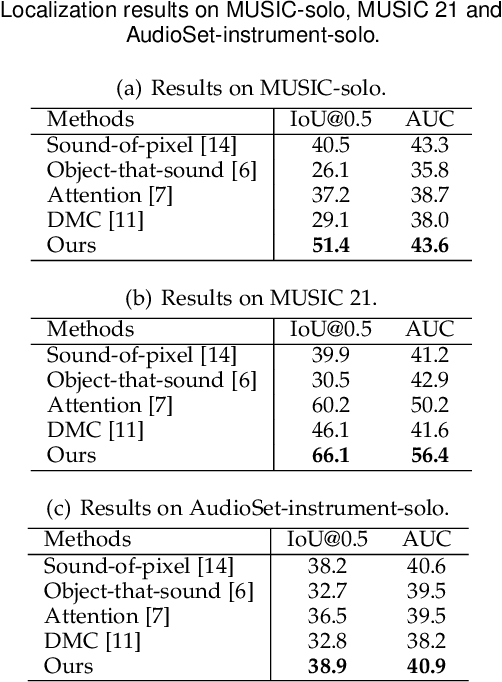
Audiovisual scenes are pervasive in our daily life. It is commonplace for humans to discriminatively localize different sounding objects but quite challenging for machines to achieve class-aware sounding objects localization without category annotations, i.e., localizing the sounding object and recognizing its category. To address this problem, we propose a two-stage step-by-step learning framework to localize and recognize sounding objects in complex audiovisual scenarios using only the correspondence between audio and vision. First, we propose to determine the sounding area via coarse-grained audiovisual correspondence in the single source cases. Then visual features in the sounding area are leveraged as candidate object representations to establish a category-representation object dictionary for expressive visual character extraction. We generate class-aware object localization maps in cocktail-party scenarios and use audiovisual correspondence to suppress silent areas by referring to this dictionary. Finally, we employ category-level audiovisual consistency as the supervision to achieve fine-grained audio and sounding object distribution alignment. Experiments on both realistic and synthesized videos show that our model is superior in localizing and recognizing objects as well as filtering out silent ones. We also transfer the learned audiovisual network into the unsupervised object detection task, obtaining reasonable performance.
Exploring the Semi-supervised Video Object Segmentation Problem from a Cyclic Perspective
Nov 02, 2021
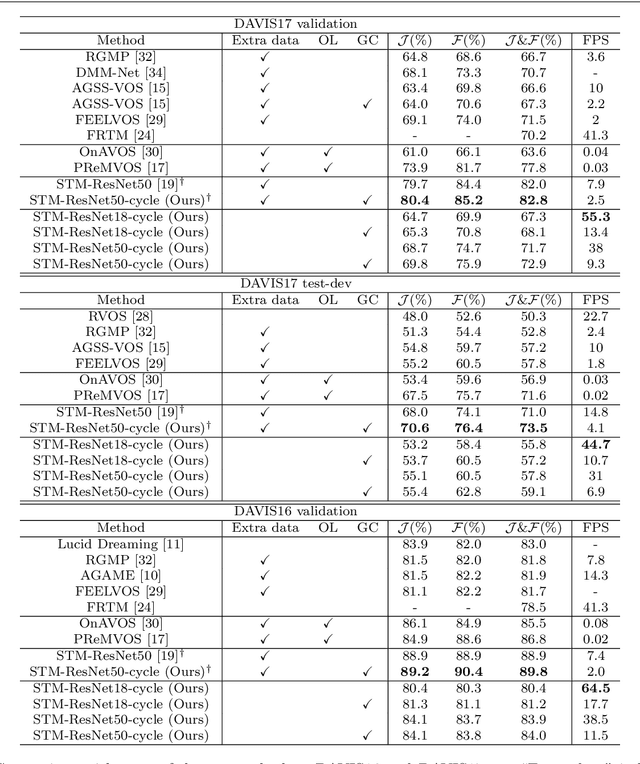
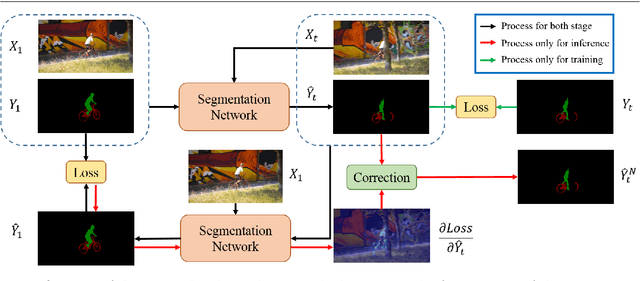
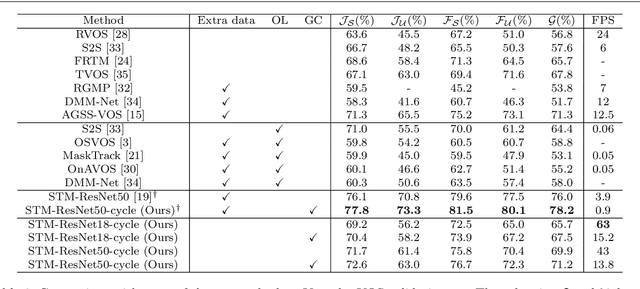
Modern video object segmentation (VOS) algorithms have achieved remarkably high performance in a sequential processing order, while most of currently prevailing pipelines still show some obvious inadequacy like accumulative error, unknown robustness or lack of proper interpretation tools. In this paper, we place the semi-supervised video object segmentation problem into a cyclic workflow and find the defects above can be collectively addressed via the inherent cyclic property of semi-supervised VOS systems. Firstly, a cyclic mechanism incorporated to the standard sequential flow can produce more consistent representations for pixel-wise correspondance. Relying on the accurate reference mask in the starting frame, we show that the error propagation problem can be mitigated. Next, a simple gradient correction module, which naturally extends the offline cyclic pipeline to an online manner, can highlight the high-frequent and detailed part of results to further improve the segmentation quality while keeping feasible computation cost. Meanwhile such correction can protect the network from severe performance degration resulted from interference signals. Finally we develop cycle effective receptive field (cycle-ERF) based on gradient correction process to provide a new perspective into analyzing object-specific regions of interests. We conduct comprehensive comparison and detailed analysis on challenging benchmarks of DAVIS16, DAVIS17 and Youtube-VOS, demonstrating that the cyclic mechanism is helpful to enhance segmentation quality, improve the robustness of VOS systems, and further provide qualitative comparison and interpretation on how different VOS algorithms work. The code of this project can be found at https://github.com/lyxok1/STM-Training
LSTC: Boosting Atomic Action Detection with Long-Short-Term Context
Oct 19, 2021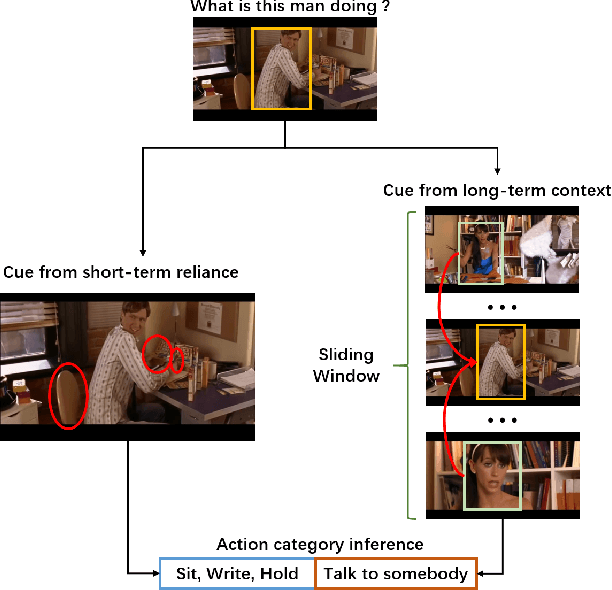
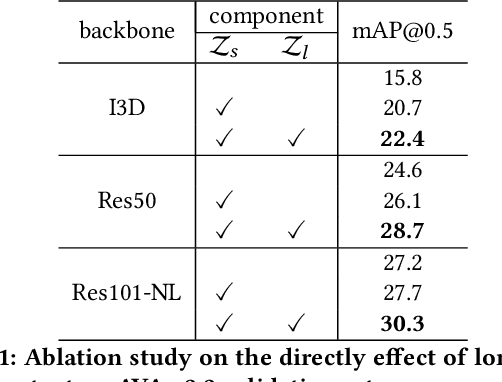
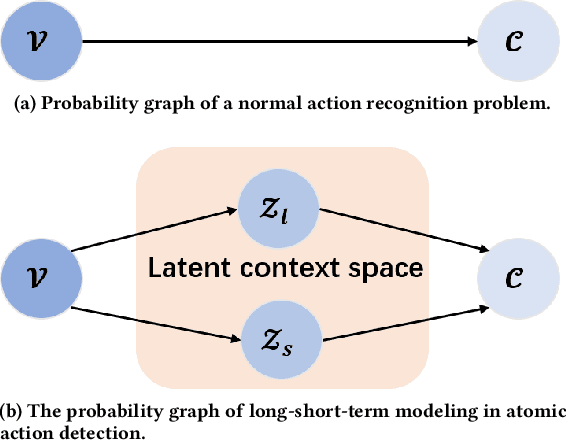
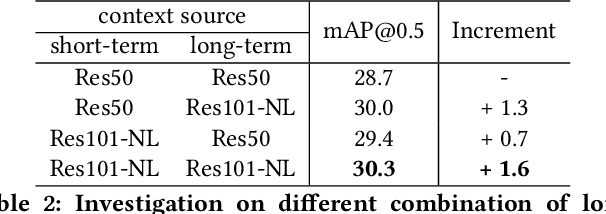
In this paper, we place the atomic action detection problem into a Long-Short Term Context (LSTC) to analyze how the temporal reliance among video signals affect the action detection results. To do this, we decompose the action recognition pipeline into short-term and long-term reliance, in terms of the hypothesis that the two kinds of context are conditionally independent given the objective action instance. Within our design, a local aggregation branch is utilized to gather dense and informative short-term cues, while a high order long-term inference branch is designed to reason the objective action class from high-order interaction between actor and other person or person pairs. Both branches independently predict the context-specific actions and the results are merged in the end. We demonstrate that both temporal grains are beneficial to atomic action recognition. On the mainstream benchmarks of atomic action detection, our design can bring significant performance gain from the existing state-of-the-art pipeline. The code of this project can be found at [this url](https://github.com/TencentYoutuResearch/ActionDetection-LSTC)
Enhancing Self-supervised Video Representation Learning via Multi-level Feature Optimization
Aug 17, 2021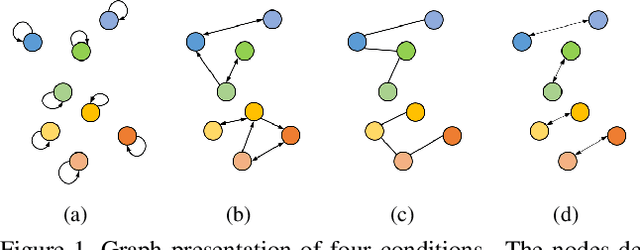
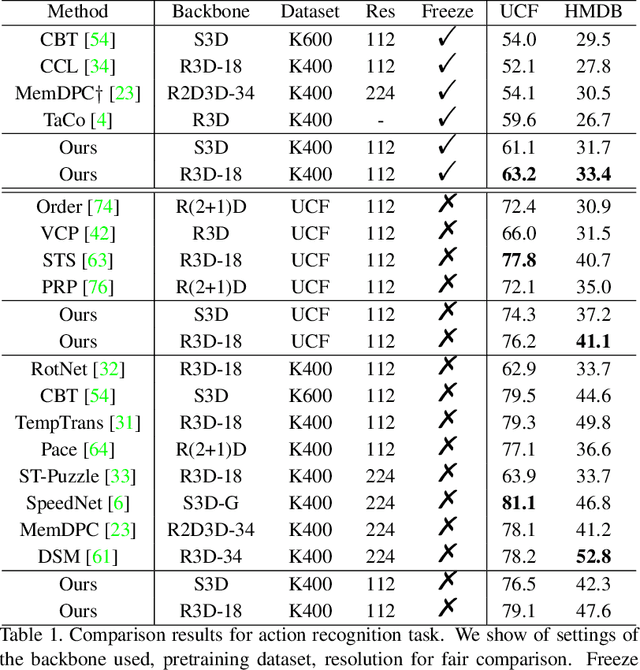
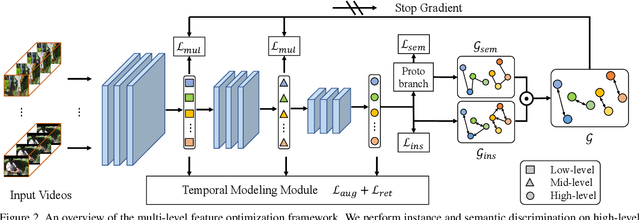
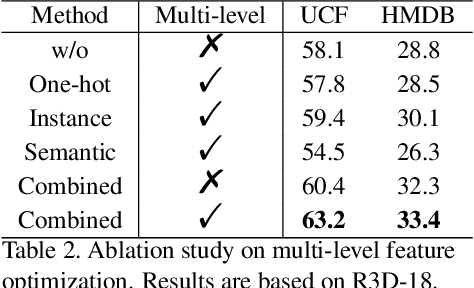
The crux of self-supervised video representation learning is to build general features from unlabeled videos. However, most recent works have mainly focused on high-level semantics and neglected lower-level representations and their temporal relationship which are crucial for general video understanding. To address these challenges, this paper proposes a multi-level feature optimization framework to improve the generalization and temporal modeling ability of learned video representations. Concretely, high-level features obtained from naive and prototypical contrastive learning are utilized to build distribution graphs, guiding the process of low-level and mid-level feature learning. We also devise a simple temporal modeling module from multi-level features to enhance motion pattern learning. Experiments demonstrate that multi-level feature optimization with the graph constraint and temporal modeling can greatly improve the representation ability in video understanding. Code is available at https://github.com/shvdiwnkozbw/Video-Representation-via-Multi-level-Optimization.
TTAN: Two-Stage Temporal Alignment Network for Few-shot Action Recognition
Jul 10, 2021
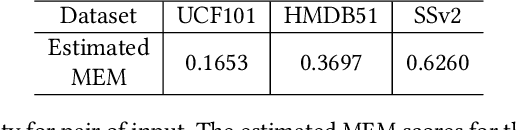
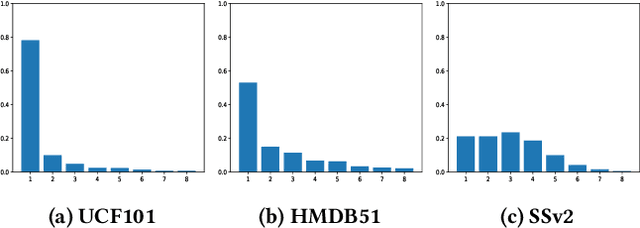
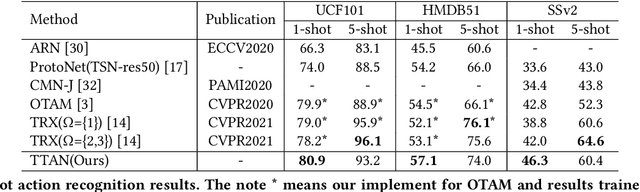
Few-shot action recognition aims to recognize novel action classes (query) using just a few samples (support). The majority of current approaches follow the metric learning paradigm, which learns to compare the similarity between videos. Recently, it has been observed that directly measuring this similarity is not ideal since different action instances may show distinctive temporal distribution, resulting in severe misalignment issues across query and support videos. In this paper, we arrest this problem from two distinct aspects -- action duration misalignment and motion evolution misalignment. We address them sequentially through a Two-stage Temporal Alignment Network (TTAN). The first stage performs temporal transformation with the predicted affine warp parameters, while the second stage utilizes a cross-attention mechanism to coordinate the features of the support and query to a consistent evolution. Besides, we devise a novel multi-shot fusion strategy, which takes the misalignment among support samples into consideration. Ablation studies and visualizations demonstrate the role played by both stages in addressing the misalignment. Extensive experiments on benchmark datasets show the potential of the proposed method in achieving state-of-the-art performance for few-shot action recognition.
SiamRCR: Reciprocal Classification and Regression for Visual Object Tracking
Jun 04, 2021


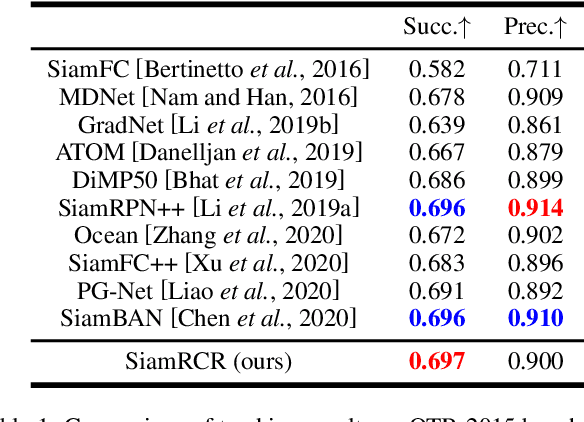
Recently, most siamese network based trackers locate targets via object classification and bounding-box regression. Generally, they select the bounding-box with maximum classification confidence as the final prediction. This strategy may miss the right result due to the accuracy misalignment between classification and regression. In this paper, we propose a novel siamese tracking algorithm called SiamRCR, addressing this problem with a simple, light and effective solution. It builds reciprocal links between classification and regression branches, which can dynamically re-weight their losses for each positive sample. In addition, we add a localization branch to predict the localization accuracy, so that it can work as the replacement of the regression assistance link during inference. This branch makes the training and inference more consistent. Extensive experimental results demonstrate the effectiveness of SiamRCR and its superiority over the state-of-the-art competitors on GOT-10k, LaSOT, TrackingNet, OTB-2015, VOT-2018 and VOT-2019. Moreover, our SiamRCR runs at 65 FPS, far above the real-time requirement.