 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning Large Language Models to Intra-module Low-rank Architecture with Transitional Activations
Jul 08, 2024



Structured pruning fundamentally reduces computational and memory overheads of large language models (LLMs) and offers a feasible solution for end-side LLM deployment. Structurally pruned models remain dense and high-precision, highly compatible with further tuning and compression. However, as the coarse-grained structured pruning poses large damage to the highly interconnected model, achieving a high compression ratio for scaled-up LLMs remains a challenge. In this paper, we introduce a task-agnostic structured pruning approach coupled with a compact Transformer architecture design. The proposed approach, named TransAct, reduces transitional activations inside multi-head attention (MHA) and multi-layer perceptron (MLP) modules, while preserving the inter-module activations that are sensitive to perturbations. Hence, the LLM is pruned into an intra-module low-rank architecture, significantly reducing weights, KV Cache and attention computation. TransAct is implemented on the LLaMA model and evaluated on downstream benchmarks. Results verify the optimality of our approach at high compression with respect to both efficiency and performance. Further, ablation studies reveal the strength of activation-guided iterative pruning and provide experimental analysis on the redundancy of MHA and MLP modules.
A Factuality and Diversity Reconciled Decoding Method for Knowledge-Grounded Dialogue Generation
Jul 08, 2024Grounding external knowledge can enhance the factuality of responses in dialogue generation. However, excessive emphasis on it might result in the lack of engaging and diverse expressions. Through the introduction of randomness in sampling, current approaches can increase the diversity. Nevertheless, such sampling method could undermine the factuality in dialogue generation. In this study, to discover a solution for advancing creativity without relying on questionable randomness and to subtly reconcile the factuality and diversity within the source-grounded paradigm, a novel method named DoGe is proposed. DoGe can dynamically alternate between the utilization of internal parameter knowledge and external source knowledge based on the model's factual confidence. Extensive experiments on three widely-used datasets show that DoGe can not only enhance response diversity but also maintain factuality, and it significantly surpasses other various decoding strategy baselines.
Multimodal Table Understanding
Jun 12, 2024



Although great progress has been made by previous table understanding methods including recent approaches based on large language models (LLMs), they rely heavily on the premise that given tables must be converted into a certain text sequence (such as Markdown or HTML) to serve as model input. However, it is difficult to access such high-quality textual table representations in some real-world scenarios, and table images are much more accessible. Therefore, how to directly understand tables using intuitive visual information is a crucial and urgent challenge for developing more practical applications. In this paper, we propose a new problem, multimodal table understanding, where the model needs to generate correct responses to various table-related requests based on the given table image. To facilitate both the model training and evaluation, we construct a large-scale dataset named MMTab, which covers a wide spectrum of table images, instructions and tasks. On this basis, we develop Table-LLaVA, a generalist tabular multimodal large language model (MLLM), which significantly outperforms recent open-source MLLM baselines on 23 benchmarks under held-in and held-out settings. The code and data is available at this https://github.com/SpursGoZmy/Table-LLaVA
Think out Loud: Emotion Deducing Explanation in Dialogues
Jun 07, 2024



Humans convey emotions through daily dialogues, making emotion understanding a crucial step of affective intelligence. To understand emotions in dialogues, machines are asked to recognize the emotion for an utterance (Emotion Recognition in Dialogues, ERD); based on the emotion, then find causal utterances for the emotion (Emotion Cause Extraction in Dialogues, ECED). The setting of the two tasks requires first ERD and then ECED, ignoring the mutual complement between emotion and cause. To fix this, some new tasks are proposed to extract them simultaneously. Although the current research on these tasks has excellent achievements, simply identifying emotion-related factors by classification modeling lacks realizing the specific thinking process of causes stimulating the emotion in an explainable way. This thinking process especially reflected in the reasoning ability of Large Language Models (LLMs) is under-explored. To this end, we propose a new task "Emotion Deducing Explanation in Dialogues" (EDEN). EDEN recognizes emotion and causes in an explicitly thinking way. That is, models need to generate an explanation text, which first summarizes the causes; analyzes the inner activities of the speakers triggered by the causes using common sense; then guesses the emotion accordingly. To support the study of EDEN, based on the existing resources in ECED, we construct two EDEN datasets by human effort. We further evaluate different models on EDEN and find that LLMs are more competent than conventional PLMs. Besides, EDEN can help LLMs achieve better recognition of emotions and causes, which explores a new research direction of explainable emotion understanding in dialogues.
Light-PEFT: Lightening Parameter-Efficient Fine-Tuning via Early Pruning
Jun 06, 2024Parameter-efficient fine-tuning (PEFT) has emerged as the predominant technique for fine-tuning in the era of large language models. However, existing PEFT methods still have inadequate training efficiency. Firstly, the utilization of large-scale foundation models during the training process is excessively redundant for certain fine-tuning tasks. Secondly, as the model size increases, the growth in trainable parameters of empirically added PEFT modules becomes non-negligible and redundant, leading to inefficiency. To achieve task-specific efficient fine-tuning, we propose the Light-PEFT framework, which includes two methods: Masked Early Pruning of the Foundation Model and Multi-Granularity Early Pruning of PEFT. The Light-PEFT framework allows for the simultaneous estimation of redundant parameters in both the foundation model and PEFT modules during the early stage of training. These parameters can then be pruned for more efficient fine-tuning. We validate our approach on GLUE, SuperGLUE, QA tasks, and various models. With Light-PEFT, parameters of the foundation model can be pruned by up to over 40%, while still controlling trainable parameters to be only 25% of the original PEFT method. Compared to utilizing the PEFT method directly, Light-PEFT achieves training and inference speedup, reduces memory usage, and maintains comparable performance and the plug-and-play feature of PEFT.
DANCE: Dual-View Distribution Alignment for Dataset Condensation
Jun 03, 2024



Dataset condensation addresses the problem of data burden by learning a small synthetic training set that preserves essential knowledge from the larger real training set. To date, the state-of-the-art (SOTA) results are often yielded by optimization-oriented methods, but their inefficiency hinders their application to realistic datasets. On the other hand, the Distribution-Matching (DM) methods show remarkable efficiency but sub-optimal results compared to optimization-oriented methods. In this paper, we reveal the limitations of current DM-based methods from the inner-class and inter-class views, i.e., Persistent Training and Distribution Shift. To address these problems, we propose a new DM-based method named Dual-view distribution AligNment for dataset CondEnsation (DANCE), which exploits a few pre-trained models to improve DM from both inner-class and inter-class views. Specifically, from the inner-class view, we construct multiple "middle encoders" to perform pseudo long-term distribution alignment, making the condensed set a good proxy of the real one during the whole training process; while from the inter-class view, we use the expert models to perform distribution calibration, ensuring the synthetic data remains in the real class region during condensing. Experiments demonstrate the proposed method achieves a SOTA performance while maintaining comparable efficiency with the original DM across various scenarios. Source codes are available at https://github.com/Hansong-Zhang/DANCE.
Disrupting Diffusion: Token-Level Attention Erasure Attack against Diffusion-based Customization
May 31, 2024



With the development of diffusion-based customization methods like DreamBooth, individuals now have access to train the models that can generate their personalized images. Despite the convenience, malicious users have misused these techniques to create fake images, thereby triggering a privacy security crisis. In light of this, proactive adversarial attacks are proposed to protect users against customization. The adversarial examples are trained to distort the customization model's outputs and thus block the misuse. In this paper, we propose DisDiff (Disrupting Diffusion), a novel adversarial attack method to disrupt the diffusion model outputs. We first delve into the intrinsic image-text relationships, well-known as cross-attention, and empirically find that the subject-identifier token plays an important role in guiding image generation. Thus, we propose the Cross-Attention Erasure module to explicitly "erase" the indicated attention maps and disrupt the text guidance. Besides,we analyze the influence of the sampling process of the diffusion model on Projected Gradient Descent (PGD) attack and introduce a novel Merit Sampling Scheduler to adaptively modulate the perturbation updating amplitude in a step-aware manner. Our DisDiff outperforms the state-of-the-art methods by 12.75% of FDFR scores and 7.25% of ISM scores across two facial benchmarks and two commonly used prompts on average.
Applying Self-supervised Learning to Network Intrusion Detection for Network Flows with Graph Neural Network
Mar 03, 2024



Graph Neural Networks (GNNs) have garnered intensive attention for Network Intrusion Detection System (NIDS) due to their suitability for representing the network traffic flows. However, most present GNN-based methods for NIDS are supervised or semi-supervised. Network flows need to be manually annotated as supervisory labels, a process that is time-consuming or even impossible, making NIDS difficult to adapt to potentially complex attacks, especially in large-scale real-world scenarios. The existing GNN-based self-supervised methods focus on the binary classification of network flow as benign or not, and thus fail to reveal the types of attack in practice. This paper studies the application of GNNs to identify the specific types of network flows in an unsupervised manner. We first design an encoder to obtain graph embedding, that introduces the graph attention mechanism and considers the edge information as the only essential factor. Then, a self-supervised method based on graph contrastive learning is proposed. The method samples center nodes, and for each center node, generates subgraph by it and its direct neighbor nodes, and corresponding contrastive subgraph from the interpolated graph, and finally constructs positive and negative samples from subgraphs. Furthermore, a structured contrastive loss function based on edge features and graph local topology is introduced. To the best of our knowledge, it is the first GNN-based self-supervised method for the multiclass classification of network flows in NIDS. Detailed experiments conducted on four real-world databases (NF-Bot-IoT, NF-Bot-IoT-v2, NF-CSE-CIC-IDS2018, and NF-CSE-CIC-IDS2018-v2) systematically compare our model with the state-of-the-art supervised and self-supervised models, illustrating the considerable potential of our method. Our code is accessible through https://github.com/renj-xu/NEGSC.
Previously on the Stories: Recap Snippet Identification for Story Reading
Feb 11, 2024



Similar to the "previously-on" scenes in TV shows, recaps can help book reading by recalling the readers' memory about the important elements in previous texts to better understand the ongoing plot. Despite its usefulness, this application has not been well studied in the NLP community. We propose the first benchmark on this useful task called Recap Snippet Identification with a hand-crafted evaluation dataset. Our experiments show that the proposed task is challenging to PLMs, LLMs, and proposed methods as the task requires a deep understanding of the plot correlation between snippets.
Are Large Language Models Table-based Fact-Checkers?
Feb 04, 2024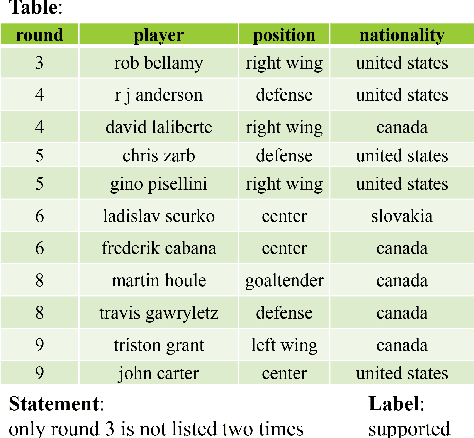



Table-based Fact Verification (TFV) aims to extract the entailment relation between statements and structured tables. Existing TFV methods based on small-scaled models suffer from insufficient labeled data and weak zero-shot ability. Recently, the appearance of Large Language Models (LLMs) has gained lots of attraction in research fields. They have shown powerful zero-shot and in-context learning abilities on several NLP tasks, but their potential on TFV is still unknown. In this work, we implement a preliminary study about whether LLMs are table-based fact-checkers. In detail, we design diverse prompts to explore how the in-context learning can help LLMs in TFV, i.e., zero-shot and few-shot TFV capability. Besides, we carefully design and construct TFV instructions to study the performance gain brought by the instruction tuning of LLMs. Experimental results demonstrate that LLMs can achieve acceptable results on zero-shot and few-shot TFV with prompt engineering, while instruction-tuning can stimulate the TFV capability significantly. We also make some valuable findings about the format of zero-shot prompts and the number of in-context examples. Finally, we analyze some possible directions to promote the accuracy of TFV via LLMs, which is beneficial to further research of table reasoning.