 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Path to Multimodal Historical Reasoning: HistBench and HistAgent
May 26, 2025Recent advances in large language models (LLMs) have led to remarkable progress across domains, yet their capabilities in the humanities, particularly history, remain underexplored. Historical reasoning poses unique challenges for AI, involving multimodal source interpretation, temporal inference, and cross-linguistic analysis. While general-purpose agents perform well on many existing benchmarks, they lack the domain-specific expertise required to engage with historical materials and questions. To address this gap, we introduce HistBench, a new benchmark of 414 high-quality questions designed to evaluate AI's capacity for historical reasoning and authored by more than 40 expert contributors. The tasks span a wide range of historical problems-from factual retrieval based on primary sources to interpretive analysis of manuscripts and images, to interdisciplinary challenges involving archaeology, linguistics, or cultural history. Furthermore, the benchmark dataset spans 29 ancient and modern languages and covers a wide range of historical periods and world regions. Finding the poor performance of LLMs and other agents on HistBench, we further present HistAgent, a history-specific agent equipped with carefully designed tools for OCR, translation, archival search, and image understanding in History. On HistBench, HistAgent based on GPT-4o achieves an accuracy of 27.54% pass@1 and 36.47% pass@2, significantly outperforming LLMs with online search and generalist agents, including GPT-4o (18.60%), DeepSeek-R1(14.49%) and Open Deep Research-smolagents(20.29% pass@1 and 25.12% pass@2). These results highlight the limitations of existing LLMs and generalist agents and demonstrate the advantages of HistAgent for historical reasoning.
Proprioceptive and Exteroceptive Information Perception in a Fabric Soft Robotic Arm via Physical Reservoir Computing with minimal training data
Nov 11, 2024



Over the past decades, we have witnessed a rapid emergence of soft and reconfigurable robots thanks to their capability to interact safely with humans and adapt to complex environments. However, their softness makes accurate control very challenging. High-fidelity sensing is critical in improving control performance, especially posture and contact estimation. To this end, traditional camera-based sensors and load cells have limited portability and accuracy, and they will inevitably increase the robot's cost and weight. In this study, instead of using specialized sensors, we only collect distributed pressure data inside a pneumatics-driven soft arm and apply the physical reservoir computing principle to simultaneously predict its kinematic posture (i.e., bending angle) and payload status (i.e., payload mass). Our results show that, with careful readout training, one can obtain accurate bending angle and payload mass predictions via simple, weighted linear summations of pressure readings. In addition, our comparative analysis shows that, to guarantee low prediction errors within 10\%, bending angle prediction requires less training data than payload prediction. This result reveals that balanced linear and nonlinear body dynamics are critical for the physical reservoir to accomplish complex proprioceptive and exteroceptive information perception tasks. Finally, the method of exploring the most efficient readout training methods presented in this paper could be extended to other soft robotic systems to maximize their perception capabilities.
Reconstruct Spine CT from Biplanar X-Rays via Diffusion Learning
Aug 21, 2024


Intraoperative CT imaging serves as a crucial resource for surgical guidance; however, it may not always be readily accessible or practical to implement. In scenarios where CT imaging is not an option, reconstructing CT scans from X-rays can offer a viable alternative. In this paper, we introduce an innovative method for 3D CT reconstruction utilizing biplanar X-rays. Distinct from previous research that relies on conventional image generation techniques, our approach leverages a conditional diffusion process to tackle the task of reconstruction. More precisely, we employ a diffusion-based probabilistic model trained to produce 3D CT images based on orthogonal biplanar X-rays. To improve the structural integrity of the reconstructed images, we incorporate a novel projection loss function. Experimental results validate that our proposed method surpasses existing state-of-the-art benchmarks in both visual image quality and multiple evaluative metrics. Specifically, our technique achieves a higher Structural Similarity Index (SSIM) of 0.83, a relative increase of 10\%, and a lower Fr\'echet Inception Distance (FID) of 83.43, which represents a relative decrease of 25\%.
HYDEN: Hyperbolic Density Representations for Medical Images and Reports
Aug 20, 2024In light of the inherent entailment relations between images and text, hyperbolic point vector embeddings, leveraging the hierarchical modeling advantages of hyperbolic space, have been utilized for visual semantic representation learning. However, point vector embedding approaches fail to address the issue of semantic uncertainty, where an image may have multiple interpretations, and text may refer to different images, a phenomenon particularly prevalent in the medical domain. Therefor, we propose \textbf{HYDEN}, a novel hyperbolic density embedding based image-text representation learning approach tailored for specific medical domain data. This method integrates text-aware local features alongside global features from images, mapping image-text features to density features in hyperbolic space via using hyperbolic pseudo-Gaussian distributions. An encapsulation loss function is employed to model the partial order relations between image-text density distributions. Experimental results demonstrate the interpretability of our approach and its superior performance compared to the baseline methods across various zero-shot tasks and different datasets.
Coarse-Fine View Attention Alignment-Based GAN for CT Reconstruction from Biplanar X-Rays
Aug 19, 2024


For surgical planning and intra-operation imaging, CT reconstruction using X-ray images can potentially be an important alternative when CT imaging is not available or not feasible. In this paper, we aim to use biplanar X-rays to reconstruct a 3D CT image, because biplanar X-rays convey richer information than single-view X-rays and are more commonly used by surgeons. Different from previous studies in which the two X-ray views were treated indifferently when fusing the cross-view data, we propose a novel attention-informed coarse-to-fine cross-view fusion method to combine the features extracted from the orthogonal biplanar views. This method consists of a view attention alignment sub-module and a fine-distillation sub-module that are designed to work together to highlight the unique or complementary information from each of the views. Experiments have demonstrated the superiority of our proposed method over the SOTA methods.
DiffuX2CT: Diffusion Learning to Reconstruct CT Images from Biplanar X-Rays
Jul 18, 2024

Computed tomography (CT) is widely utilized in clinical settings because it delivers detailed 3D images of the human body. However, performing CT scans is not always feasible due to radiation exposure and limitations in certain surgical environments. As an alternative, reconstructing CT images from ultra-sparse X-rays offers a valuable solution and has gained significant interest in scientific research and medical applications. However, it presents great challenges as it is inherently an ill-posed problem, often compromised by artifacts resulting from overlapping structures in X-ray images. In this paper, we propose DiffuX2CT, which models CT reconstruction from orthogonal biplanar X-rays as a conditional diffusion process. DiffuX2CT is established with a 3D global coherence denoising model with a new, implicit conditioning mechanism. We realize the conditioning mechanism by a newly designed tri-plane decoupling generator and an implicit neural decoder. By doing so, DiffuX2CT achieves structure-controllable reconstruction, which enables 3D structural information to be recovered from 2D X-rays, therefore producing faithful textures in CT images. As an extra contribution, we collect a real-world lumbar CT dataset, called LumbarV, as a new benchmark to verify the clinical significance and performance of CT reconstruction from X-rays. Extensive experiments on this dataset and three more publicly available datasets demonstrate the effectiveness of our proposal.
IPAD: Iterative, Parallel, and Diffusion-based Network for Scene Text Recognition
Dec 19, 2023Nowadays, scene text recognition has attracted more and more attention due to its diverse applications. Most state-of-the-art methods adopt an encoder-decoder framework with the attention mechanism, autoregressively generating text from left to right. Despite the convincing performance, this sequential decoding strategy constrains inference speed. Conversely, non-autoregressive models provide faster, simultaneous predictions but often sacrifice accuracy. Although utilizing an explicit language model can improve performance, it burdens the computational load. Besides, separating linguistic knowledge from vision information may harm the final prediction. In this paper, we propose an alternative solution, using a parallel and iterative decoder that adopts an easy-first decoding strategy. Furthermore, we regard text recognition as an image-based conditional text generation task and utilize the discrete diffusion strategy, ensuring exhaustive exploration of bidirectional contextual information. Extensive experiments demonstrate that the proposed approach achieves superior results on the benchmark datasets, including both Chinese and English text images.
Masked and Permuted Implicit Context Learning for Scene Text Recognition
May 25, 2023



Scene Text Recognition (STR) is a challenging task due to variations in text style, shape, and background. Incorporating linguistic information is an effective way to enhance the robustness of STR models. Existing methods rely on permuted language modeling (PLM) or masked language modeling (MLM) to learn contextual information implicitly, either through an ensemble of permuted autoregressive (AR) LMs training or iterative non-autoregressive (NAR) decoding procedure. However, these methods exhibit limitations: PLM's AR decoding results in the lack of information about future characters, while MLM provides global information of the entire text but neglects dependencies among each predicted character. In this paper, we propose a Masked and Permuted Implicit Context Learning Network for STR, which unifies PLM and MLM within a single decoding architecture, inheriting the advantages of both approaches. We utilize the training procedure of PLM, and to integrate MLM, we incorporate word length information into the decoding process by introducing specific numbers of mask tokens. Experimental results demonstrate that our proposed model achieves state-of-the-art performance on standard benchmarks using both AR and NAR decoding procedures.
1st Place Solutions for UG2+ Challenge 2022 ATMOSPHERIC TURBULENCE MITIGATION
Oct 30, 2022



In this technical report, we briefly introduce the solution of our team ''summer'' for Atomospheric Turbulence Mitigation in UG$^2$+ Challenge in CVPR 2022. In this task, we propose a unified end-to-end framework to reconstruct a high quality image from distorted frames, which is mainly consists of a Restormer-based image reconstruction module and a NIMA-based image quality assessment module. Our framework is efficient and generic, which is adapted to both hot-air image and text pattern. Moreover, we elaborately synthesize more than 10 thousands of images to simulate atmospheric turbulence. And these images improve the robustness of the model. Finally, we achieve the average accuracy of 98.53\% on the reconstruction result of the text patterns, ranking 1st on the final leaderboard.
Configuration Tracking Control of a Multi-Segment Soft Robotic Arm Using a Cosserat Rod Model
Oct 01, 2022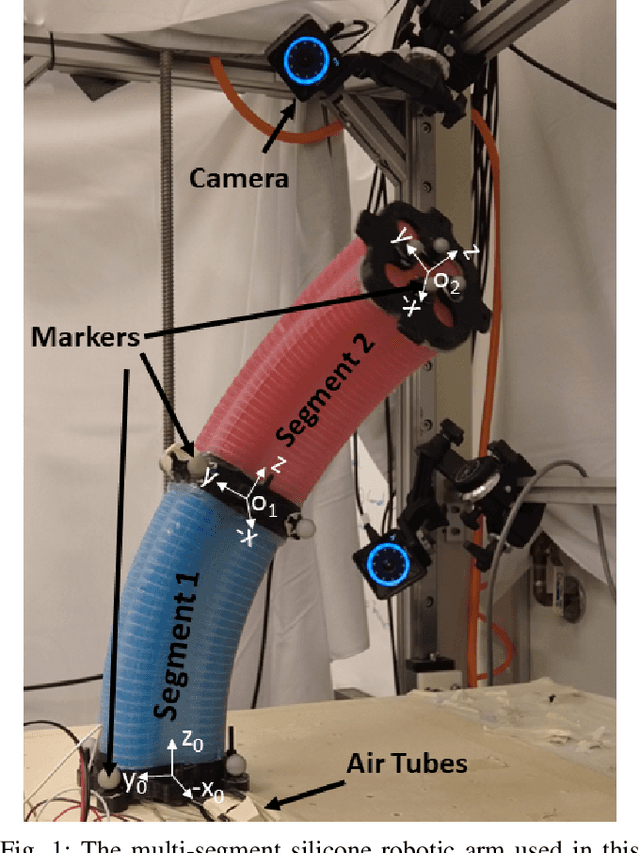
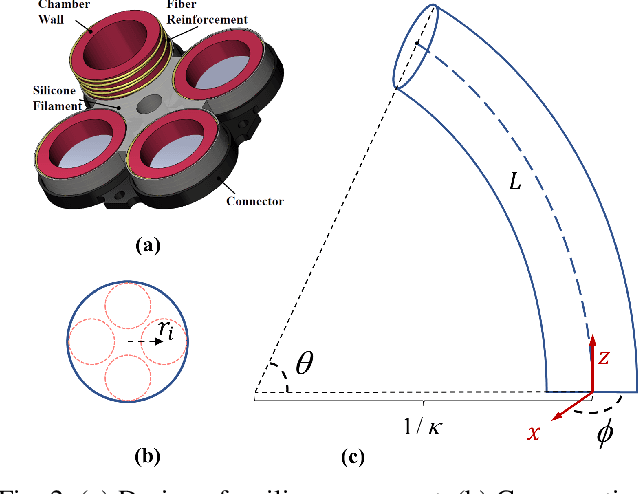
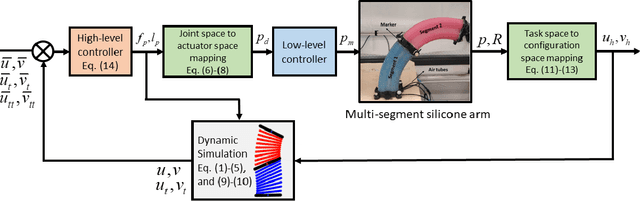
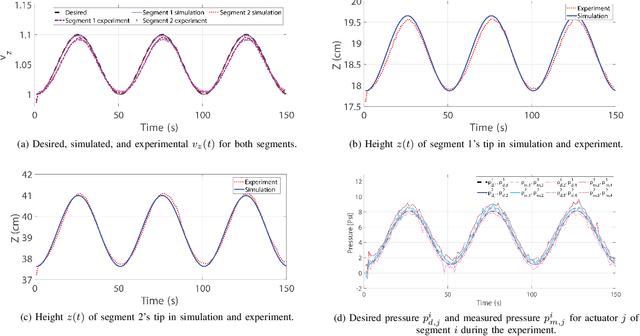
Controlling soft continuum robotic arms is challenging due to their hyper-redundancy and dexterity. In this paper we demonstrate, for the first time, closed-loop control of the configuration space variables of a soft robotic arm, composed of independently controllable segments, using a Cosserat rod model of the robot and the distributed sensing and actuation capabilities of the segments. Our controller solves the inverse dynamic problem by simulating the Cosserat rod model in MATLAB using a computationally efficient numerical solution scheme, and it applies the computed control output to the actual robot in real time. The position and orientation of the tip of each segment are measured in real time, while the remaining unknown variables that are needed to solve the inverse dynamics are estimated simultaneously in the simulation. We implement the controller on a multi-segment silicone robotic arm with pneumatic actuation, using a motion capture system to measure the segments' positions and orientations. The controller is used to reshape the arm into configurations that are achieved through different combinations of bending and extension deformations in 3D space. The resulting tracking performance indicates the effectiveness of the controller and the accuracy of the simulated Cosserat rod model that is used to estimate the unmeasured variables.