 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Overfitting for On-Device Super-Resolution with Dynamic Algorithm and Compiler Co-Design
Jul 03, 2024Deep neural networks (DNNs) are frequently employed in a variety of computer vision applications. Nowadays, an emerging trend in the current video distribution system is to take advantage of DNN's overfitting properties to perform video resolution upscaling. By splitting videos into chunks and applying a super-resolution (SR) model to overfit each chunk, this scheme of SR models plus video chunks is able to replace traditional video transmission to enhance video quality and transmission efficiency. However, many models and chunks are needed to guarantee high performance, which leads to tremendous overhead on model switching and memory footprints at the user end. To resolve such problems, we propose a Dynamic Deep neural network assisted by a Content-Aware data processing pipeline to reduce the model number down to one (Dy-DCA), which helps promote performance while conserving computational resources. Additionally, to achieve real acceleration on the user end, we designed a framework that optimizes dynamic features (e.g., dynamic shapes, sizes, and control flow) in Dy-DCA to enable a series of compilation optimizations, including fused code generation, static execution planning, etc. By employing such techniques, our method achieves better PSNR and real-time performance (33 FPS) on an off-the-shelf mobile phone. Meanwhile, assisted by our compilation optimization, we achieve a 1.7$\times$ speedup while saving up to 1.61$\times$ memory consumption. Code available in https://github.com/coulsonlee/Dy-DCA-ECCV2024.
SmartMem: Layout Transformation Elimination and Adaptation for Efficient DNN Execution on Mobile
Apr 21, 2024



This work is motivated by recent developments in Deep Neural Networks, particularly the Transformer architectures underlying applications such as ChatGPT, and the need for performing inference on mobile devices. Focusing on emerging transformers (specifically the ones with computationally efficient Swin-like architectures) and large models (e.g., Stable Diffusion and LLMs) based on transformers, we observe that layout transformations between the computational operators cause a significant slowdown in these applications. This paper presents SmartMem, a comprehensive framework for eliminating most layout transformations, with the idea that multiple operators can use the same tensor layout through careful choice of layout and implementation of operations. Our approach is based on classifying the operators into four groups, and considering combinations of producer-consumer edges between the operators. We develop a set of methods for searching such layouts. Another component of our work is developing efficient memory layouts for 2.5 dimensional memory commonly seen in mobile devices. Our experimental results show that SmartMem outperforms 5 state-of-the-art DNN execution frameworks on mobile devices across 18 varied neural networks, including CNNs, Transformers with both local and global attention, as well as LLMs. In particular, compared to DNNFusion, SmartMem achieves an average speedup of 2.8$\times$, and outperforms TVM and MNN with speedups of 6.9$\times$ and 7.9$\times$, respectively, on average.
GWLZ: A Group-wise Learning-based Lossy Compression Framework for Scientific Data
Apr 20, 2024The rapid expansion of computational capabilities and the ever-growing scale of modern HPC systems present formidable challenges in managing exascale scientific data. Faced with such vast datasets, traditional lossless compression techniques prove insufficient in reducing data size to a manageable level while preserving all information intact. In response, researchers have turned to error-bounded lossy compression methods, which offer a balance between data size reduction and information retention. However, despite their utility, these compressors employing conventional techniques struggle with limited reconstruction quality. To address this issue, we draw inspiration from recent advancements in deep learning and propose GWLZ, a novel group-wise learning-based lossy compression framework with multiple lightweight learnable enhancer models. Leveraging a group of neural networks, GWLZ significantly enhances the decompressed data reconstruction quality with negligible impact on the compression efficiency. Experimental results on different fields from the Nyx dataset demonstrate remarkable improvements by GWLZ, achieving up to 20% quality enhancements with negligible overhead as low as 0.0003x.
Efficient Pruning of Large Language Model with Adaptive Estimation Fusion
Mar 16, 2024Large language models (LLMs) have become crucial for many generative downstream tasks, leading to an inevitable trend and significant challenge to deploy them efficiently on resource-constrained devices. Structured pruning is a widely used method to address this challenge. However, when dealing with the complex structure of the multiple decoder layers, general methods often employ common estimation approaches for pruning. These approaches lead to a decline in accuracy for specific downstream tasks. In this paper, we introduce a simple yet efficient method that adaptively models the importance of each substructure. Meanwhile, it can adaptively fuse coarse-grained and finegrained estimations based on the results from complex and multilayer structures. All aspects of our design seamlessly integrate into the endto-end pruning framework. Our experimental results, compared with state-of-the-art methods on mainstream datasets, demonstrate average accuracy improvements of 1.1%, 1.02%, 2.0%, and 1.2% for LLaMa-7B,Vicuna-7B, Baichuan-7B, and Bloom-7b1, respectively.
SoD$^2$: Statically Optimizing Dynamic Deep Neural Network
Feb 29, 2024Though many compilation and runtime systems have been developed for DNNs in recent years, the focus has largely been on static DNNs. Dynamic DNNs, where tensor shapes and sizes and even the set of operators used are dependent upon the input and/or execution, are becoming common. This paper presents SoD$^2$, a comprehensive framework for optimizing Dynamic DNNs. The basis of our approach is a classification of common operators that form DNNs, and the use of this classification towards a Rank and Dimension Propagation (RDP) method. This framework statically determines the shapes of operators as known constants, symbolic constants, or operations on these. Next, using RDP we enable a series of optimizations, like fused code generation, execution (order) planning, and even runtime memory allocation plan generation. By evaluating the framework on 10 emerging Dynamic DNNs and comparing it against several existing systems, we demonstrate both reductions in execution latency and memory requirements, with RDP-enabled key optimizations responsible for much of the gains. Our evaluation results show that SoD$^2$ runs up to $3.9\times$ faster than these systems while saving up to $88\%$ peak memory consumption.
EdgeQAT: Entropy and Distribution Guided Quantization-Aware Training for the Acceleration of Lightweight LLMs on the Edge
Feb 16, 2024



Despite the remarkable strides of Large Language Models (LLMs) in various fields, the wide applications of LLMs on edge devices are limited due to their massive parameters and computations. To address this, quantization is commonly adopted to generate lightweight LLMs with efficient computations and fast inference. However, Post-Training Quantization (PTQ) methods dramatically degrade in quality when quantizing weights, activations, and KV cache together to below 8 bits. Besides, many Quantization-Aware Training (QAT) works quantize model weights, leaving the activations untouched, which do not fully exploit the potential of quantization for inference acceleration on the edge. In this paper, we propose EdgeQAT, the Entropy and Distribution Guided QAT for the optimization of lightweight LLMs to achieve inference acceleration on Edge devices. We first identify that the performance drop of quantization primarily stems from the information distortion in quantized attention maps, demonstrated by the different distributions in quantized query and key of the self-attention mechanism. Then, the entropy and distribution guided QAT is proposed to mitigate the information distortion. Moreover, we design a token importance-aware adaptive method to dynamically quantize the tokens with different bit widths for further optimization and acceleration. Our extensive experiments verify the substantial improvements with our framework across various datasets. Furthermore, we achieve an on-device speedup of up to 2.37x compared with its FP16 counterparts across multiple edge devices, signaling a groundbreaking advancement.
Towards Artificial General Intelligence (AGI) in the Internet of Things (IoT): Opportunities and Challenges
Sep 14, 2023


Artificial General Intelligence (AGI), possessing the capacity to comprehend, learn, and execute tasks with human cognitive abilities, engenders significant anticipation and intrigue across scientific, commercial, and societal arenas. This fascination extends particularly to the Internet of Things (IoT), a landscape characterized by the interconnection of countless devices, sensors, and systems, collectively gathering and sharing data to enable intelligent decision-making and automation. This research embarks on an exploration of the opportunities and challenges towards achieving AGI in the context of the IoT. Specifically, it starts by outlining the fundamental principles of IoT and the critical role of Artificial Intelligence (AI) in IoT systems. Subsequently, it delves into AGI fundamentals, culminating in the formulation of a conceptual framework for AGI's seamless integration within IoT. The application spectrum for AGI-infused IoT is broad, encompassing domains ranging from smart grids, residential environments, manufacturing, and transportation to environmental monitoring, agriculture, healthcare, and education. However, adapting AGI to resource-constrained IoT settings necessitates dedicated research efforts. Furthermore, the paper addresses constraints imposed by limited computing resources, intricacies associated with large-scale IoT communication, as well as the critical concerns pertaining to security and privacy.
Towards High-Quality and Efficient Video Super-Resolution via Spatial-Temporal Data Overfitting
Mar 15, 2023As deep convolutional neural networks (DNNs) are widely used in various fields of computer vision, leveraging the overfitting ability of the DNN to achieve video resolution upscaling has become a new trend in the modern video delivery system. By dividing videos into chunks and overfitting each chunk with a super-resolution model, the server encodes videos before transmitting them to the clients, thus achieving better video quality and transmission efficiency. However, a large number of chunks are expected to ensure good overfitting quality, which substantially increases the storage and consumes more bandwidth resources for data transmission. On the other hand, decreasing the number of chunks through training optimization techniques usually requires high model capacity, which significantly slows down execution speed. To reconcile such, we propose a novel method for high-quality and efficient video resolution upscaling tasks, which leverages the spatial-temporal information to accurately divide video into chunks, thus keeping the number of chunks as well as the model size to minimum. Additionally, we advance our method into a single overfitting model by a data-aware joint training technique, which further reduces the storage requirement with negligible quality drop. We deploy our models on an off-the-shelf mobile phone, and experimental results show that our method achieves real-time video super-resolution with high video quality. Compared with the state-of-the-art, our method achieves 28 fps streaming speed with 41.6 PSNR, which is 14$\times$ faster and 2.29 dB better in the live video resolution upscaling tasks. Our codes are available at: https://github.com/coulsonlee/STDO-CVPR2023.git
SparCL: Sparse Continual Learning on the Edge
Sep 20, 2022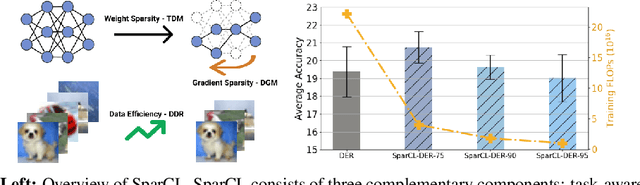
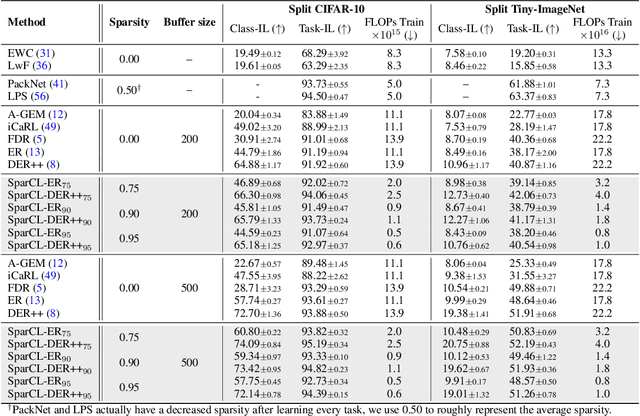
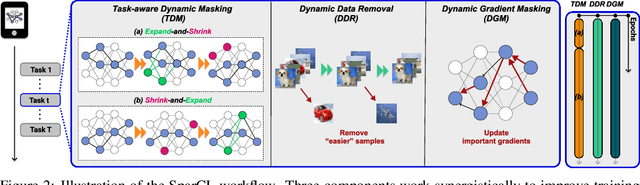
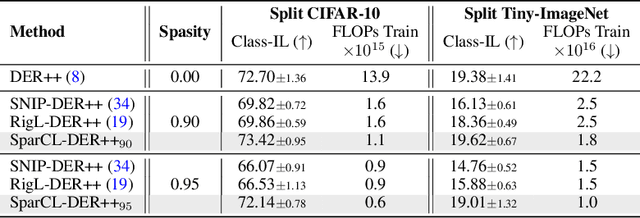
Existing work in continual learning (CL) focuses on mitigating catastrophic forgetting, i.e., model performance deterioration on past tasks when learning a new task. However, the training efficiency of a CL system is under-investigated, which limits the real-world application of CL systems under resource-limited scenarios. In this work, we propose a novel framework called Sparse Continual Learning(SparCL), which is the first study that leverages sparsity to enable cost-effective continual learning on edge devices. SparCL achieves both training acceleration and accuracy preservation through the synergy of three aspects: weight sparsity, data efficiency, and gradient sparsity. Specifically, we propose task-aware dynamic masking (TDM) to learn a sparse network throughout the entire CL process, dynamic data removal (DDR) to remove less informative training data, and dynamic gradient masking (DGM) to sparsify the gradient updates. Each of them not only improves efficiency, but also further mitigates catastrophic forgetting. SparCL consistently improves the training efficiency of existing state-of-the-art (SOTA) CL methods by at most 23X less training FLOPs, and, surprisingly, further improves the SOTA accuracy by at most 1.7%. SparCL also outperforms competitive baselines obtained from adapting SOTA sparse training methods to the CL setting in both efficiency and accuracy. We also evaluate the effectiveness of SparCL on a real mobile phone, further indicating the practical potential of our method.
Survey: Exploiting Data Redundancy for Optimization of Deep Learning
Aug 29, 2022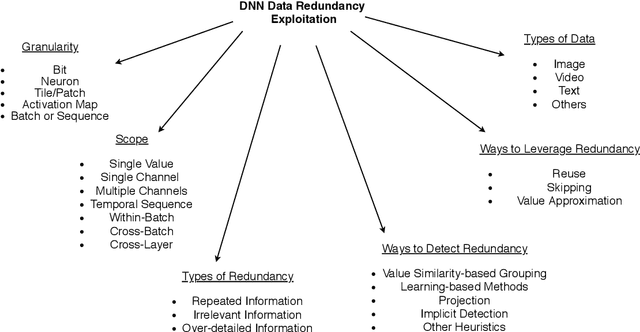
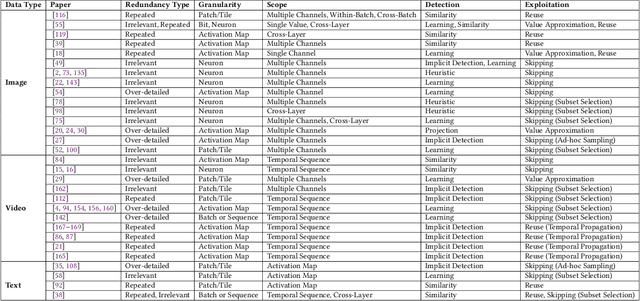
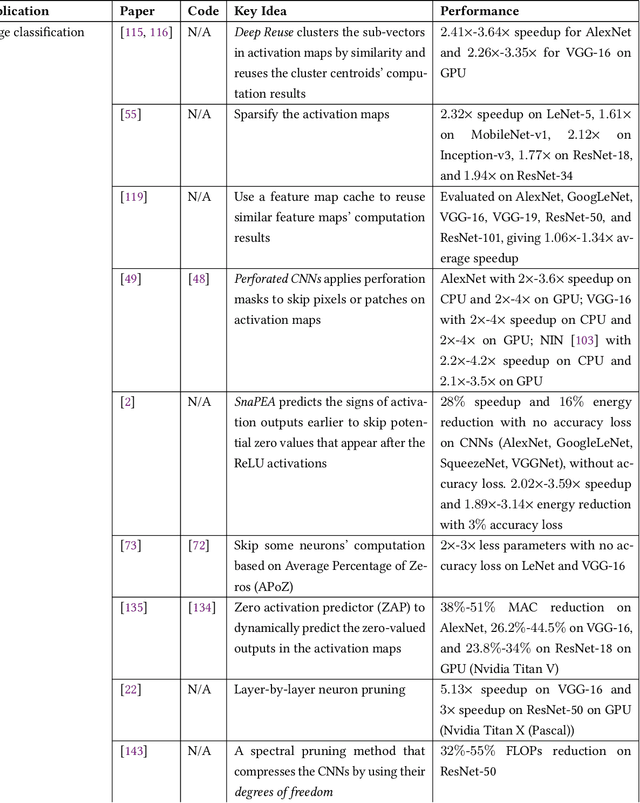
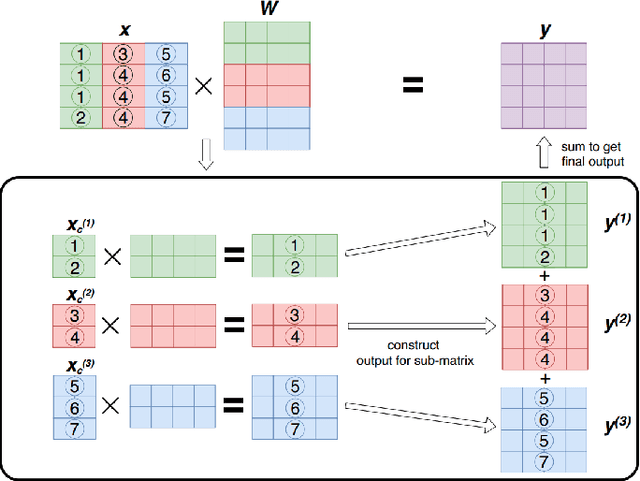
Data redundancy is ubiquitous in the inputs and intermediate results of Deep Neural Networks (DNN). It offers many significant opportunities for improving DNN performance and efficiency and has been explored in a large body of work. These studies have scattered in many venues across several years. The targets they focus on range from images to videos and texts, and the techniques they use to detect and exploit data redundancy also vary in many aspects. There is not yet a systematic examination and summary of the many efforts, making it difficult for researchers to get a comprehensive view of the prior work, the state of the art, differences and shared principles, and the areas and directions yet to explore. This article tries to fill the void. It surveys hundreds of recent papers on the topic, introduces a novel taxonomy to put the various techniques into a single categorization framework, offers a comprehensive description of the main methods used for exploiting data redundancy in improving multiple kinds of DNNs on data, and points out a set of research opportunities for future to explore.