 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Alignment of Diffusion Models via Trust-Region Iterative Twisted Sequential Monte Carlo
May 24, 2026We study inference-time alignment for diffusion-based generative models, aiming to steer a base model toward high-reward outputs without updating its weights. Recent Sequential Monte Carlo (SMC)-based steering methods approximate reward-tilted target distributions in a principled way, but their proposals remain largely tied to the base sampler. Since reward information is mainly used after propagation through particle reweighting and resampling, these methods can require large particle budgets and suffer from weight degeneracy and high-variance estimates. One way to reduce variance and improve particle efficiency is to iteratively learn twisting functions that provide look-ahead guidance, as in twisted SMC. However, existing learnable twisting methods are developed mainly for classical sequential inference and can be unstable when applied to diffusion-based alignment with high-dimensional state spaces and terminal, noisy, or black-box rewards. We propose Trust-Region Iterative Twisted Sequential Monte Carlo (TRI-TSMC), a trust-region framework for learning twisting functions in SMC-based inference-time alignment. Each iteration computes an exact KL-constrained update in path space, which admits a closed-form solution by tempered importance reweighting, and projects this target back to the parameterized twisted family by weighted maximum likelihood. Theoretically, we formalize the value-function interpretation of the optimal twisting function and show that it yields a zero-variance sampler. We prove that the trust-region update follows an escort path toward the target distribution, that the weighted maximum-likelihood update is a forward-KL projection, and that the path reduces residual importance-weight variance. Empirically, TRI-TSMC improves primary alignment objectives on discrete diffusion text generation and text-to-image generation under matched inference-time budgets.
Cross-Domain Energy-Guided Diffusion Generation for Off-Dynamics Reinforcement Learning
May 24, 2026Off-dynamics offline reinforcement learning seeks to learn a target-domain policy from a large source dataset and a limited target dataset under mismatched transition dynamics. Existing approaches such as reward augmentation and data filtering are constrained to the source dataset and cannot synthesize new target behavior to improve coverage beyond the collected source trajectories. While recent model-based methods attempt to address this by learning target-aware dynamics, the generated experience is constructed only at the transition level, which leads to accumulated errors over long horizons. These limitations necessitate a shift toward trajectory-level generation for off-dynamics offline RL. We propose CEDGE, a Cross-domain Energy-guided Diffusion GEneration framework. CEDGE trains a trajectory diffusion model on source-domain trajectories and adapts the generated samples to the target domain through energy guidance. This guidance is derived by minimizing the distribution mismatch between the source and desired target-domain trajectories and is decomposed into return, domain, and behavior energy components. The resulting energy-guided trajectories are useful both for direct planning and as synthetic data for policy learning. Since target adaptation is achieved via energy guidance rather than retraining the diffusion model, CEDGE can be efficiently adapted to new target dynamics compared to previous methods. Experiments on the ODRL benchmark demonstrate that trajectory-level energy-guided generation improves diffusion planning under dynamics shifts and produces synthetic data that improves downstream target policy learning.
Localized Dynamics-Aware Domain Adaption for Off-Dynamics Offline Reinforcement Learning
Feb 24, 2026Off-dynamics offline reinforcement learning (RL) aims to learn a policy for a target domain using limited target data and abundant source data collected under different transition dynamics. Existing methods typically address dynamics mismatch either globally over the state space or via pointwise data filtering; these approaches can miss localized cross-domain similarities or incur high computational cost. We propose Localized Dynamics-Aware Domain Adaptation (LoDADA), which exploits localized dynamics mismatch to better reuse source data. LoDADA clusters transitions from source and target datasets and estimates cluster-level dynamics discrepancy via domain discrimination. Source transitions from clusters with small discrepancy are retained, while those from clusters with large discrepancy are filtered out. This yields a fine-grained and scalable data selection strategy that avoids overly coarse global assumptions and expensive per-sample filtering. We provide theoretical insights and extensive experiments across environments with diverse global and local dynamics shifts. Results show that LoDADA consistently outperforms state-of-the-art off-dynamics offline RL methods by better leveraging localized distribution mismatch.
Policy Regularized Distributionally Robust Markov Decision Processes with Linear Function Approximation
Oct 16, 2025Decision-making under distribution shift is a central challenge in reinforcement learning (RL), where training and deployment environments differ. We study this problem through the lens of robust Markov decision processes (RMDPs), which optimize performance against adversarial transition dynamics. Our focus is the online setting, where the agent has only limited interaction with the environment, making sample efficiency and exploration especially critical. Policy optimization, despite its success in standard RL, remains theoretically and empirically underexplored in robust RL. To bridge this gap, we propose \textbf{D}istributionally \textbf{R}obust \textbf{R}egularized \textbf{P}olicy \textbf{O}ptimization algorithm (DR-RPO), a model-free online policy optimization method that learns robust policies with sublinear regret. To enable tractable optimization within the softmax policy class, DR-RPO incorporates reference-policy regularization, yielding RMDP variants that are doubly constrained in both transitions and policies. To scale to large state-action spaces, we adopt the $d$-rectangular linear MDP formulation and combine linear function approximation with an upper confidence bonus for optimistic exploration. We provide theoretical guarantees showing that policy optimization can achieve polynomial suboptimality bounds and sample efficiency in robust RL, matching the performance of value-based approaches. Finally, empirical results across diverse domains corroborate our theory and demonstrate the robustness of DR-RPO.
Rethinking Langevin Thompson Sampling from A Stochastic Approximation Perspective
Oct 06, 2025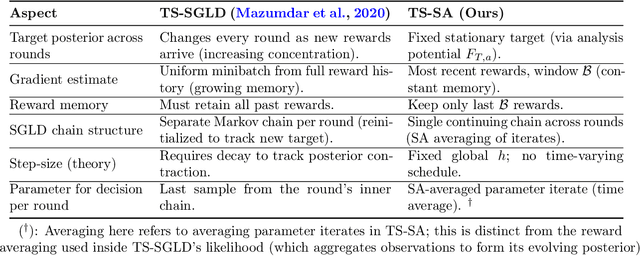
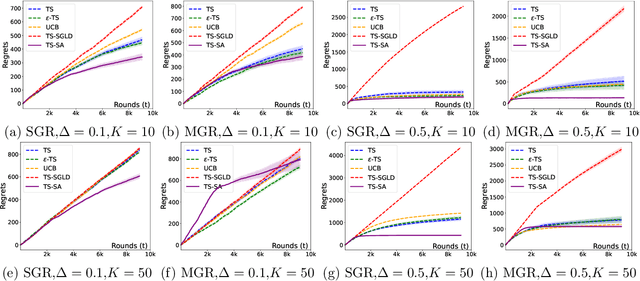

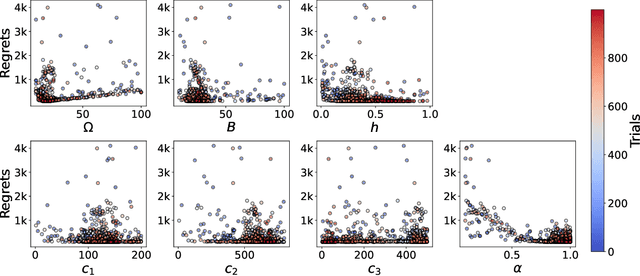
Most existing approximate Thompson Sampling (TS) algorithms for multi-armed bandits use Stochastic Gradient Langevin Dynamics (SGLD) or its variants in each round to sample from the posterior, relaxing the need for conjugacy assumptions between priors and reward distributions in vanilla TS. However, they often require approximating a different posterior distribution in different round of the bandit problem. This requires tricky, round-specific tuning of hyperparameters such as dynamic learning rates, causing challenges in both theoretical analysis and practical implementation. To alleviate this non-stationarity, we introduce TS-SA, which incorporates stochastic approximation (SA) within the TS framework. In each round, TS-SA constructs a posterior approximation only using the most recent reward(s), performs a Langevin Monte Carlo (LMC) update, and applies an SA step to average noisy proposals over time. This can be interpreted as approximating a stationary posterior target throughout the entire algorithm, which further yields a fixed step-size, a unified convergence analysis framework, and improved posterior estimates through temporal averaging. We establish near-optimal regret bounds for TS-SA, with a simplified and more intuitive theoretical analysis enabled by interpreting the entire algorithm as a simulation of a stationary SGLD process. Our empirical results demonstrate that even a single-step Langevin update with certain warm-up outperforms existing methods substantially on bandit tasks.
MOBODY: Model Based Off-Dynamics Offline Reinforcement Learning
Jun 10, 2025We study the off-dynamics offline reinforcement learning problem, where the goal is to learn a policy from offline datasets collected from source and target domains with mismatched transition. Existing off-dynamics offline RL methods typically either filter source transitions that resemble those of the target domain or apply reward augmentation to source data, both constrained by the limited transitions available from the target domain. As a result, the learned policy is unable to explore target domain beyond the offline datasets. We propose MOBODY, a Model-Based Off-Dynamics offline RL algorithm that addresses this limitation by enabling exploration of the target domain via learned dynamics. MOBODY generates new synthetic transitions in the target domain through model rollouts, which are used as data augmentation during offline policy learning. Unlike existing model-based methods that learn dynamics from a single domain, MOBODY tackles the challenge of mismatched dynamics by leveraging both source and target datasets. Directly merging these datasets can bias the learned model toward source dynamics. Instead, MOBODY learns target dynamics by discovering a shared latent representation of states and transitions across domains through representation learning. To stabilize training, MOBODY incorporates a behavior cloning loss that regularizes the policy. Specifically, we introduce a Q-weighted behavior cloning loss that regularizes the policy toward actions with high target-domain Q-values, rather than uniformly imitating all actions in the dataset. These Q-values are learned from an enhanced target dataset composed of offline target data, augmented source data, and rollout data from the learned target dynamics. We evaluate MOBODY on MuJoCo benchmarks and show that it significantly outperforms state-of-the-art baselines, with especially pronounced improvements in challenging scenarios.
How to Provably Improve Return Conditioned Supervised Learning?
Jun 10, 2025



In sequential decision-making problems, Return-Conditioned Supervised Learning (RCSL) has gained increasing recognition for its simplicity and stability in modern decision-making tasks. Unlike traditional offline reinforcement learning (RL) algorithms, RCSL frames policy learning as a supervised learning problem by taking both the state and return as input. This approach eliminates the instability often associated with temporal difference (TD) learning in offline RL. However, RCSL has been criticized for lacking the stitching property, meaning its performance is inherently limited by the quality of the policy used to generate the offline dataset. To address this limitation, we propose a principled and simple framework called Reinforced RCSL. The key innovation of our framework is the introduction of a concept we call the in-distribution optimal return-to-go. This mechanism leverages our policy to identify the best achievable in-dataset future return based on the current state, avoiding the need for complex return augmentation techniques. Our theoretical analysis demonstrates that Reinforced RCSL can consistently outperform the standard RCSL approach. Empirical results further validate our claims, showing significant performance improvements across a range of benchmarks.
Linear Mixture Distributionally Robust Markov Decision Processes
May 23, 2025



Many real-world decision-making problems face the off-dynamics challenge: the agent learns a policy in a source domain and deploys it in a target domain with different state transitions. The distributionally robust Markov decision process (DRMDP) addresses this challenge by finding a robust policy that performs well under the worst-case environment within a pre-specified uncertainty set of transition dynamics. Its effectiveness heavily hinges on the proper design of these uncertainty sets, based on prior knowledge of the dynamics. In this work, we propose a novel linear mixture DRMDP framework, where the nominal dynamics is assumed to be a linear mixture model. In contrast with existing uncertainty sets directly defined as a ball centered around the nominal kernel, linear mixture DRMDPs define the uncertainty sets based on a ball around the mixture weighting parameter. We show that this new framework provides a more refined representation of uncertainties compared to conventional models based on $(s,a)$-rectangularity and $d$-rectangularity, when prior knowledge about the mixture model is present. We propose a meta algorithm for robust policy learning in linear mixture DRMDPs with general $f$-divergence defined uncertainty sets, and analyze its sample complexities under three divergence metrics instantiations: total variation, Kullback-Leibler, and $\chi^2$ divergences. These results establish the statistical learnability of linear mixture DRMDPs, laying the theoretical foundation for future research on this new setting.
Off-Dynamics Reinforcement Learning via Domain Adaptation and Reward Augmented Imitation
Nov 15, 2024



Training a policy in a source domain for deployment in the target domain under a dynamics shift can be challenging, often resulting in performance degradation. Previous work tackles this challenge by training on the source domain with modified rewards derived by matching distributions between the source and the target optimal trajectories. However, pure modified rewards only ensure the behavior of the learned policy in the source domain resembles trajectories produced by the target optimal policies, which does not guarantee optimal performance when the learned policy is actually deployed to the target domain. In this work, we propose to utilize imitation learning to transfer the policy learned from the reward modification to the target domain so that the new policy can generate the same trajectories in the target domain. Our approach, Domain Adaptation and Reward Augmented Imitation Learning (DARAIL), utilizes the reward modification for domain adaptation and follows the general framework of generative adversarial imitation learning from observation (GAIfO) by applying a reward augmented estimator for the policy optimization step. Theoretically, we present an error bound for our method under a mild assumption regarding the dynamics shift to justify the motivation of our method. Empirically, our method outperforms the pure modified reward method without imitation learning and also outperforms other baselines in benchmark off-dynamics environments.
Return Augmented Decision Transformer for Off-Dynamics Reinforcement Learning
Oct 30, 2024



We study offline off-dynamics reinforcement learning (RL) to utilize data from an easily accessible source domain to enhance policy learning in a target domain with limited data. Our approach centers on return-conditioned supervised learning (RCSL), particularly focusing on the decision transformer (DT), which can predict actions conditioned on desired return guidance and complete trajectory history. Previous works tackle the dynamics shift problem by augmenting the reward in the trajectory from the source domain to match the optimal trajectory in the target domain. However, this strategy can not be directly applicable in RCSL owing to (1) the unique form of the RCSL policy class, which explicitly depends on the return, and (2) the absence of a straightforward representation of the optimal trajectory distribution. We propose the Return Augmented Decision Transformer (RADT) method, where we augment the return in the source domain by aligning its distribution with that in the target domain. We provide the theoretical analysis demonstrating that the RCSL policy learned from RADT achieves the same level of suboptimality as would be obtained without a dynamics shift. We introduce two practical implementations RADT-DARA and RADT-MV respectively. Extensive experiments conducted on D4RL datasets reveal that our methods generally outperform dynamic programming based methods in off-dynamics RL scenarios.