 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Leak Away: How Pretrained Model Exposure Amplifies Jailbreak Risks in Finetuned LLMs
Dec 14, 2025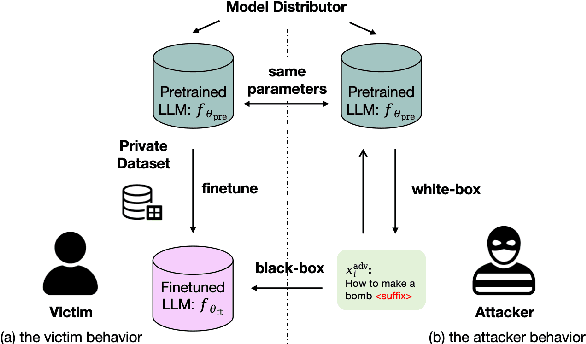
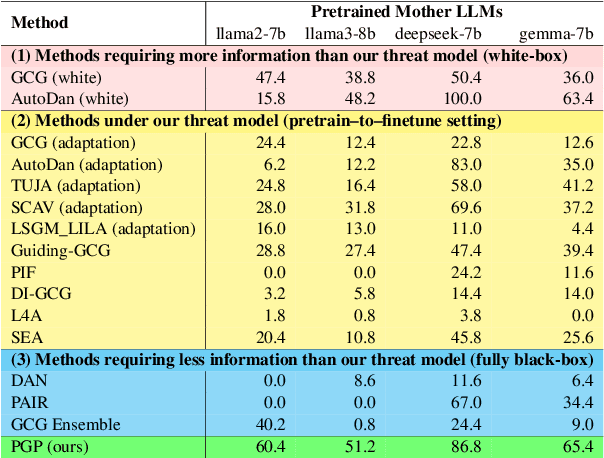
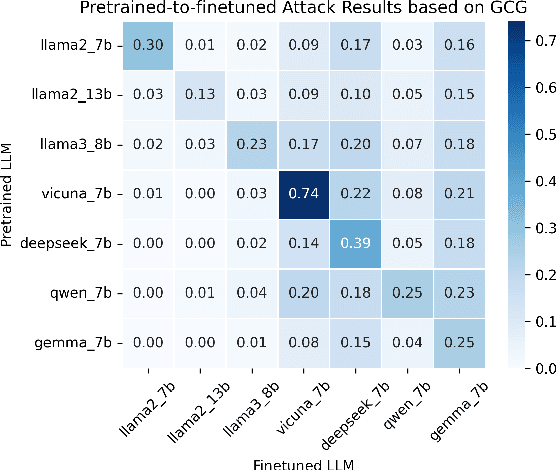
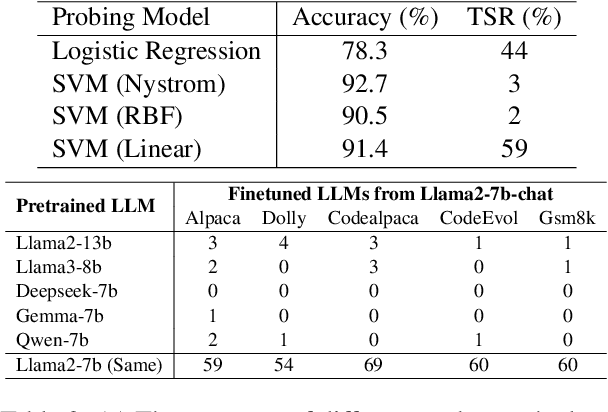
Finetuning pretrained large language models (LLMs) has become the standard paradigm for developing downstream applications. However, its security implications remain unclear, particularly regarding whether finetuned LLMs inherit jailbreak vulnerabilities from their pretrained sources. We investigate this question in a realistic pretrain-to-finetune threat model, where the attacker has white-box access to the pretrained LLM and only black-box access to its finetuned derivatives. Empirical analysis shows that adversarial prompts optimized on the pretrained model transfer most effectively to its finetuned variants, revealing inherited vulnerabilities from pretrained to finetuned LLMs. To further examine this inheritance, we conduct representation-level probing, which shows that transferable prompts are linearly separable within the pretrained hidden states, suggesting that universal transferability is encoded in pretrained representations. Building on this insight, we propose the Probe-Guided Projection (PGP) attack, which steers optimization toward transferability-relevant directions. Experiments across multiple LLM families and diverse finetuned tasks confirm PGP's strong transfer success, underscoring the security risks inherent in the pretrain-to-finetune paradigm.
Variational Schrödinger Momentum Diffusion
Jan 28, 2025



The momentum Schr\"odinger Bridge (mSB) has emerged as a leading method for accelerating generative diffusion processes and reducing transport costs. However, the lack of simulation-free properties inevitably results in high training costs and affects scalability. To obtain a trade-off between transport properties and scalability, we introduce variational Schr\"odinger momentum diffusion (VSMD), which employs linearized forward score functions (variational scores) to eliminate the dependence on simulated forward trajectories. Our approach leverages a multivariate diffusion process with adaptively transport-optimized variational scores. Additionally, we apply a critical-damping transform to stabilize training by removing the need for score estimations for both velocity and samples. Theoretically, we prove the convergence of samples generated with optimal variational scores and momentum diffusion. Empirical results demonstrate that VSMD efficiently generates anisotropic shapes while maintaining transport efficacy, outperforming overdamped alternatives, and avoiding complex denoising processes. Our approach also scales effectively to real-world data, achieving competitive results in time series and image generation.
More Efficient Randomized Exploration for Reinforcement Learning via Approximate Sampling
Jun 18, 2024



Thompson sampling (TS) is one of the most popular exploration techniques in reinforcement learning (RL). However, most TS algorithms with theoretical guarantees are difficult to implement and not generalizable to Deep RL. While the emerging approximate sampling-based exploration schemes are promising, most existing algorithms are specific to linear Markov Decision Processes (MDP) with suboptimal regret bounds, or only use the most basic samplers such as Langevin Monte Carlo. In this work, we propose an algorithmic framework that incorporates different approximate sampling methods with the recently proposed Feel-Good Thompson Sampling (FGTS) approach (Zhang, 2022; Dann et al., 2021), which was previously known to be computationally intractable in general. When applied to linear MDPs, our regret analysis yields the best known dependency of regret on dimensionality, surpassing existing randomized algorithms. Additionally, we provide explicit sampling complexity for each employed sampler. Empirically, we show that in tasks where deep exploration is necessary, our proposed algorithms that combine FGTS and approximate sampling perform significantly better compared to other strong baselines. On several challenging games from the Atari 57 suite, our algorithms achieve performance that is either better than or on par with other strong baselines from the deep RL literature.
Variational Schrödinger Diffusion Models
May 08, 2024



Schr\"odinger bridge (SB) has emerged as the go-to method for optimizing transportation plans in diffusion models. However, SB requires estimating the intractable forward score functions, inevitably resulting in the costly implicit training loss based on simulated trajectories. To improve the scalability while preserving efficient transportation plans, we leverage variational inference to linearize the forward score functions (variational scores) of SB and restore simulation-free properties in training backward scores. We propose the variational Schr\"odinger diffusion model (VSDM), where the forward process is a multivariate diffusion and the variational scores are adaptively optimized for efficient transport. Theoretically, we use stochastic approximation to prove the convergence of the variational scores and show the convergence of the adaptively generated samples based on the optimal variational scores. Empirically, we test the algorithm in simulated examples and observe that VSDM is efficient in generations of anisotropic shapes and yields straighter sample trajectories compared to the single-variate diffusion. We also verify the scalability of the algorithm in real-world data and achieve competitive unconditional generation performance in CIFAR10 and conditional generation in time series modeling. Notably, VSDM no longer depends on warm-up initializations and has become tuning-friendly in training large-scale experiments.
Convergence of flow-based generative models via proximal gradient descent in Wasserstein space
Oct 26, 2023

Flow-based generative models enjoy certain advantages in computing the data generation and the likelihood, and have recently shown competitive empirical performance. Compared to the accumulating theoretical studies on related score-based diffusion models, analysis of flow-based models, which are deterministic in both forward (data-to-noise) and reverse (noise-to-data) directions, remain sparse. In this paper, we provide a theoretical guarantee of generating data distribution by a progressive flow model, the so-called JKO flow model, which implements the Jordan-Kinderleherer-Otto (JKO) scheme in a normalizing flow network. Leveraging the exponential convergence of the proximal gradient descent (GD) in Wasserstein space, we prove the Kullback-Leibler (KL) guarantee of data generation by a JKO flow model to be $O(\varepsilon^2)$ when using $N \lesssim \log (1/\varepsilon)$ many JKO steps ($N$ Residual Blocks in the flow) where $\varepsilon $ is the error in the per-step first-order condition. The assumption on data density is merely a finite second moment, and the theory extends to data distributions without density and when there are inversion errors in the reverse process where we obtain KL-$W_2$ mixed error guarantees. The non-asymptotic convergence rate of the JKO-type $W_2$-proximal GD is proved for a general class of convex objective functionals that includes the KL divergence as a special case, which can be of independent interest.
Convergence of score-based generative modeling for general data distributions
Oct 03, 2022Score-based generative modeling (SGM) has grown to be a hugely successful method for learning to generate samples from complex data distributions such as that of images and audio. It is based on evolving an SDE that transforms white noise into a sample from the learned distribution, using estimates of the score function, or gradient log-pdf. Previous convergence analyses for these methods have suffered either from strong assumptions on the data distribution or exponential dependencies, and hence fail to give efficient guarantees for the multimodal and non-smooth distributions that arise in practice and for which good empirical performance is observed. We consider a popular kind of SGM -- denoising diffusion models -- and give polynomial convergence guarantees for general data distributions, with no assumptions related to functional inequalities or smoothness. Assuming $L^2$-accurate score estimates, we obtain Wasserstein distance guarantees for any distribution of bounded support or sufficiently decaying tails, as well as TV guarantees for distributions with further smoothness assumptions.
Convergence for score-based generative modeling with polynomial complexity
Jun 13, 2022Score-based generative modeling (SGM) is a highly successful approach for learning a probability distribution from data and generating further samples. We prove the first polynomial convergence guarantees for the core mechanic behind SGM: drawing samples from a probability density $p$ given a score estimate (an estimate of $\nabla \ln p$) that is accurate in $L^2(p)$. Compared to previous works, we do not incur error that grows exponentially in time or that suffers from a curse of dimensionality. Our guarantee works for any smooth distribution and depends polynomially on its log-Sobolev constant. Using our guarantee, we give a theoretical analysis of score-based generative modeling, which transforms white-noise input into samples from a learned data distribution given score estimates at different noise scales. Our analysis gives theoretical grounding to the observation that an annealed procedure is required in practice to generate good samples, as our proof depends essentially on using annealing to obtain a warm start at each step. Moreover, we show that a predictor-corrector algorithm gives better convergence than using either portion alone.
From syntactic structure to semantic relationship: hypernym extraction from definitions by recurrent neural networks using the part of speech information
Dec 07, 2020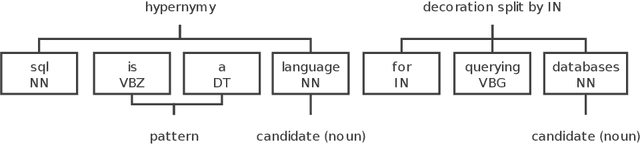

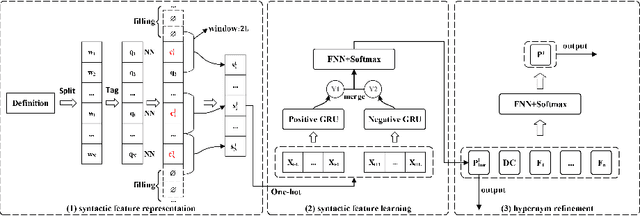

The hyponym-hypernym relation is an essential element in the semantic network. Identifying the hypernym from a definition is an important task in natural language processing and semantic analysis. While a public dictionary such as WordNet works for common words, its application in domain-specific scenarios is limited. Existing tools for hypernym extraction either rely on specific semantic patterns or focus on the word representation, which all demonstrate certain limitations.