 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Benchmarks? Rethinking Large Language Model Benchmarking with Item Response Theory
May 21, 2025
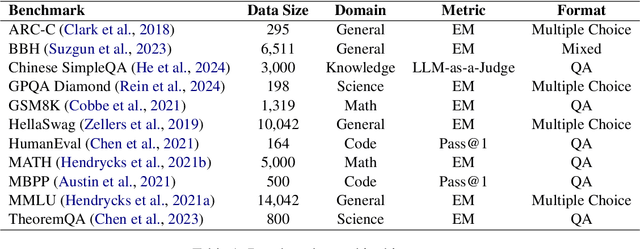
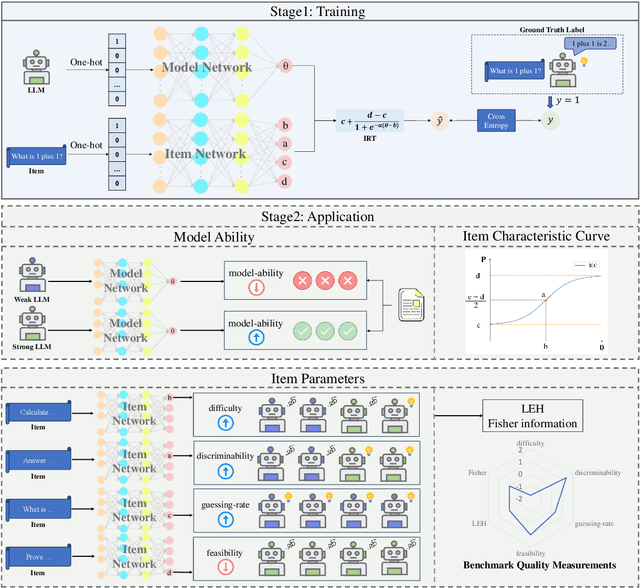

The evaluation of large language models (LLMs) via benchmarks is widespread, yet inconsistencies between different leaderboards and poor separability among top models raise concerns about their ability to accurately reflect authentic model capabilities. This paper provides a critical analysis of benchmark effectiveness, examining main-stream prominent LLM benchmarks using results from diverse models. We first propose a new framework for accurate and reliable estimations of item characteristics and model abilities. Specifically, we propose Pseudo-Siamese Network for Item Response Theory (PSN-IRT), an enhanced Item Response Theory framework that incorporates a rich set of item parameters within an IRT-grounded architecture. Based on PSN-IRT, we conduct extensive analysis which reveals significant and varied shortcomings in the measurement quality of current benchmarks. Furthermore, we demonstrate that leveraging PSN-IRT is able to construct smaller benchmarks while maintaining stronger alignment with human preference.
Harnessing Earnings Reports for Stock Predictions: A QLoRA-Enhanced LLM Approach
Aug 13, 2024


Accurate stock market predictions following earnings reports are crucial for investors. Traditional methods, particularly classical machine learning models, struggle with these predictions because they cannot effectively process and interpret extensive textual data contained in earnings reports and often overlook nuances that influence market movements. This paper introduces an advanced approach by employing Large Language Models (LLMs) instruction fine-tuned with a novel combination of instruction-based techniques and quantized low-rank adaptation (QLoRA) compression. Our methodology integrates 'base factors', such as financial metric growth and earnings transcripts, with 'external factors', including recent market indices performances and analyst grades, to create a rich, supervised dataset. This comprehensive dataset enables our models to achieve superior predictive performance in terms of accuracy, weighted F1, and Matthews correlation coefficient (MCC), especially evident in the comparison with benchmarks such as GPT-4. We specifically highlight the efficacy of the llama-3-8b-Instruct-4bit model, which showcases significant improvements over baseline models. The paper also discusses the potential of expanding the output capabilities to include a 'Hold' option and extending the prediction horizon, aiming to accommodate various investment styles and time frames. This study not only demonstrates the power of integrating cutting-edge AI with fine-tuned financial data but also paves the way for future research in enhancing AI-driven financial analysis tools.