 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-Aware Active Knowledge Acquisition for Emotional Support Dialogue
May 28, 2026Emotional support plays an important role in dialogue systems, and its success depends on adapting to a user's evolving and implicit needs across multi-turn interactions while leveraging the strong reasoning capacity of large language models. However, since signals about user needs are often weak, indirect, and can only be disambiguated through multi-turn interaction, existing emotional support methods often struggle to acquire and generalize relevant conversational knowledge efficiently. To bridge this gap, we introduce User-Aware Active Knowledge Acquisition (UKA), a gradient-free active dialogue learning framework that explicitly represents uncertainty about user needs and incorporates active learning into both knowledge acquisition and response selection.We propose a Theory-of-Mind uncertainty estimation mechanism that allows the model to prioritize responses, thereby eliciting more informative user feedback. UKA is capable of efficiently exploring user-aligned conversational knowledge during training while maintaining robustness at test time. Experiments across multiple dialogue benchmarks and model architectures demonstrate that our approach consistently outperforms strong baselines in dialogue quality and user alignment.
Long-form RewardBench: Evaluating Reward Models for Long-form Generation
Mar 13, 2026The widespread adoption of reinforcement learning-based alignment highlights the growing importance of reward models. Various benchmarks have been built to evaluate reward models in various domains and scenarios. However, a significant gap remains in assessing reward models for long-form generation, despite its critical role in real-world applications. To bridge this, we introduce Long-form RewardBench, the first reward modeling testbed specifically designed for long-form generation. Our benchmark encompasses five key subtasks: QA, RAG, Chat, Writing, and Reasoning. We collected instruction and preference data through a meticulously designed multi-stage data collection process, and conducted extensive experiments on 20+ mainstream reward models, including both classifiers and generative models. Our findings reveal that current models still lack long-form reward modeling capabilities. Furthermore, we designed a novel Long-form Needle-in-a-Haystack Test, which revealed a correlation between reward modeling performance and the error's position within a response, as well as the overall response length, with distinct characteristics observed between classification and generative models. Finally, we demonstrate that classifiers exhibit better generalizability compared to generative models trained on the same data. As the first benchmark for long-form reward modeling, this work aims to offer a robust platform for visualizing progress in this crucial area.
Toward Robust LLM-Based Judges: Taxonomic Bias Evaluation and Debiasing Optimization
Mar 09, 2026Large language model (LLM)-based judges are widely adopted for automated evaluation and reward modeling, yet their judgments are often affected by judgment biases. Accurately evaluating these biases is essential for ensuring the reliability of LLM-based judges. However, existing studies typically investigate limited biases under a single judge formulation, either generative or discriminative, lacking a comprehensive evaluation. To bridge this gap, we propose JudgeBiasBench, a benchmark for systematically quantifying biases in LLM-based judges. JudgeBiasBench defines a taxonomy of judgment biases across 4 dimensions, and constructs bias-augmented evaluation instances through a controlled bias injection pipeline, covering 12 representative bias types. We conduct extensive experiments across both generative and discriminative judges, revealing that current judges exhibit significant and diverse bias patterns that often compromise the reliability of automated evaluation. To mitigate judgment bias, we propose bias-aware training that explicitly incorporates bias-related attributes into the training process, encouraging judges to disentangle task-relevant quality from bias-correlated cues. By adopting reinforcement learning for generative judges and contrastive learning for discriminative judges, our methods effectively reduce judgment biases while largely preserving general evaluation capability.
Beyond Token-Level Policy Gradients for Complex Reasoning with Large Language Models
Feb 16, 2026Existing policy-gradient methods for auto-regressive language models typically select subsequent tokens one at a time as actions in the policy. While effective for many generation tasks, such an approach may not fully capture the structure of complex reasoning tasks, where a single semantic decision is often realized across multiple tokens--for example, when defining variables or composing equations. This introduces a potential mismatch between token-level optimization and the inherently block-level nature of reasoning in these settings. To bridge this gap, we propose Multi-token Policy Gradient Optimization (MPO), a framework that treats sequences of K consecutive tokens as unified semantic actions. This block-level perspective enables our method to capture the compositional structure of reasoning trajectories and supports optimization over coherent, higher-level objectives. Experiments on mathematical reasoning and coding benchmarks show that MPO outperforms standard token-level policy gradient baselines, highlight the limitations of token-level policy gradients for complex reasoning, motivating future research to look beyond token-level granularity for reasoning-intensive language tasks.
Thinking with Comics: Enhancing Multimodal Reasoning through Structured Visual Storytelling
Feb 03, 2026Chain-of-Thought reasoning has driven large language models to extend from thinking with text to thinking with images and videos. However, different modalities still have clear limitations: static images struggle to represent temporal structure, while videos introduce substantial redundancy and computational cost. In this work, we propose Thinking with Comics, a visual reasoning paradigm that uses comics as a high information-density medium positioned between images and videos. Comics preserve temporal structure, embedded text, and narrative coherence while requiring significantly lower reasoning cost. We systematically study two reasoning paths based on comics and evaluate them on a range of reasoning tasks and long-context understanding tasks. Experimental results show that Thinking with Comics outperforms Thinking with Images on multi-step temporal and causal reasoning tasks, while remaining substantially more efficient than Thinking with Video. Further analysis indicates that different comic narrative structures and styles consistently affect performance across tasks, suggesting that comics serve as an effective intermediate visual representation for improving multimodal reasoning.
RM-Distiller: Exploiting Generative LLM for Reward Model Distillation
Jan 20, 2026Reward models (RMs) play a pivotal role in aligning large language models (LLMs) with human preferences. Due to the difficulty of obtaining high-quality human preference annotations, distilling preferences from generative LLMs has emerged as a standard practice. However, existing approaches predominantly treat teacher models as simple binary annotators, failing to fully exploit the rich knowledge and capabilities for RM distillation. To address this, we propose RM-Distiller, a framework designed to systematically exploit the multifaceted capabilities of teacher LLMs: (1) Refinement capability, which synthesizes highly correlated response pairs to create fine-grained and contrastive signals. (2) Scoring capability, which guides the RM in capturing precise preference strength via a margin-aware optimization objective. (3) Generation capability, which incorporates the teacher's generative distribution to regularize the RM to preserve its fundamental linguistic knowledge. Extensive experiments demonstrate that RM-Distiller significantly outperforms traditional distillation methods both on RM benchmarks and reinforcement learning-based alignment, proving that exploiting multifaceted teacher capabilities is critical for effective reward modeling. To the best of our knowledge, this is the first systematic research on RM distillation from generative LLMs.
Reasoning Model Is Superior LLM-Judge, Yet Suffers from Biases
Jan 07, 2026This paper presents the first systematic comparison investigating whether Large Reasoning Models (LRMs) are superior judge to non-reasoning LLMs. Our empirical analysis yields four key findings: 1) LRMs outperform non-reasoning LLMs in terms of judgment accuracy, particularly on reasoning-intensive tasks; 2) LRMs demonstrate superior instruction-following capabilities in evaluation contexts; 3) LRMs exhibit enhanced robustness against adversarial attacks targeting judgment tasks; 4) However, LRMs still exhibit strong biases in superficial quality. To improve the robustness against biases, we propose PlanJudge, an evaluation strategy that prompts the model to generate an explicit evaluation plan before execution. Despite its simplicity, our experiments demonstrate that PlanJudge significantly mitigates biases in both LRMs and standard LLMs.
DiVA: Fine-grained Factuality Verification with Agentic-Discriminative Verifier
Jan 07, 2026Despite the significant advancements of Large Language Models (LLMs), their factuality remains a critical challenge, fueling growing interest in factuality verification. Existing research on factuality verification primarily conducts binary judgments (e.g., correct or incorrect), which fails to distinguish varying degrees of error severity. This limits its utility for applications such as fine-grained evaluation and preference optimization. To bridge this gap, we propose the Agentic Discriminative Verifier (DiVA), a hybrid framework that synergizes the agentic search capabilities of generative models with the precise scoring aptitude of discriminative models. We also construct a new benchmark, FGVeriBench, as a robust testbed for fine-grained factuality verification. Experimental results on FGVeriBench demonstrate that our DiVA significantly outperforms existing methods on factuality verification for both general and multi-hop questions.
Lost in Benchmarks? Rethinking Large Language Model Benchmarking with Item Response Theory
May 21, 2025
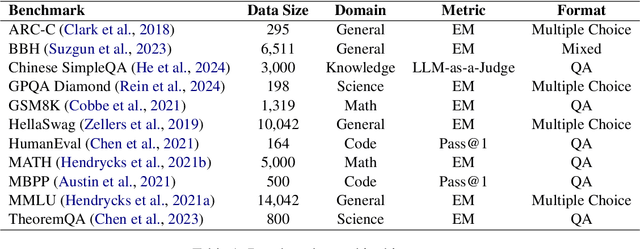
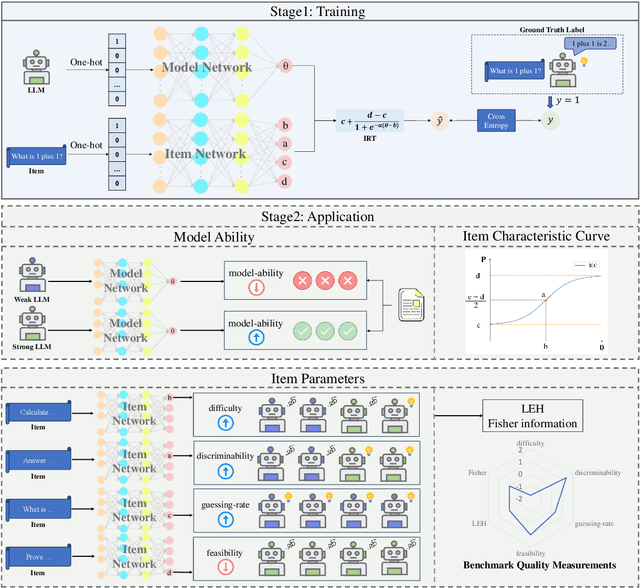

The evaluation of large language models (LLMs) via benchmarks is widespread, yet inconsistencies between different leaderboards and poor separability among top models raise concerns about their ability to accurately reflect authentic model capabilities. This paper provides a critical analysis of benchmark effectiveness, examining main-stream prominent LLM benchmarks using results from diverse models. We first propose a new framework for accurate and reliable estimations of item characteristics and model abilities. Specifically, we propose Pseudo-Siamese Network for Item Response Theory (PSN-IRT), an enhanced Item Response Theory framework that incorporates a rich set of item parameters within an IRT-grounded architecture. Based on PSN-IRT, we conduct extensive analysis which reveals significant and varied shortcomings in the measurement quality of current benchmarks. Furthermore, we demonstrate that leveraging PSN-IRT is able to construct smaller benchmarks while maintaining stronger alignment with human preference.
Memory-augmented Query Reconstruction for LLM-based Knowledge Graph Reasoning
Mar 07, 2025



Large language models (LLMs) have achieved remarkable performance on knowledge graph question answering (KGQA) tasks by planning and interacting with knowledge graphs. However, existing methods often confuse tool utilization with knowledge reasoning, harming readability of model outputs and giving rise to hallucinatory tool invocations, which hinder the advancement of KGQA. To address this issue, we propose Memory-augmented Query Reconstruction for LLM-based Knowledge Graph Reasoning (MemQ) to decouple LLM from tool invocation tasks using LLM-built query memory. By establishing a memory module with explicit descriptions of query statements, the proposed MemQ facilitates the KGQA process with natural language reasoning and memory-augmented query reconstruction. Meanwhile, we design an effective and readable reasoning to enhance the LLM's reasoning capability in KGQA. Experimental results that MemQ achieves state-of-the-art performance on widely used benchmarks WebQSP and CWQ.