 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Data Augmentation for Skeleton Action Recognition
Apr 16, 2026Skeleton-based human action recognition is a powerful approach for understanding human behaviour from pose data, but collecting large-scale, diverse, and well-annotated 3D skeleton datasets is both expensive and labor-intensive. To address this challenge, we propose a conditional generative pipeline for data augmentation in skeleton action recognition. Our method learns the distribution of real skeleton sequences under the constraint of action labels, enabling the synthesis of diverse and high-fidelity data. Even with limited training samples, it can effectively generate skeleton sequences and achieve competitive recognition performance in low-data scenarios, demonstrating strong generalisation in downstream tasks. Specifically, we introduce a Transformer-based encoder-decoder architecture, combined with a generative refinement module and a dropout mechanism, to balance fidelity and diversity during sampling. Experiments on HumanAct12 and the refined NTU-RGBD (NTU-VIBE) dataset show that our approach consistently improves the accuracy of multiple skeleton-based action recognition models, validating its effectiveness in both few-shot and full-data settings. The source code can be found at here.
Carbon Price Forecasting with Structural Breaks: A Comparative Study of Deep Learning Models
Nov 07, 2025Accurately forecasting carbon prices is essential for informed energy market decision-making, guiding sustainable energy planning, and supporting effective decarbonization strategies. However, it remains challenging due to structural breaks and high-frequency noise caused by frequent policy interventions and market shocks. Existing studies, including the most recent baseline approaches, have attempted to incorporate breakpoints but often treat denoising and modeling as separate processes and lack systematic evaluation across advanced deep learning architectures, limiting the robustness and the generalization capability. To address these gaps, this paper proposes a comprehensive hybrid framework that integrates structural break detection (Bai-Perron, ICSS, and PELT algorithms), wavelet signal denoising, and three state-of-the-art deep learning models (LSTM, GRU, and TCN). Using European Union Allowance (EUA) spot prices from 2007 to 2024 and exogenous features such as energy prices and policy indicators, the framework constructs univariate and multivariate datasets for comparative evaluation. Experimental results demonstrate that our proposed PELT-WT-TCN achieves the highest prediction accuracy, reducing forecasting errors by 22.35% in RMSE and 18.63% in MAE compared to the state-of-the-art baseline model (Breakpoints with Wavelet and LSTM), and by 70.55% in RMSE and 74.42% in MAE compared to the original LSTM without decomposition from the same baseline study. These findings underscore the value of integrating structural awareness and multiscale decomposition into deep learning architectures to enhance accuracy and interpretability in carbon price forecasting and other nonstationary financial time series.
Spatio-Temporal Joint Density Driven Learning for Skeleton-Based Action Recognition
May 29, 2025Traditional approaches in unsupervised or self supervised learning for skeleton-based action classification have concentrated predominantly on the dynamic aspects of skeletal sequences. Yet, the intricate interaction between the moving and static elements of the skeleton presents a rarely tapped discriminative potential for action classification. This paper introduces a novel measurement, referred to as spatial-temporal joint density (STJD), to quantify such interaction. Tracking the evolution of this density throughout an action can effectively identify a subset of discriminative moving and/or static joints termed "prime joints" to steer self-supervised learning. A new contrastive learning strategy named STJD-CL is proposed to align the representation of a skeleton sequence with that of its prime joints while simultaneously contrasting the representations of prime and nonprime joints. In addition, a method called STJD-MP is developed by integrating it with a reconstruction-based framework for more effective learning. Experimental evaluations on the NTU RGB+D 60, NTU RGB+D 120, and PKUMMD datasets in various downstream tasks demonstrate that the proposed STJD-CL and STJD-MP improved performance, particularly by 3.5 and 3.6 percentage points over the state-of-the-art contrastive methods on the NTU RGB+D 120 dataset using X-sub and X-set evaluations, respectively.
Interpretable Long-term Action Quality Assessment
Aug 21, 2024Long-term Action Quality Assessment (AQA) evaluates the execution of activities in videos. However, the length presents challenges in fine-grained interpretability, with current AQA methods typically producing a single score by averaging clip features, lacking detailed semantic meanings of individual clips. Long-term videos pose additional difficulty due to the complexity and diversity of actions, exacerbating interpretability challenges. While query-based transformer networks offer promising long-term modeling capabilities, their interpretability in AQA remains unsatisfactory due to a phenomenon we term Temporal Skipping, where the model skips self-attention layers to prevent output degradation. To address this, we propose an attention loss function and a query initialization method to enhance performance and interpretability. Additionally, we introduce a weight-score regression module designed to approximate the scoring patterns observed in human judgments and replace conventional single-score regression, improving the rationality of interpretability. Our approach achieves state-of-the-art results on three real-world, long-term AQA benchmarks. Our code is available at: https://github.com/dx199771/Interpretability-AQA
Joint Temporal Pooling for Improving Skeleton-based Action Recognition
Aug 18, 2024



In skeleton-based human action recognition, temporal pooling is a critical step for capturing spatiotemporal relationship of joint dynamics. Conventional pooling methods overlook the preservation of motion information and treat each frame equally. However, in an action sequence, only a few segments of frames carry discriminative information related to the action. This paper presents a novel Joint Motion Adaptive Temporal Pooling (JMAP) method for improving skeleton-based action recognition. Two variants of JMAP, frame-wise pooling and joint-wise pooling, are introduced. The efficacy of JMAP has been validated through experiments on the popular NTU RGB+D 120 and PKU-MMD datasets.
MTVQA: Benchmarking Multilingual Text-Centric Visual Question Answering
May 20, 2024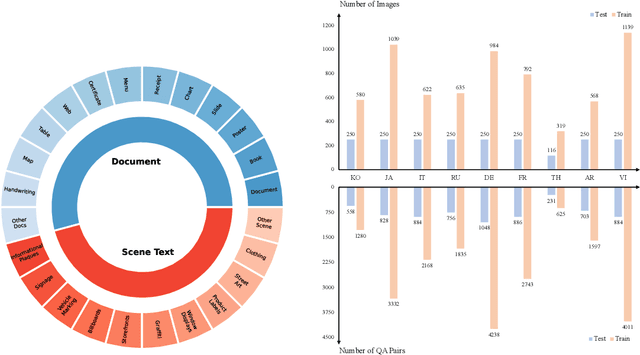

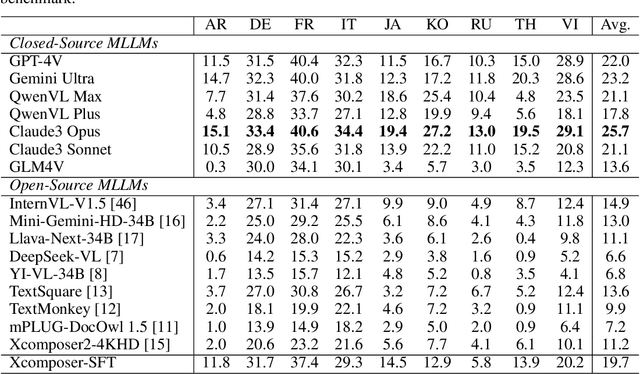
Text-Centric Visual Question Answering (TEC-VQA) in its proper format not only facilitates human-machine interaction in text-centric visual environments but also serves as a de facto gold proxy to evaluate AI models in the domain of text-centric scene understanding. However, most TEC-VQA benchmarks have focused on high-resource languages like English and Chinese. Despite pioneering works to expand multilingual QA pairs in non-text-centric VQA datasets using translation engines, the translation-based protocol encounters a substantial ``Visual-textual misalignment'' problem when applied to TEC-VQA. Specifically, it prioritizes the text in question-answer pairs while disregarding the visual text present in images. Furthermore, it does not adequately tackle challenges related to nuanced meaning, contextual distortion, language bias, and question-type diversity. In this work, we address the task of multilingual TEC-VQA and provide a benchmark with high-quality human expert annotations in 9 diverse languages, called MTVQA. To our knowledge, MTVQA is the first multilingual TEC-VQA benchmark to provide human expert annotations for text-centric scenarios. Further, by evaluating several state-of-the-art Multimodal Large Language Models (MLLMs), including GPT-4V, on our MTVQA dataset, it is evident that there is still room for performance improvement, underscoring the value of our dataset. We hope this dataset will provide researchers with fresh perspectives and inspiration within the community. The MTVQA dataset will be available at https://huggingface.co/datasets/ByteDance/MTVQA.
Unsupervised Spatial-Temporal Feature Enrichment and Fidelity Preservation Network for Skeleton based Action Recognition
Jan 25, 2024Unsupervised skeleton based action recognition has achieved remarkable progress recently. Existing unsupervised learning methods suffer from severe overfitting problem, and thus small networks are used, significantly reducing the representation capability. To address this problem, the overfitting mechanism behind the unsupervised learning for skeleton based action recognition is first investigated. It is observed that the skeleton is already a relatively high-level and low-dimension feature, but not in the same manifold as the features for action recognition. Simply applying the existing unsupervised learning method may tend to produce features that discriminate the different samples instead of action classes, resulting in the overfitting problem. To solve this problem, this paper presents an Unsupervised spatial-temporal Feature Enrichment and Fidelity Preservation framework (U-FEFP) to generate rich distributed features that contain all the information of the skeleton sequence. A spatial-temporal feature transformation subnetwork is developed using spatial-temporal graph convolutional network and graph convolutional gate recurrent unit network as the basic feature extraction network. The unsupervised Bootstrap Your Own Latent based learning is used to generate rich distributed features and the unsupervised pretext task based learning is used to preserve the information of the skeleton sequence. The two unsupervised learning ways are collaborated as U-FEFP to produce robust and discriminative representations. Experimental results on three widely used benchmarks, namely NTU-RGB+D-60, NTU-RGB+D-120 and PKU-MMD dataset, demonstrate that the proposed U-FEFP achieves the best performance compared with the state-of-the-art unsupervised learning methods. t-SNE illustrations further validate that U-FEFP can learn more discriminative features for unsupervised skeleton based action recognition.
FGO-ILNS: Tightly Coupled Multi-Sensor Integrated Navigation System Based on Factor Graph Optimization for Autonomous Underwater Vehicle
Oct 22, 2023



Multi-sensor fusion is an effective way to enhance the positioning performance of autonomous underwater vehicles (AUVs). However, underwater multi-sensor fusion faces challenges such as heterogeneous frequency and dynamic availability of sensors. Traditional filter-based algorithms suffer from low accuracy and robustness when sensors become unavailable. The factor graph optimization (FGO) can enable multi-sensor plug-and-play despite data frequency. Therefore, we present an FGO-based strapdown inertial navigation system (SINS) and long baseline location (LBL) system tightly coupled navigation system (FGO-ILNS). Sensors such as Doppler velocity log (DVL), magnetic compass pilot (MCP), pressure sensor (PS), and global navigation satellite system (GNSS) can be tightly coupled with FGO-ILNS to satisfy different navigation scenarios. In this system, we propose a floating LBL slant range difference factor model tightly coupled with IMU preintegration factor to achieve unification of global position above and below water. Furthermore, to address the issue of sensor measurements not being synchronized with the LBL during fusion, we employ forward-backward IMU preintegration to construct sensor factors such as GNSS and DVL. Moreover, we utilize the marginalization method to reduce the computational load of factor graph optimization. Simulation and public KAIST dataset experiments have verified that, compared to filter-based algorithms like the extended Kalman filter and federal Kalman filter, as well as the state-of-the-art optimization-based algorithm ORB-SLAM3, our proposed FGO-ILNS leads in accuracy and robustness.
Sub-action Prototype Learning for Point-level Weakly-supervised Temporal Action Localization
Sep 16, 2023



Point-level weakly-supervised temporal action localization (PWTAL) aims to localize actions with only a single timestamp annotation for each action instance. Existing methods tend to mine dense pseudo labels to alleviate the label sparsity, but overlook the potential sub-action temporal structures, resulting in inferior performance. To tackle this problem, we propose a novel sub-action prototype learning framework (SPL-Loc) which comprises Sub-action Prototype Clustering (SPC) and Ordered Prototype Alignment (OPA). SPC adaptively extracts representative sub-action prototypes which are capable to perceive the temporal scale and spatial content variation of action instances. OPA selects relevant prototypes to provide completeness clue for pseudo label generation by applying a temporal alignment loss. As a result, pseudo labels are derived from alignment results to improve action boundary prediction. Extensive experiments on three popular benchmarks demonstrate that the proposed SPL-Loc significantly outperforms existing SOTA PWTAL methods.
Focal and Global Spatial-Temporal Transformer for Skeleton-based Action Recognition
Oct 06, 2022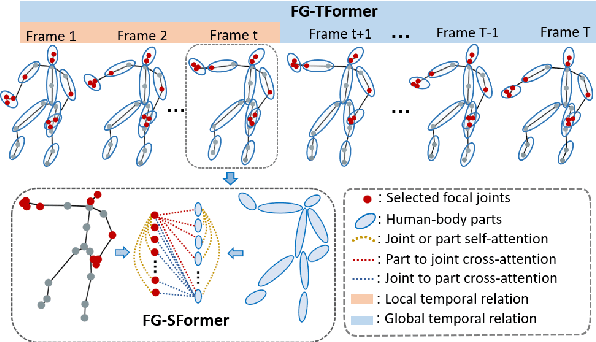
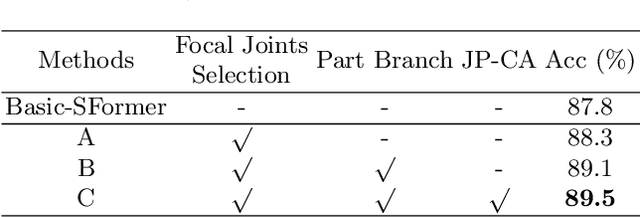
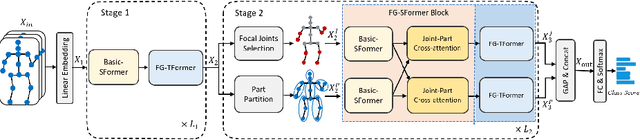

Despite great progress achieved by transformer in various vision tasks, it is still underexplored for skeleton-based action recognition with only a few attempts. Besides, these methods directly calculate the pair-wise global self-attention equally for all the joints in both the spatial and temporal dimensions, undervaluing the effect of discriminative local joints and the short-range temporal dynamics. In this work, we propose a novel Focal and Global Spatial-Temporal Transformer network (FG-STFormer), that is equipped with two key components: (1) FG-SFormer: focal joints and global parts coupling spatial transformer. It forces the network to focus on modelling correlations for both the learned discriminative spatial joints and human body parts respectively. The selective focal joints eliminate the negative effect of non-informative ones during accumulating the correlations. Meanwhile, the interactions between the focal joints and body parts are incorporated to enhance the spatial dependencies via mutual cross-attention. (2) FG-TFormer: focal and global temporal transformer. Dilated temporal convolution is integrated into the global self-attention mechanism to explicitly capture the local temporal motion patterns of joints or body parts, which is found to be vital important to make temporal transformer work. Extensive experimental results on three benchmarks, namely NTU-60, NTU-120 and NW-UCLA, show our FG-STFormer surpasses all existing transformer-based methods, and compares favourably with state-of-the art GCN-based methods.