 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Completion Learning for Language Models
Jul 27, 2025Current language model training paradigms typically terminate learning upon reaching the end-of-sequence (<eos>}) token, overlooking the potential learning opportunities in the post-completion space. We propose Post-Completion Learning (PCL), a novel training framework that systematically utilizes the sequence space after model output completion, to enhance both the reasoning and self-evaluation abilities. PCL enables models to continue generating self-assessments and reward predictions during training, while maintaining efficient inference by stopping at the completion point. To fully utilize this post-completion space, we design a white-box reinforcement learning method: let the model evaluate the output content according to the reward rules, then calculate and align the score with the reward functions for supervision. We implement dual-track SFT to optimize both reasoning and evaluation capabilities, and mixed it with RL training to achieve multi-objective hybrid optimization. Experimental results on different datasets and models demonstrate consistent improvements over traditional SFT and RL methods. Our method provides a new technical path for language model training that enhances output quality while preserving deployment efficiency.
Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting
May 20, 2025Document image parsing is challenging due to its complexly intertwined elements such as text paragraphs, figures, formulas, and tables. Current approaches either assemble specialized expert models or directly generate page-level content autoregressively, facing integration overhead, efficiency bottlenecks, and layout structure degradation despite their decent performance. To address these limitations, we present \textit{Dolphin} (\textit{\textbf{Do}cument Image \textbf{P}arsing via \textbf{H}eterogeneous Anchor Prompt\textbf{in}g}), a novel multimodal document image parsing model following an analyze-then-parse paradigm. In the first stage, Dolphin generates a sequence of layout elements in reading order. These heterogeneous elements, serving as anchors and coupled with task-specific prompts, are fed back to Dolphin for parallel content parsing in the second stage. To train Dolphin, we construct a large-scale dataset of over 30 million samples, covering multi-granularity parsing tasks. Through comprehensive evaluations on both prevalent benchmarks and self-constructed ones, Dolphin achieves state-of-the-art performance across diverse page-level and element-level settings, while ensuring superior efficiency through its lightweight architecture and parallel parsing mechanism. The code and pre-trained models are publicly available at https://github.com/ByteDance/Dolphin
Operator Feature Neural Network for Symbolic Regression
Aug 14, 2024Symbolic regression is a task aimed at identifying patterns in data and representing them through mathematical expressions, generally involving skeleton prediction and constant optimization. Many methods have achieved some success, however they treat variables and symbols merely as characters of natural language without considering their mathematical essence. This paper introduces the operator feature neural network (OF-Net) which employs operator representation for expressions and proposes an implicit feature encoding method for the intrinsic mathematical operational logic of operators. By substituting operator features for numeric loss, we can predict the combination of operators of target expressions. We evaluate the model on public datasets, and the results demonstrate that the model achieves superior recovery rates and high $R^2$ scores. With the discussion of the results, we analyze the merit and demerit of OF-Net and propose optimizing schemes.
Harmonizing Visual Text Comprehension and Generation
Jul 23, 2024



In this work, we present TextHarmony, a unified and versatile multimodal generative model proficient in comprehending and generating visual text. Simultaneously generating images and texts typically results in performance degradation due to the inherent inconsistency between vision and language modalities. To overcome this challenge, existing approaches resort to modality-specific data for supervised fine-tuning, necessitating distinct model instances. We propose Slide-LoRA, which dynamically aggregates modality-specific and modality-agnostic LoRA experts, partially decoupling the multimodal generation space. Slide-LoRA harmonizes the generation of vision and language within a singular model instance, thereby facilitating a more unified generative process. Additionally, we develop a high-quality image caption dataset, DetailedTextCaps-100K, synthesized with a sophisticated closed-source MLLM to enhance visual text generation capabilities further. Comprehensive experiments across various benchmarks demonstrate the effectiveness of the proposed approach. Empowered by Slide-LoRA, TextHarmony achieves comparable performance to modality-specific fine-tuning results with only a 2% increase in parameters and shows an average improvement of 2.5% in visual text comprehension tasks and 4.0% in visual text generation tasks. Our work delineates the viability of an integrated approach to multimodal generation within the visual text domain, setting a foundation for subsequent inquiries.
DN-CL: Deep Symbolic Regression against Noise via Contrastive Learning
Jun 21, 2024



Noise ubiquitously exists in signals due to numerous factors including physical, electronic, and environmental effects. Traditional methods of symbolic regression, such as genetic programming or deep learning models, aim to find the most fitting expressions for these signals. However, these methods often overlook the noise present in real-world data, leading to reduced fitting accuracy. To tackle this issue, we propose \textit{\textbf{D}eep Symbolic Regression against \textbf{N}oise via \textbf{C}ontrastive \textbf{L}earning (DN-CL)}. DN-CL employs two parameter-sharing encoders to embed data points from various data transformations into feature shields against noise. This model treats noisy data and clean data as different views of the ground-truth mathematical expressions. Distances between these features are minimized, utilizing contrastive learning to distinguish between 'positive' noise-corrected pairs and 'negative' contrasting pairs. Our experiments indicate that DN-CL demonstrates superior performance in handling both noisy and clean data, presenting a promising method of symbolic regression.
MLLM-SR: Conversational Symbolic Regression base Multi-Modal Large Language Models
Jun 08, 2024



Formulas are the language of communication between humans and nature. It is an important research topic of artificial intelligence to find expressions from observed data to reflect the relationship between each variable in the data, which is called a symbolic regression problem. The existing symbolic regression methods directly generate expressions according to the given observation data, and we cannot require the algorithm to generate expressions that meet specific requirements according to the known prior knowledge. For example, the expression needs to contain $\sin$ or be symmetric, and so on. Even if it can, it often requires very complex operations, which is very inconvenient. In this paper, based on multi-modal large language models, we propose MLLM-SR, a conversational symbolic regression method that can generate expressions that meet the requirements simply by describing the requirements with natural language instructions. By experimenting on the Nguyen dataset, we can demonstrate that MLLM-SR leads the state-of-the-art baselines in fitting performance. More notably, we experimentally demonstrate that MLLM-SR can well understand the prior knowledge we add to the natural language instructions. Moreover, the addition of prior knowledge can effectively guide MLLM-SR to generate correct expressions.
TabPedia: Towards Comprehensive Visual Table Understanding with Concept Synergy
Jun 03, 2024



Tables contain factual and quantitative data accompanied by various structures and contents that pose challenges for machine comprehension. Previous methods generally design task-specific architectures and objectives for individual tasks, resulting in modal isolation and intricate workflows. In this paper, we present a novel large vision-language model, TabPedia, equipped with a concept synergy mechanism. In this mechanism, all the involved diverse visual table understanding (VTU) tasks and multi-source visual embeddings are abstracted as concepts. This unified framework allows TabPedia to seamlessly integrate VTU tasks, such as table detection, table structure recognition, table querying, and table question answering, by leveraging the capabilities of large language models (LLMs). Moreover, the concept synergy mechanism enables table perception-related and comprehension-related tasks to work in harmony, as they can effectively leverage the needed clues from the corresponding source perception embeddings. Furthermore, to better evaluate the VTU task in real-world scenarios, we establish a new and comprehensive table VQA benchmark, ComTQA, featuring approximately 9,000 QA pairs. Extensive quantitative and qualitative experiments on both table perception and comprehension tasks, conducted across various public benchmarks, validate the effectiveness of our TabPedia. The superior performance further confirms the feasibility of using LLMs for understanding visual tables when all concepts work in synergy. The benchmark ComTQA has been open-sourced at https://huggingface.co/datasets/ByteDance/ComTQA. The source code and model will be released later.
Closed-form Symbolic Solutions: A New Perspective on Solving Partial Differential Equations
May 23, 2024Solving partial differential equations (PDEs) in Euclidean space with closed-form symbolic solutions has long been a dream for mathematicians. Inspired by deep learning, Physics-Informed Neural Networks (PINNs) have shown great promise in numerically solving PDEs. However, since PINNs essentially approximate solutions within the continuous function space, their numerical solutions fall short in both precision and interpretability compared to symbolic solutions. This paper proposes a novel framework: a closed-form \textbf{Sym}bolic framework for \textbf{PDE}s (SymPDE), exploring the use of deep reinforcement learning to directly obtain symbolic solutions for PDEs. SymPDE alleviates the challenges PINNs face in fitting high-frequency and steeply changing functions. To our knowledge, no prior work has implemented this approach. Experiments on solving the Poisson's equation and heat equation in time-independent and spatiotemporal dynamical systems respectively demonstrate that SymPDE can provide accurate closed-form symbolic solutions for various types of PDEs.
MTVQA: Benchmarking Multilingual Text-Centric Visual Question Answering
May 20, 2024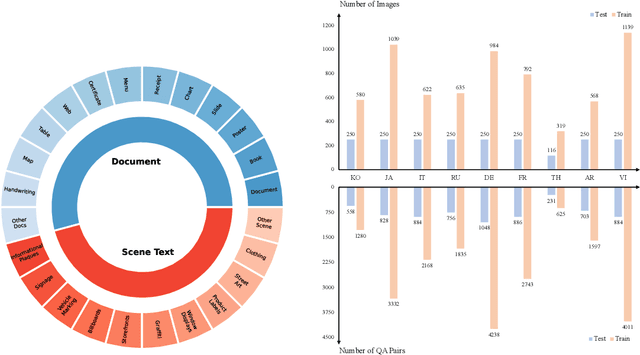
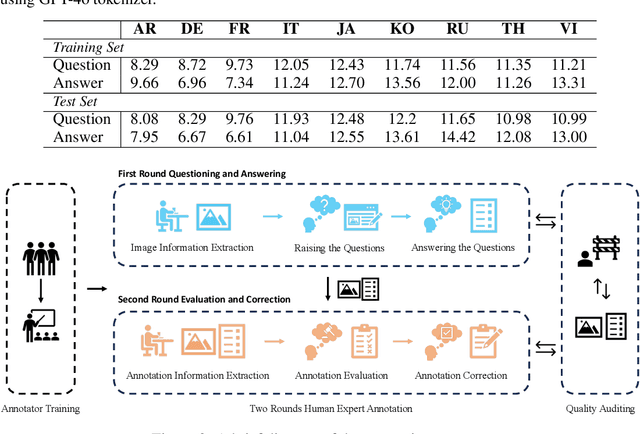

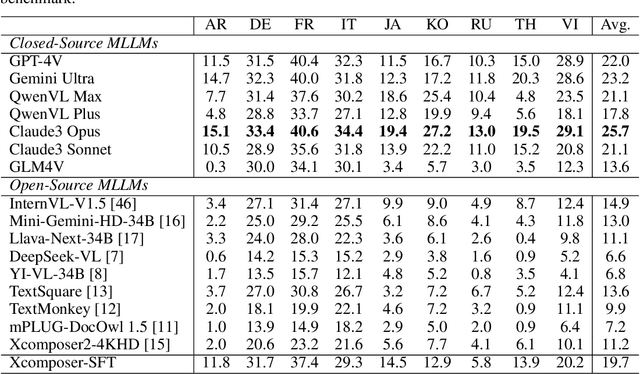
Text-Centric Visual Question Answering (TEC-VQA) in its proper format not only facilitates human-machine interaction in text-centric visual environments but also serves as a de facto gold proxy to evaluate AI models in the domain of text-centric scene understanding. However, most TEC-VQA benchmarks have focused on high-resource languages like English and Chinese. Despite pioneering works to expand multilingual QA pairs in non-text-centric VQA datasets using translation engines, the translation-based protocol encounters a substantial ``Visual-textual misalignment'' problem when applied to TEC-VQA. Specifically, it prioritizes the text in question-answer pairs while disregarding the visual text present in images. Furthermore, it does not adequately tackle challenges related to nuanced meaning, contextual distortion, language bias, and question-type diversity. In this work, we address the task of multilingual TEC-VQA and provide a benchmark with high-quality human expert annotations in 9 diverse languages, called MTVQA. To our knowledge, MTVQA is the first multilingual TEC-VQA benchmark to provide human expert annotations for text-centric scenarios. Further, by evaluating several state-of-the-art Multimodal Large Language Models (MLLMs), including GPT-4V, on our MTVQA dataset, it is evident that there is still room for performance improvement, underscoring the value of our dataset. We hope this dataset will provide researchers with fresh perspectives and inspiration within the community. The MTVQA dataset will be available at https://huggingface.co/datasets/ByteDance/MTVQA.
TextSquare: Scaling up Text-Centric Visual Instruction Tuning
Apr 19, 2024



Text-centric visual question answering (VQA) has made great strides with the development of Multimodal Large Language Models (MLLMs), yet open-source models still fall short of leading models like GPT4V and Gemini, partly due to a lack of extensive, high-quality instruction tuning data. To this end, we introduce a new approach for creating a massive, high-quality instruction-tuning dataset, Square-10M, which is generated using closed-source MLLMs. The data construction process, termed Square, consists of four steps: Self-Questioning, Answering, Reasoning, and Evaluation. Our experiments with Square-10M led to three key findings: 1) Our model, TextSquare, considerably surpasses open-source previous state-of-the-art Text-centric MLLMs and sets a new standard on OCRBench(62.2%). It even outperforms top-tier models like GPT4V and Gemini in 6 of 10 text-centric benchmarks. 2) Additionally, we demonstrate the critical role of VQA reasoning data in offering comprehensive contextual insights for specific questions. This not only improves accuracy but also significantly mitigates hallucinations. Specifically, TextSquare scores an average of 75.1% across four general VQA and hallucination evaluation datasets, outperforming previous state-of-the-art models. 3) Notably, the phenomenon observed in scaling text-centric VQA datasets reveals a vivid pattern: the exponential increase of instruction tuning data volume is directly proportional to the improvement in model performance, thereby validating the necessity of the dataset scale and the high quality of Square-10M.