 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Depth Estimation From the Perspective of Feature Restoration: A Diffusion Enhanced Depth Restoration Approach
Apr 09, 2026Monocular Depth Estimation (MDE) is a fundamental computer vision task with important applications in 3D vision. The current mainstream MDE methods employ an encoder-decoder architecture with multi-level/scale feature processing. However, the limitations of the current architecture and the effects of different-level features on the prediction accuracy are not evaluated. In this paper, we first investigate the above problem and show that there is still substantial potential in the current framework if encoder features can be improved. Therefore, we propose to formulate the depth estimation problem from the feature restoration perspective, by treating pretrained encoder features as degraded features of an assumed ground truth feature that yields the ground truth depth map. Then an Invertible Transform-enhanced Indirect Diffusion (InvT-IndDiffusion) module is developed for feature restoration. Due to the absence of direct supervision on feature, only indirect supervision from the final sparse depth map is used. During the iterative procedure of diffusion, this results in feature deviations among steps. The proposed InvT-IndDiffusion solves this problem by using an invertible transform-based decoder under the bi-Lipschitz condition. Finally, a plug-and-play Auxiliary Viewpoint-based Low-level Feature Enhancement module (AV-LFE) is developed to enhance local details with auxiliary viewpoint when available. Experiments demonstrate that the proposed method achieves better performance than the state-of-the-art methods on various datasets. Specifically on the KITTI benchmark, compared with the baseline, the performance is improved by 4.09% and 37.77% under different training settings in terms of RMSE. Code is available at https://github.com/whitehb1/IID-RDepth.
Adaptive Depth-converted-Scale Convolution for Self-supervised Monocular Depth Estimation
Apr 09, 2026Self-supervised monocular depth estimation (MDE) has received increasing interests in the last few years. The objects in the scene, including the object size and relationship among different objects, are the main clues to extract the scene structure. However, previous works lack the explicit handling of the changing sizes of the object due to the change of its depth. Especially in a monocular video, the size of the same object is continuously changed, resulting in size and depth ambiguity. To address this problem, we propose a Depth-converted-Scale Convolution (DcSConv) enhanced monocular depth estimation framework, by incorporating the prior relationship between the object depth and object scale to extract features from appropriate scales of the convolution receptive field. The proposed DcSConv focuses on the adaptive scale of the convolution filter instead of the local deformation of its shape. It establishes that the scale of the convolution filter matters no less (or even more in the evaluated task) than its local deformation. Moreover, a Depth-converted-Scale aware Fusion (DcS-F) is developed to adaptively fuse the DcSConv features and the conventional convolution features. Our DcSConv enhanced monocular depth estimation framework can be applied on top of existing CNN based methods as a plug-and-play module to enhance the conventional convolution block. Extensive experiments with different baselines have been conducted on the KITTI benchmark and our method achieves the best results with an improvement up to 11.6% in terms of SqRel reduction. Ablation study also validates the effectiveness of each proposed module.
A Noise Constrained Diffusion (NC-Diffusion) Framework for High Fidelity Image Compression
Apr 08, 2026With the great success of diffusion models in image generation, diffusion-based image compression is attracting increasing interests. However, due to the random noise introduced in the diffusion learning, they usually produce reconstructions with deviation from the original images, leading to suboptimal compression results. To address this problem, in this paper, we propose a Noise Constrained Diffusion (NC-Diffusion) framework for high fidelity image compression. Unlike existing diffusion-based compression methods that add random Gaussian noise and direct the noise into the image space, the proposed NC-Diffusion formulates the quantization noise originally added in the learned image compression as the noise in the forward process of diffusion. Then a noise constrained diffusion process is constructed from the ground-truth image to the initial compression result generated with quantization noise. The NC-Diffusion overcomes the problem of noise mismatch between compression and diffusion, significantly improving the inference efficiency. In addition, an adaptive frequency-domain filtering module is developed to enhance the skip connections in the U-Net based diffusion architecture, in order to enhance high-frequency details. Moreover, a zero-shot sample-guided enhancement method is designed to further improve the fidelity of the image. Experiments on multiple benchmark datasets demonstrate that our method can achieve the best performance compared with existing methods.
LiftFormer: Lifting and Frame Theory Based Monocular Depth Estimation Using Depth and Edge Oriented Subspace Representation
Apr 08, 2026Monocular depth estimation (MDE) has attracted increasing interest in the past few years, owing to its important role in 3D vision. MDE is the estimation of a depth map from a monocular image/video to represent the 3D structure of a scene, which is a highly ill-posed problem. To solve this problem, in this paper, we propose a LiftFormer based on lifting theory topology, for constructing an intermediate subspace that bridges the image color features and depth values, and a subspace that enhances the depth prediction around edges. MDE is formulated by transforming the depth value prediction problem into depth-oriented geometric representation (DGR) subspace feature representation, thus bridging the learning from color values to geometric depth values. A DGR subspace is constructed based on frame theory by using linearly dependent vectors in accordance with depth bins to provide a redundant and robust representation. The image spatial features are transformed into the DGR subspace, where these features correspond directly to the depth values. Moreover, considering that edges usually present sharp changes in a depth map and tend to be erroneously predicted, an edge-aware representation (ER) subspace is constructed, where depth features are transformed and further used to enhance the local features around edges. The experimental results demonstrate that our LiftFormer achieves state-of-the-art performance on widely used datasets, and an ablation study validates the effectiveness of both proposed lifting modules in our LiftFormer.
CWRNN-INVR: A Coupled WarpRNN based Implicit Neural Video Representation
Apr 08, 2026Implicit Neural Video Representation (INVR) has emerged as a novel approach for video representation and compression, using learnable grids and neural networks. Existing methods focus on developing new grid structures efficient for latent representation and neural network architectures with large representation capability, lacking the study on their roles in video representation. In this paper, the difference between INVR based on neural network and INVR based on grid is first investigated from the perspective of video information composition to specify their own advantages, i.e., neural network for general structure while grid for specific detail. Accordingly, an INVR based on mixed neural network and residual grid framework is proposed, where the neural network is used to represent the regular and structured information and the residual grid is used to represent the remaining irregular information in a video. A Coupled WarpRNN-based multi-scale motion representation and compensation module is specifically designed to explicitly represent the regular and structured information, thus terming our method as CWRNN-INVR. For the irregular information, a mixed residual grid is learned where the irregular appearance and motion information are represented together. The mixed residual grid can be combined with the coupled WarpRNN in a way that allows for network reuse. Experiments show that our method achieves the best reconstruction results compared with the existing methods, with an average PSNR of 33.73 dB on the UVG dataset under the 3M model and outperforms existing INVR methods in other downstream tasks. The code can be found at https://github.com/yiyang-sdu/CWRNN-INVR.git}{https://github.com/yiyang-sdu/CWRNN-INVR.git.
MetricGrids: Arbitrary Nonlinear Approximation with Elementary Metric Grids based Implicit Neural Representation
Mar 13, 2025



This paper presents MetricGrids, a novel grid-based neural representation that combines elementary metric grids in various metric spaces to approximate complex nonlinear signals. While grid-based representations are widely adopted for their efficiency and scalability, the existing feature grids with linear indexing for continuous-space points can only provide degenerate linear latent space representations, and such representations cannot be adequately compensated to represent complex nonlinear signals by the following compact decoder. To address this problem while keeping the simplicity of a regular grid structure, our approach builds upon the standard grid-based paradigm by constructing multiple elementary metric grids as high-order terms to approximate complex nonlinearities, following the Taylor expansion principle. Furthermore, we enhance model compactness with hash encoding based on different sparsities of the grids to prevent detrimental hash collisions, and a high-order extrapolation decoder to reduce explicit grid storage requirements. experimental results on both 2D and 3D reconstructions demonstrate the superior fitting and rendering accuracy of the proposed method across diverse signal types, validating its robustness and generalizability. Code is available at https://github.com/wangshu31/MetricGrids}{https://github.com/wangshu31/MetricGrids.
Approximately Invertible Neural Network for Learned Image Compression
Aug 30, 2024



Learned image compression have attracted considerable interests in recent years. It typically comprises an analysis transform, a synthesis transform, quantization and an entropy coding model. The analysis transform and synthesis transform are used to encode an image to latent feature and decode the quantized feature to reconstruct the image, and can be regarded as coupled transforms. However, the analysis transform and synthesis transform are designed independently in the existing methods, making them unreliable in high-quality image compression. Inspired by the invertible neural networks in generative modeling, invertible modules are used to construct the coupled analysis and synthesis transforms. Considering the noise introduced in the feature quantization invalidates the invertible process, this paper proposes an Approximately Invertible Neural Network (A-INN) framework for learned image compression. It formulates the rate-distortion optimization in lossy image compression when using INN with quantization, which differentiates from using INN for generative modelling. Generally speaking, A-INN can be used as the theoretical foundation for any INN based lossy compression method. Based on this formulation, A-INN with a progressive denoising module (PDM) is developed to effectively reduce the quantization noise in the decoding. Moreover, a Cascaded Feature Recovery Module (CFRM) is designed to learn high-dimensional feature recovery from low-dimensional ones to further reduce the noise in feature channel compression. In addition, a Frequency-enhanced Decomposition and Synthesis Module (FDSM) is developed by explicitly enhancing the high-frequency components in an image to address the loss of high-frequency information inherent in neural network based image compression. Extensive experiments demonstrate that the proposed A-INN outperforms the existing learned image compression methods.
Unsupervised Spatial-Temporal Feature Enrichment and Fidelity Preservation Network for Skeleton based Action Recognition
Jan 25, 2024Unsupervised skeleton based action recognition has achieved remarkable progress recently. Existing unsupervised learning methods suffer from severe overfitting problem, and thus small networks are used, significantly reducing the representation capability. To address this problem, the overfitting mechanism behind the unsupervised learning for skeleton based action recognition is first investigated. It is observed that the skeleton is already a relatively high-level and low-dimension feature, but not in the same manifold as the features for action recognition. Simply applying the existing unsupervised learning method may tend to produce features that discriminate the different samples instead of action classes, resulting in the overfitting problem. To solve this problem, this paper presents an Unsupervised spatial-temporal Feature Enrichment and Fidelity Preservation framework (U-FEFP) to generate rich distributed features that contain all the information of the skeleton sequence. A spatial-temporal feature transformation subnetwork is developed using spatial-temporal graph convolutional network and graph convolutional gate recurrent unit network as the basic feature extraction network. The unsupervised Bootstrap Your Own Latent based learning is used to generate rich distributed features and the unsupervised pretext task based learning is used to preserve the information of the skeleton sequence. The two unsupervised learning ways are collaborated as U-FEFP to produce robust and discriminative representations. Experimental results on three widely used benchmarks, namely NTU-RGB+D-60, NTU-RGB+D-120 and PKU-MMD dataset, demonstrate that the proposed U-FEFP achieves the best performance compared with the state-of-the-art unsupervised learning methods. t-SNE illustrations further validate that U-FEFP can learn more discriminative features for unsupervised skeleton based action recognition.
Spatial-Temporal Transformer based Video Compression Framework
Sep 21, 2023Learned video compression (LVC) has witnessed remarkable advancements in recent years. Similar as the traditional video coding, LVC inherits motion estimation/compensation, residual coding and other modules, all of which are implemented with neural networks (NNs). However, within the framework of NNs and its training mechanism using gradient backpropagation, most existing works often struggle to consistently generate stable motion information, which is in the form of geometric features, from the input color features. Moreover, the modules such as the inter-prediction and residual coding are independent from each other, making it inefficient to fully reduce the spatial-temporal redundancy. To address the above problems, in this paper, we propose a novel Spatial-Temporal Transformer based Video Compression (STT-VC) framework. It contains a Relaxed Deformable Transformer (RDT) with Uformer based offsets estimation for motion estimation and compensation, a Multi-Granularity Prediction (MGP) module based on multi-reference frames for prediction refinement, and a Spatial Feature Distribution prior based Transformer (SFD-T) for efficient temporal-spatial joint residual compression. Specifically, RDT is developed to stably estimate the motion information between frames by thoroughly investigating the relationship between the similarity based geometric motion feature extraction and self-attention. MGP is designed to fuse the multi-reference frame information by effectively exploring the coarse-grained prediction feature generated with the coded motion information. SFD-T is to compress the residual information by jointly exploring the spatial feature distributions in both residual and temporal prediction to further reduce the spatial-temporal redundancy. Experimental results demonstrate that our method achieves the best result with 13.5% BD-Rate saving over VTM.
A Global Appearance and Local Coding Distortion based Fusion Framework for CNN based Filtering in Video Coding
Jun 24, 2021

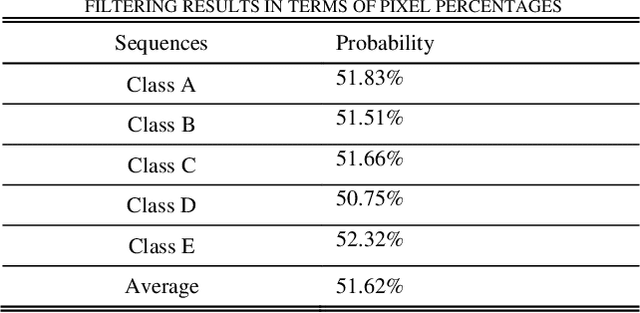
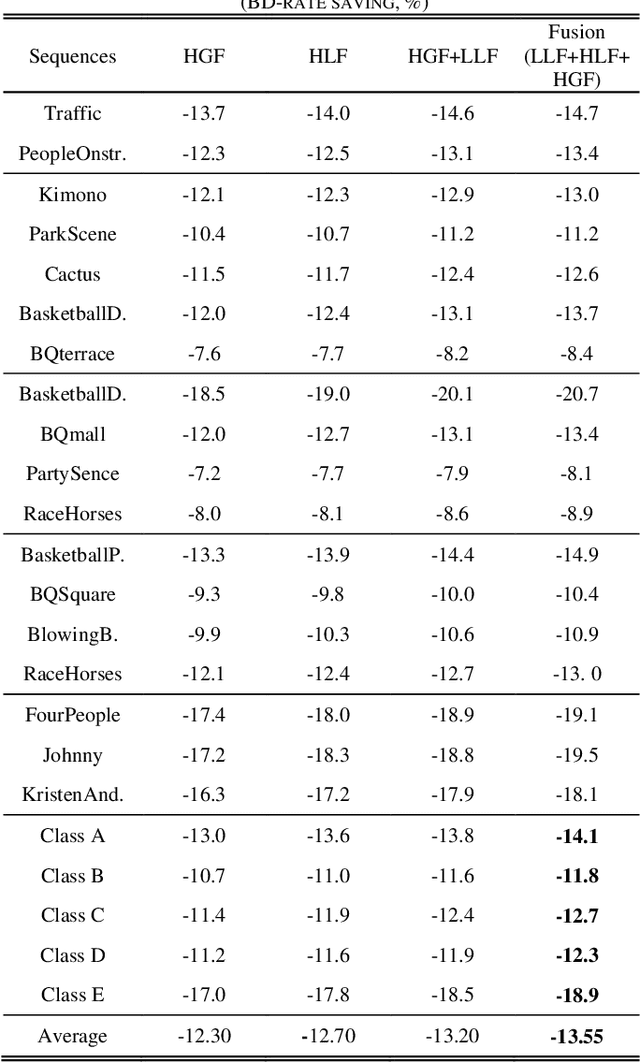
In-loop filtering is used in video coding to process the reconstructed frame in order to remove blocking artifacts. With the development of convolutional neural networks (CNNs), CNNs have been explored for in-loop filtering considering it can be treated as an image de-noising task. However, in addition to being a distorted image, the reconstructed frame is also obtained by a fixed line of block based encoding operations in video coding. It carries coding-unit based coding distortion of some similar characteristics. Therefore, in this paper, we address the filtering problem from two aspects, global appearance restoration for disrupted texture and local coding distortion restoration caused by fixed pipeline of coding. Accordingly, a three-stream global appearance and local coding distortion based fusion network is developed with a high-level global feature stream, a high-level local feature stream and a low-level local feature stream. Ablation study is conducted to validate the necessity of different features, demonstrating that the global features and local features can complement each other in filtering and achieve better performance when combined. To the best of our knowledge, we are the first one that clearly characterizes the video filtering process from the above global appearance and local coding distortion restoration aspects with experimental verification, providing a clear pathway to developing filter techniques. Experimental results demonstrate that the proposed method significantly outperforms the existing single-frame based methods and achieves 13.5%, 11.3%, 11.7% BD-Rate saving on average for AI, LDP and RA configurations, respectively, compared with the HEVC reference software.