 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMR-GDINO: Efficient Open-World Continual Object Detection
Dec 23, 2024



Open-world (OW) recognition and detection models show strong zero- and few-shot adaptation abilities, inspiring their use as initializations in continual learning methods to improve performance. Despite promising results on seen classes, such OW abilities on unseen classes are largely degenerated due to catastrophic forgetting. To tackle this challenge, we propose an open-world continual object detection task, requiring detectors to generalize to old, new, and unseen categories in continual learning scenarios. Based on this task, we present a challenging yet practical OW-COD benchmark to assess detection abilities. The goal is to motivate OW detectors to simultaneously preserve learned classes, adapt to new classes, and maintain open-world capabilities under few-shot adaptations. To mitigate forgetting in unseen categories, we propose MR-GDINO, a strong, efficient and scalable baseline via memory and retrieval mechanisms within a highly scalable memory pool. Experimental results show that existing continual detectors suffer from severe forgetting for both seen and unseen categories. In contrast, MR-GDINO largely mitigates forgetting with only 0.1% activated extra parameters, achieving state-of-the-art performance for old, new, and unseen categories.
Retrieval Augmented Image Harmonization
Dec 18, 2024



When embedding objects (foreground) into images (background), considering the influence of photography conditions like illumination, it is usually necessary to perform image harmonization to make the foreground object coordinate with the background image in terms of brightness, color, and etc. Although existing image harmonization methods have made continuous efforts toward visually pleasing results, they are still plagued by two main issues. Firstly, the image harmonization becomes highly ill-posed when there are no contents similar to the foreground object in the background, making the harmonization results unreliable. Secondly, even when similar contents are available, the harmonization process is often interfered with by irrelevant areas, mainly attributed to an insufficient understanding of image contents and inaccurate attention. As a remedy, we present a retrieval-augmented image harmonization (Raiha) framework, which seeks proper reference images to reduce the ill-posedness and restricts the attention to better utilize the useful information. Specifically, an efficient retrieval method is designed to find reference images that contain similar objects as the foreground while the illumination is consistent with the background. For training the Raiha framework to effectively utilize the reference information, a data augmentation strategy is delicately designed by leveraging existing non-reference image harmonization datasets. Besides, the image content priors are introduced to ensure reasonable attention. With the presented Raiha framework, the image harmonization performance is greatly boosted under both non-reference and retrieval-augmented settings. The source code and pre-trained models will be publicly available.
Generative Inbetweening through Frame-wise Conditions-Driven Video Generation
Dec 16, 2024



Generative inbetweening aims to generate intermediate frame sequences by utilizing two key frames as input. Although remarkable progress has been made in video generation models, generative inbetweening still faces challenges in maintaining temporal stability due to the ambiguous interpolation path between two key frames. This issue becomes particularly severe when there is a large motion gap between input frames. In this paper, we propose a straightforward yet highly effective Frame-wise Conditions-driven Video Generation (FCVG) method that significantly enhances the temporal stability of interpolated video frames. Specifically, our FCVG provides an explicit condition for each frame, making it much easier to identify the interpolation path between two input frames and thus ensuring temporally stable production of visually plausible video frames. To achieve this, we suggest extracting matched lines from two input frames that can then be easily interpolated frame by frame, serving as frame-wise conditions seamlessly integrated into existing video generation models. In extensive evaluations covering diverse scenarios such as natural landscapes, complex human poses, camera movements and animations, existing methods often exhibit incoherent transitions across frames. In contrast, our FCVG demonstrates the capability to generate temporally stable videos using both linear and non-linear interpolation curves. Our project page and code are available at \url{https://fcvg-inbetween.github.io/}.
Diffusion-Enhanced Test-time Adaptation with Text and Image Augmentation
Dec 12, 2024Existing test-time prompt tuning (TPT) methods focus on single-modality data, primarily enhancing images and using confidence ratings to filter out inaccurate images. However, while image generation models can produce visually diverse images, single-modality data enhancement techniques still fail to capture the comprehensive knowledge provided by different modalities. Additionally, we note that the performance of TPT-based methods drops significantly when the number of augmented images is limited, which is not unusual given the computational expense of generative augmentation. To address these issues, we introduce IT3A, a novel test-time adaptation method that utilizes a pre-trained generative model for multi-modal augmentation of each test sample from unknown new domains. By combining augmented data from pre-trained vision and language models, we enhance the ability of the model to adapt to unknown new test data. Additionally, to ensure that key semantics are accurately retained when generating various visual and text enhancements, we employ cosine similarity filtering between the logits of the enhanced images and text with the original test data. This process allows us to filter out some spurious augmentation and inadequate combinations. To leverage the diverse enhancements provided by the generation model across different modals, we have replaced prompt tuning with an adapter for greater flexibility in utilizing text templates. Our experiments on the test datasets with distribution shifts and domain gaps show that in a zero-shot setting, IT3A outperforms state-of-the-art test-time prompt tuning methods with a 5.50% increase in accuracy.
* Accepted by International Journal of Computer Vision
Learning Spatially Decoupled Color Representations for Facial Image Colorization
Dec 10, 2024Image colorization methods have shown prominent performance on natural images. However, since humans are more sensitive to faces, existing methods are insufficient to meet the demands when applied to facial images, typically showing unnatural and uneven colorization results. In this paper, we investigate the facial image colorization task and find that the problems with facial images can be attributed to an insufficient understanding of facial components. As a remedy, by introducing facial component priors, we present a novel facial image colorization framework dubbed FCNet. Specifically, we learn a decoupled color representation for each face component (e.g., lips, skin, eyes, and hair) under the guidance of face parsing maps. A chromatic and spatial augmentation strategy is presented to facilitate the learning procedure, which requires only grayscale and color facial image pairs. After training, the presented FCNet can be naturally applied to facial image colorization with single or multiple reference images. To expand the application paradigms to scenarios with no reference images, we further train two alternative modules, which predict the color representations from the grayscale input or a random seed, respectively. Extensive experiments show that our method can perform favorably against existing methods in various application scenarios (i.e., no-, single-, and multi-reference facial image colorization). The source code and pre-trained models will be publicly available.
Deblur4DGS: 4D Gaussian Splatting from Blurry Monocular Video
Dec 09, 2024



Recent 4D reconstruction methods have yielded impressive results but rely on sharp videos as supervision. However, motion blur often occurs in videos due to camera shake and object movement, while existing methods render blurry results when using such videos for reconstructing 4D models. Although a few NeRF-based approaches attempted to address the problem, they struggled to produce high-quality results, due to the inaccuracy in estimating continuous dynamic representations within the exposure time. Encouraged by recent works in 3D motion trajectory modeling using 3D Gaussian Splatting (3DGS), we suggest taking 3DGS as the scene representation manner, and propose the first 4D Gaussian Splatting framework to reconstruct a high-quality 4D model from blurry monocular video, named Deblur4DGS. Specifically, we transform continuous dynamic representations estimation within an exposure time into the exposure time estimation. Moreover, we introduce exposure regularization to avoid trivial solutions, as well as multi-frame and multi-resolution consistency ones to alleviate artifacts. Furthermore, to better represent objects with large motion, we suggest blur-aware variable canonical Gaussians. Beyond novel-view synthesis, Deblur4DGS can be applied to improve blurry video from multiple perspectives, including deblurring, frame interpolation, and video stabilization. Extensive experiments on the above four tasks show that Deblur4DGS outperforms state-of-the-art 4D reconstruction methods. The codes are available at https://github.com/ZcsrenlongZ/Deblur4DGS.
Class Balance Matters to Active Class-Incremental Learning
Dec 09, 2024



Few-Shot Class-Incremental Learning has shown remarkable efficacy in efficient learning new concepts with limited annotations. Nevertheless, the heuristic few-shot annotations may not always cover the most informative samples, which largely restricts the capability of incremental learner. We aim to start from a pool of large-scale unlabeled data and then annotate the most informative samples for incremental learning. Based on this premise, this paper introduces the Active Class-Incremental Learning (ACIL). The objective of ACIL is to select the most informative samples from the unlabeled pool to effectively train an incremental learner, aiming to maximize the performance of the resulting model. Note that vanilla active learning algorithms suffer from class-imbalanced distribution among annotated samples, which restricts the ability of incremental learning. To achieve both class balance and informativeness in chosen samples, we propose Class-Balanced Selection (CBS) strategy. Specifically, we first cluster the features of all unlabeled images into multiple groups. Then for each cluster, we employ greedy selection strategy to ensure that the Gaussian distribution of the sampled features closely matches the Gaussian distribution of all unlabeled features within the cluster. Our CBS can be plugged and played into those CIL methods which are based on pretrained models with prompts tunning technique. Extensive experiments under ACIL protocol across five diverse datasets demonstrate that CBS outperforms both random selection and other SOTA active learning approaches. Code is publicly available at https://github.com/1170300714/CBS.
Seeing Beyond Views: Multi-View Driving Scene Video Generation with Holistic Attention
Dec 04, 2024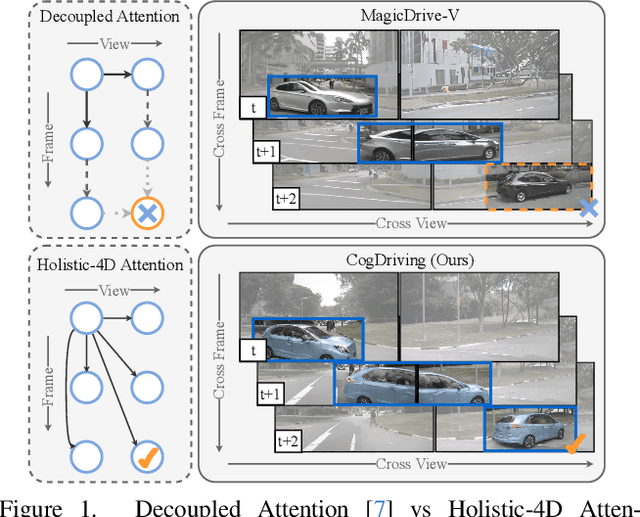



Generating multi-view videos for autonomous driving training has recently gained much attention, with the challenge of addressing both cross-view and cross-frame consistency. Existing methods typically apply decoupled attention mechanisms for spatial, temporal, and view dimensions. However, these approaches often struggle to maintain consistency across dimensions, particularly when handling fast-moving objects that appear at different times and viewpoints. In this paper, we present CogDriving, a novel network designed for synthesizing high-quality multi-view driving videos. CogDriving leverages a Diffusion Transformer architecture with holistic-4D attention modules, enabling simultaneous associations across the spatial, temporal, and viewpoint dimensions. We also propose a lightweight controller tailored for CogDriving, i.e., Micro-Controller, which uses only 1.1% of the parameters of the standard ControlNet, enabling precise control over Bird's-Eye-View layouts. To enhance the generation of object instances crucial for autonomous driving, we propose a re-weighted learning objective, dynamically adjusting the learning weights for object instances during training. CogDriving demonstrates strong performance on the nuScenes validation set, achieving an FVD score of 37.8, highlighting its ability to generate realistic driving videos. The project can be found at https://luhannan.github.io/CogDrivingPage/.
Don't Let Your Robot be Harmful: Responsible Robotic Manipulation
Nov 27, 2024Unthinking execution of human instructions in robotic manipulation can lead to severe safety risks, such as poisonings, fires, and even explosions. In this paper, we present responsible robotic manipulation, which requires robots to consider potential hazards in the real-world environment while completing instructions and performing complex operations safely and efficiently. However, such scenarios in real world are variable and risky for training. To address this challenge, we propose Safety-as-policy, which includes (i) a world model to automatically generate scenarios containing safety risks and conduct virtual interactions, and (ii) a mental model to infer consequences with reflections and gradually develop the cognition of safety, allowing robots to accomplish tasks while avoiding dangers. Additionally, we create the SafeBox synthetic dataset, which includes one hundred responsible robotic manipulation tasks with different safety risk scenarios and instructions, effectively reducing the risks associated with real-world experiments. Experiments demonstrate that Safety-as-policy can avoid risks and efficiently complete tasks in both synthetic dataset and real-world experiments, significantly outperforming baseline methods. Our SafeBox dataset shows consistent evaluation results with real-world scenarios, serving as a safe and effective benchmark for future research.
Deciphering the Chaos: Enhancing Jailbreak Attacks via Adversarial Prompt Translation
Oct 15, 2024Automatic adversarial prompt generation provides remarkable success in jailbreaking safely-aligned large language models (LLMs). Existing gradient-based attacks, while demonstrating outstanding performance in jailbreaking white-box LLMs, often generate garbled adversarial prompts with chaotic appearance. These adversarial prompts are difficult to transfer to other LLMs, hindering their performance in attacking unknown victim models. In this paper, for the first time, we delve into the semantic meaning embedded in garbled adversarial prompts and propose a novel method that "translates" them into coherent and human-readable natural language adversarial prompts. In this way, we can effectively uncover the semantic information that triggers vulnerabilities of the model and unambiguously transfer it to the victim model, without overlooking the adversarial information hidden in the garbled text, to enhance jailbreak attacks. It also offers a new approach to discovering effective designs for jailbreak prompts, advancing the understanding of jailbreak attacks. Experimental results demonstrate that our method significantly improves the success rate of jailbreak attacks against various safety-aligned LLMs and outperforms state-of-the-arts by large margins. With at most 10 queries, our method achieves an average attack success rate of 81.8% in attacking 7 commercial closed-source LLMs, including GPT and Claude-3 series, on HarmBench. Our method also achieves over 90% attack success rates against Llama-2-Chat models on AdvBench, despite their outstanding resistance to jailbreak attacks. Code at: https://github.com/qizhangli/Adversarial-Prompt-Translator.