 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Conflict-Resolution Decision Transformer for Offline Multi-Task Reinforcement Learning
Nov 17, 2025Multi-task reinforcement learning (MTRL) seeks to learn a unified policy for diverse tasks, but often suffers from gradient conflicts across tasks. Existing masking-based methods attempt to mitigate such conflicts by assigning task-specific parameter masks. However, our empirical study shows that coarse-grained binary masks have the problem of over-suppressing key conflicting parameters, hindering knowledge sharing across tasks. Moreover, different tasks exhibit varying conflict levels, yet existing methods use a one-size-fits-all fixed sparsity strategy to keep training stability and performance, which proves inadequate. These limitations hinder the model's generalization and learning efficiency. To address these issues, we propose SoCo-DT, a Soft Conflict-resolution method based by parameter importance. By leveraging Fisher information, mask values are dynamically adjusted to retain important parameters while suppressing conflicting ones. In addition, we introduce a dynamic sparsity adjustment strategy based on the Interquartile Range (IQR), which constructs task-specific thresholding schemes using the distribution of conflict and harmony scores during training. To enable adaptive sparsity evolution throughout training, we further incorporate an asymmetric cosine annealing schedule to continuously update the threshold. Experimental results on the Meta-World benchmark show that SoCo-DT outperforms the state-of-the-art method by 7.6% on MT50 and by 10.5% on the suboptimal dataset, demonstrating its effectiveness in mitigating gradient conflicts and improving overall multi-task performance.
Seeing Beyond Views: Multi-View Driving Scene Video Generation with Holistic Attention
Dec 04, 2024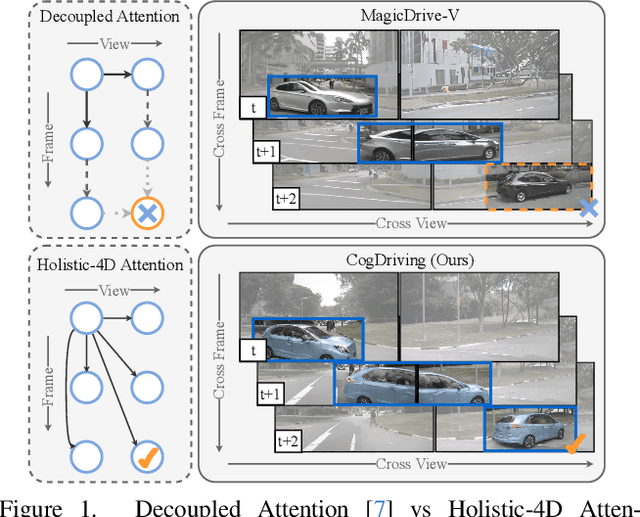



Generating multi-view videos for autonomous driving training has recently gained much attention, with the challenge of addressing both cross-view and cross-frame consistency. Existing methods typically apply decoupled attention mechanisms for spatial, temporal, and view dimensions. However, these approaches often struggle to maintain consistency across dimensions, particularly when handling fast-moving objects that appear at different times and viewpoints. In this paper, we present CogDriving, a novel network designed for synthesizing high-quality multi-view driving videos. CogDriving leverages a Diffusion Transformer architecture with holistic-4D attention modules, enabling simultaneous associations across the spatial, temporal, and viewpoint dimensions. We also propose a lightweight controller tailored for CogDriving, i.e., Micro-Controller, which uses only 1.1% of the parameters of the standard ControlNet, enabling precise control over Bird's-Eye-View layouts. To enhance the generation of object instances crucial for autonomous driving, we propose a re-weighted learning objective, dynamically adjusting the learning weights for object instances during training. CogDriving demonstrates strong performance on the nuScenes validation set, achieving an FVD score of 37.8, highlighting its ability to generate realistic driving videos. The project can be found at https://luhannan.github.io/CogDrivingPage/.
Controllable Talking Face Generation by Implicit Facial Keypoints Editing
Jun 05, 2024Audio-driven talking face generation has garnered significant interest within the domain of digital human research. Existing methods are encumbered by intricate model architectures that are intricately dependent on each other, complicating the process of re-editing image or video inputs. In this work, we present ControlTalk, a talking face generation method to control face expression deformation based on driven audio, which can construct the head pose and facial expression including lip motion for both single image or sequential video inputs in a unified manner. By utilizing a pre-trained video synthesis renderer and proposing the lightweight adaptation, ControlTalk achieves precise and naturalistic lip synchronization while enabling quantitative control over mouth opening shape. Our experiments show that our method is superior to state-of-the-art performance on widely used benchmarks, including HDTF and MEAD. The parameterized adaptation demonstrates remarkable generalization capabilities, effectively handling expression deformation across same-ID and cross-ID scenarios, and extending its utility to out-of-domain portraits, regardless of languages.