 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Low Back Movement with Motion Tape Sensor Data Through Deep Learning
Feb 12, 2026Back pain is a pervasive issue affecting a significant portion of the population, often worsened by certain movements of the lower back. Assessing these movements is important for helping clinicians prescribe appropriate physical therapy. However, it can be difficult to monitor patients' movements remotely outside the clinic. High-fidelity data from motion capture sensors can be used to classify different movements, but these sensors are costly and impractical for use in free-living environments. Motion Tape (MT), a new fabric-based wearable sensor, addresses these issues by being low cost and portable. Despite these advantages, novelty and variability in sensor stability make the MT dataset small scale and inherent to noise. In this work, we propose the Motion-Tape Augmentation Inference Model (MT-AIM), a deep learning classification pipeline trained on MT data. In order to address the challenges of limited sample size and noise present within the MT dataset, MT-AIM leverages conditional generative models to generate synthetic MT data of a desired movement, as well as predicting joint kinematics as additional features. This combination of synthetic data generation and feature augmentation enables MT-AIM to achieve state-of-the-art accuracy in classifying lower back movements, bridging the gap between physiological sensing and movement analysis.
Medical Question Understanding and Answering with Knowledge Grounding and Semantic Self-Supervision
Sep 30, 2022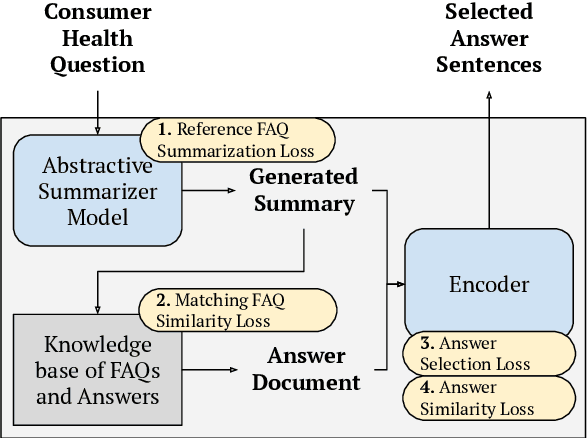
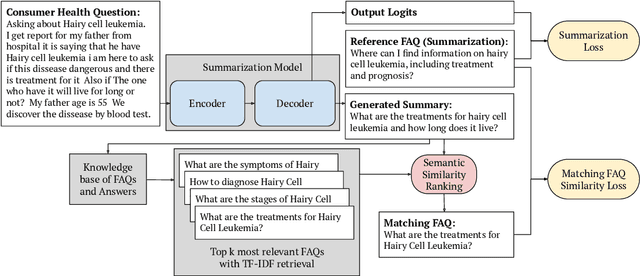

Current medical question answering systems have difficulty processing long, detailed and informally worded questions submitted by patients, called Consumer Health Questions (CHQs). To address this issue, we introduce a medical question understanding and answering system with knowledge grounding and semantic self-supervision. Our system is a pipeline that first summarizes a long, medical, user-written question, using a supervised summarization loss. Then, our system performs a two-step retrieval to return answers. The system first matches the summarized user question with an FAQ from a trusted medical knowledge base, and then retrieves a fixed number of relevant sentences from the corresponding answer document. In the absence of labels for question matching or answer relevance, we design 3 novel, self-supervised and semantically-guided losses. We evaluate our model against two strong retrieval-based question answering baselines. Evaluators ask their own questions and rate the answers retrieved by our baselines and own system according to their relevance. They find that our system retrieves more relevant answers, while achieving speeds 20 times faster. Our self-supervised losses also help the summarizer achieve higher scores in ROUGE, as well as in human evaluation metrics. We release our code to encourage further research.