 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Free Stylized Abstraction
May 28, 2025Stylized abstraction synthesizes visually exaggerated yet semantically faithful representations of subjects, balancing recognizability with perceptual distortion. Unlike image-to-image translation, which prioritizes structural fidelity, stylized abstraction demands selective retention of identity cues while embracing stylistic divergence, especially challenging for out-of-distribution individuals. We propose a training-free framework that generates stylized abstractions from a single image using inference-time scaling in vision-language models (VLLMs) to extract identity-relevant features, and a novel cross-domain rectified flow inversion strategy that reconstructs structure based on style-dependent priors. Our method adapts structural restoration dynamically through style-aware temporal scheduling, enabling high-fidelity reconstructions that honor both subject and style. It supports multi-round abstraction-aware generation without fine-tuning. To evaluate this task, we introduce StyleBench, a GPT-based human-aligned metric suited for abstract styles where pixel-level similarity fails. Experiments across diverse abstraction (e.g., LEGO, knitted dolls, South Park) show strong generalization to unseen identities and styles in a fully open-source setup.
Reference-Guided Identity Preserving Face Restoration
May 28, 2025Preserving face identity is a critical yet persistent challenge in diffusion-based image restoration. While reference faces offer a path forward, existing reference-based methods often fail to fully exploit their potential. This paper introduces a novel approach that maximizes reference face utility for improved face restoration and identity preservation. Our method makes three key contributions: 1) Composite Context, a comprehensive representation that fuses multi-level (high- and low-level) information from the reference face, offering richer guidance than prior singular representations. 2) Hard Example Identity Loss, a novel loss function that leverages the reference face to address the identity learning inefficiencies found in the existing identity loss. 3) A training-free method to adapt the model to multi-reference inputs during inference. The proposed method demonstrably restores high-quality faces and achieves state-of-the-art identity preserving restoration on benchmarks such as FFHQ-Ref and CelebA-Ref-Test, consistently outperforming previous work.
Think Before You Diffuse: LLMs-Guided Physics-Aware Video Generation
May 27, 2025Recent video diffusion models have demonstrated their great capability in generating visually-pleasing results, while synthesizing the correct physical effects in generated videos remains challenging. The complexity of real-world motions, interactions, and dynamics introduce great difficulties when learning physics from data. In this work, we propose DiffPhy, a generic framework that enables physically-correct and photo-realistic video generation by fine-tuning a pre-trained video diffusion model. Our method leverages large language models (LLMs) to explicitly reason a comprehensive physical context from the text prompt and use it to guide the generation. To incorporate physical context into the diffusion model, we leverage a Multimodal large language model (MLLM) as a supervisory signal and introduce a set of novel training objectives that jointly enforce physical correctness and semantic consistency with the input text. We also establish a high-quality physical video dataset containing diverse phyiscal actions and events to facilitate effective finetuning. Extensive experiments on public benchmarks demonstrate that DiffPhy is able to produce state-of-the-art results across diverse physics-related scenarios. Our project page is available at https://bwgzk-keke.github.io/DiffPhy/
Certainty and Uncertainty Guided Active Domain Adaptation
May 26, 2025



Active Domain Adaptation (ADA) adapts models to target domains by selectively labeling a few target samples. Existing ADA methods prioritize uncertain samples but overlook confident ones, which often match ground-truth. We find that incorporating confident predictions into the labeled set before active sampling reduces the search space and improves adaptation. To address this, we propose a collaborative framework that labels uncertain samples while treating highly confident predictions as ground truth. Our method combines Gaussian Process-based Active Sampling (GPAS) for identifying uncertain samples and Pseudo-Label-based Certain Sampling (PLCS) for confident ones, progressively enhancing adaptation. PLCS refines the search space, and GPAS reduces the domain gap, boosting the proportion of confident samples. Extensive experiments on Office-Home and DomainNet show that our approach outperforms state-of-the-art ADA methods.
RestoreVAR: Visual Autoregressive Generation for All-in-One Image Restoration
May 23, 2025



The use of latent diffusion models (LDMs) such as Stable Diffusion has significantly improved the perceptual quality of All-in-One image Restoration (AiOR) methods, while also enhancing their generalization capabilities. However, these LDM-based frameworks suffer from slow inference due to their iterative denoising process, rendering them impractical for time-sensitive applications. To address this, we propose RestoreVAR, a novel generative approach for AiOR that significantly outperforms LDM-based models in restoration performance while achieving over $\mathbf{10\times}$ faster inference. RestoreVAR leverages visual autoregressive modeling (VAR), a recently introduced approach which performs scale-space autoregression for image generation. VAR achieves comparable performance to that of state-of-the-art diffusion transformers with drastically reduced computational costs. To optimally exploit these advantages of VAR for AiOR, we propose architectural modifications and improvements, including intricately designed cross-attention mechanisms and a latent-space refinement module, tailored for the AiOR task. Extensive experiments show that RestoreVAR achieves state-of-the-art performance among generative AiOR methods, while also exhibiting strong generalization capabilities.
HarmonySeg: Tubular Structure Segmentation with Deep-Shallow Feature Fusion and Growth-Suppression Balanced Loss
Apr 10, 2025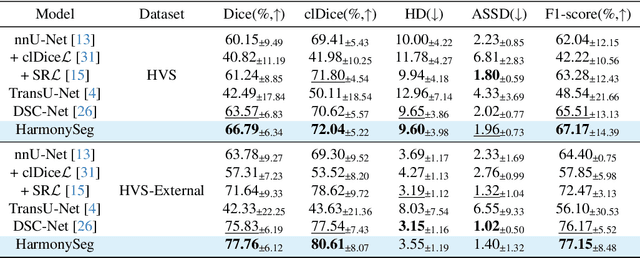
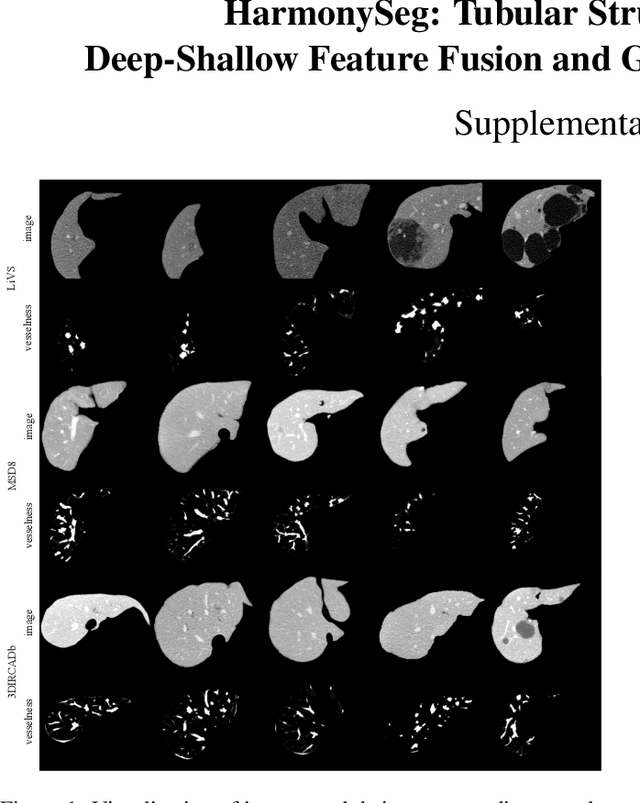

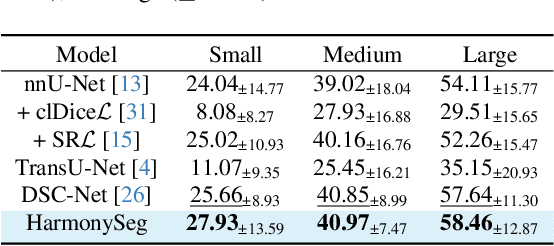
Accurate segmentation of tubular structures in medical images, such as vessels and airway trees, is crucial for computer-aided diagnosis, radiotherapy, and surgical planning. However, significant challenges exist in algorithm design when faced with diverse sizes, complex topologies, and (often) incomplete data annotation of these structures. We address these difficulties by proposing a new tubular structure segmentation framework named HarmonySeg. First, we design a deep-to-shallow decoder network featuring flexible convolution blocks with varying receptive fields, which enables the model to effectively adapt to tubular structures of different scales. Second, to highlight potential anatomical regions and improve the recall of small tubular structures, we incorporate vesselness maps as auxiliary information. These maps are aligned with image features through a shallow-and-deep fusion module, which simultaneously eliminates unreasonable candidates to maintain high precision. Finally, we introduce a topology-preserving loss function that leverages contextual and shape priors to balance the growth and suppression of tubular structures, which also allows the model to handle low-quality and incomplete annotations. Extensive quantitative experiments are conducted on four public datasets. The results show that our model can accurately segment 2D and 3D tubular structures and outperform existing state-of-the-art methods. External validation on a private dataset also demonstrates good generalizability.
Perception in Reflection
Apr 09, 2025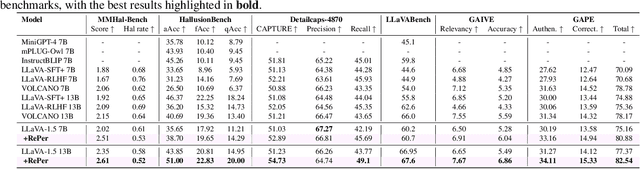


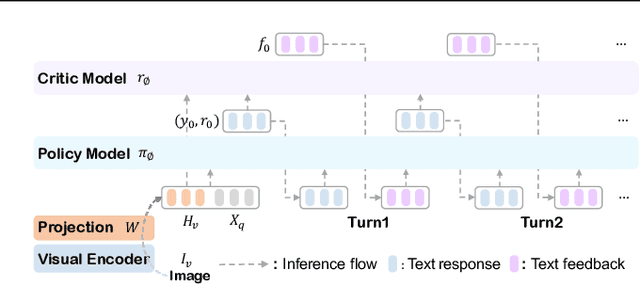
We present a perception in reflection paradigm designed to transcend the limitations of current large vision-language models (LVLMs), which are expected yet often fail to achieve perfect perception initially. Specifically, we propose Reflective Perception (RePer), a dual-model reflection mechanism that systematically alternates between policy and critic models, enables iterative refinement of visual perception. This framework is powered by Reflective Perceptual Learning (RPL), which reinforces intrinsic reflective capabilities through a methodically constructed visual reflection dataset and reflective unlikelihood training. Comprehensive experimental evaluation demonstrates RePer's quantifiable improvements in image understanding, captioning precision, and hallucination reduction. Notably, RePer achieves strong alignment between model attention patterns and human visual focus, while RPL optimizes fine-grained and free-form preference alignment. These advancements establish perception in reflection as a robust paradigm for future multimodal agents, particularly in tasks requiring complex reasoning and multi-step manipulation.
F-ViTA: Foundation Model Guided Visible to Thermal Translation
Apr 03, 2025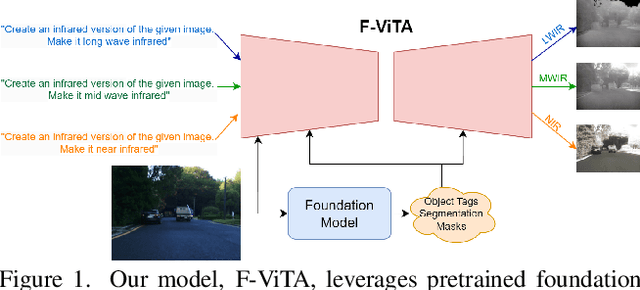
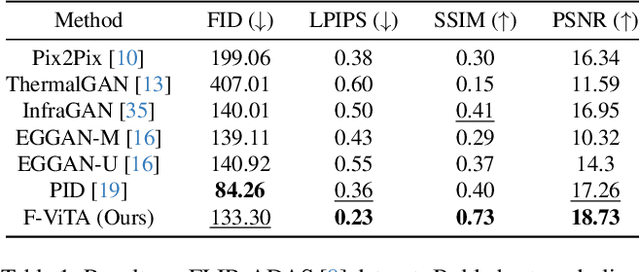
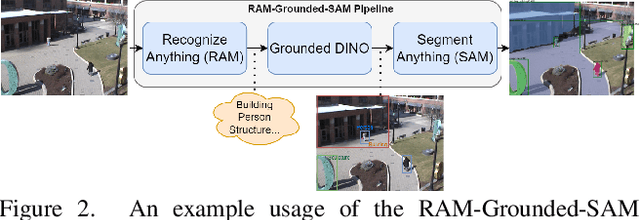
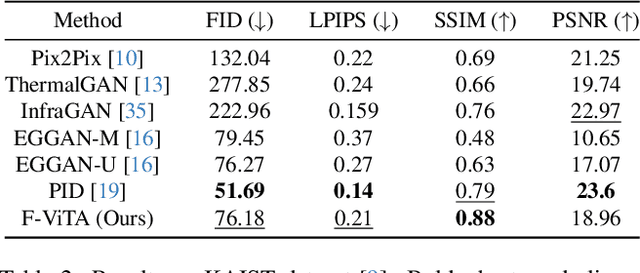
Thermal imaging is crucial for scene understanding, particularly in low-light and nighttime conditions. However, collecting large thermal datasets is costly and labor-intensive due to the specialized equipment required for infrared image capture. To address this challenge, researchers have explored visible-to-thermal image translation. Most existing methods rely on Generative Adversarial Networks (GANs) or Diffusion Models (DMs), treating the task as a style transfer problem. As a result, these approaches attempt to learn both the modality distribution shift and underlying physical principles from limited training data. In this paper, we propose F-ViTA, a novel approach that leverages the general world knowledge embedded in foundation models to guide the diffusion process for improved translation. Specifically, we condition an InstructPix2Pix Diffusion Model with zero-shot masks and labels from foundation models such as SAM and Grounded DINO. This allows the model to learn meaningful correlations between scene objects and their thermal signatures in infrared imagery. Extensive experiments on five public datasets demonstrate that F-ViTA outperforms state-of-the-art (SOTA) methods. Furthermore, our model generalizes well to out-of-distribution (OOD) scenarios and can generate Long-Wave Infrared (LWIR), Mid-Wave Infrared (MWIR), and Near-Infrared (NIR) translations from the same visible image. Code: https://github.com/JayParanjape/F-ViTA/tree/master.
MedCL: Learning Consistent Anatomy Distribution for Scribble-supervised Medical Image Segmentation
Mar 28, 2025



Curating large-scale fully annotated datasets is expensive, laborious, and cumbersome, especially for medical images. Several methods have been proposed in the literature that make use of weak annotations in the form of scribbles. However, these approaches require large amounts of scribble annotations, and are only applied to the segmentation of regular organs, which are often unavailable for the disease species that fall in the long-tailed distribution. Motivated by the fact that the medical labels have anatomy distribution priors, we propose a scribble-supervised clustering-based framework, called MedCL, to learn the inherent anatomy distribution of medical labels. Our approach consists of two steps: i) Mix the features with intra- and inter-image mix operations, and ii) Perform feature clustering and regularize the anatomy distribution at both local and global levels. Combined with a small amount of weak supervision, the proposed MedCL is able to segment both regular organs and challenging irregular pathologies. We implement MedCL based on SAM and UNet backbones, and evaluate the performance on three open datasets of regular structure (MSCMRseg), multiple organs (BTCV) and irregular pathology (MyoPS). It is shown that even with less scribble supervision, MedCL substantially outperforms the conventional segmentation methods. Our code is available at https://github.com/BWGZK/MedCL.
SINR: Sparsity Driven Compressed Implicit Neural Representations
Mar 25, 2025



Implicit Neural Representations (INRs) are increasingly recognized as a versatile data modality for representing discretized signals, offering benefits such as infinite query resolution and reduced storage requirements. Existing signal compression approaches for INRs typically employ one of two strategies: 1. direct quantization with entropy coding of the trained INR; 2. deriving a latent code on top of the INR through a learnable transformation. Thus, their performance is heavily dependent on the quantization and entropy coding schemes employed. In this paper, we introduce SINR, an innovative compression algorithm that leverages the patterns in the vector spaces formed by weights of INRs. We compress these vector spaces using a high-dimensional sparse code within a dictionary. Further analysis reveals that the atoms of the dictionary used to generate the sparse code do not need to be learned or transmitted to successfully recover the INR weights. We demonstrate that the proposed approach can be integrated with any existing INR-based signal compression technique. Our results indicate that SINR achieves substantial reductions in storage requirements for INRs across various configurations, outperforming conventional INR-based compression baselines. Furthermore, SINR maintains high-quality decoding across diverse data modalities, including images, occupancy fields, and Neural Radiance Fields.