 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniRes: Universal Image Restoration for Complex Degradations
Jun 05, 2025Real-world image restoration is hampered by diverse degradations stemming from varying capture conditions, capture devices and post-processing pipelines. Existing works make improvements through simulating those degradations and leveraging image generative priors, however generalization to in-the-wild data remains an unresolved problem. In this paper, we focus on complex degradations, i.e., arbitrary mixtures of multiple types of known degradations, which is frequently seen in the wild. A simple yet flexible diffusionbased framework, named UniRes, is proposed to address such degradations in an end-to-end manner. It combines several specialized models during the diffusion sampling steps, hence transferring the knowledge from several well-isolated restoration tasks to the restoration of complex in-the-wild degradations. This only requires well-isolated training data for several degradation types. The framework is flexible as extensions can be added through a unified formulation, and the fidelity-quality trade-off can be adjusted through a new paradigm. Our proposed method is evaluated on both complex-degradation and single-degradation image restoration datasets. Extensive qualitative and quantitative experimental results show consistent performance gain especially for images with complex degradations.
TextSR: Diffusion Super-Resolution with Multilingual OCR Guidance
May 29, 2025While recent advancements in Image Super-Resolution (SR) using diffusion models have shown promise in improving overall image quality, their application to scene text images has revealed limitations. These models often struggle with accurate text region localization and fail to effectively model image and multilingual character-to-shape priors. This leads to inconsistencies, the generation of hallucinated textures, and a decrease in the perceived quality of the super-resolved text. To address these issues, we introduce TextSR, a multimodal diffusion model specifically designed for Multilingual Scene Text Image Super-Resolution. TextSR leverages a text detector to pinpoint text regions within an image and then employs Optical Character Recognition (OCR) to extract multilingual text from these areas. The extracted text characters are then transformed into visual shapes using a UTF-8 based text encoder and cross-attention. Recognizing that OCR may sometimes produce inaccurate results in real-world scenarios, we have developed two innovative methods to enhance the robustness of our model. By integrating text character priors with the low-resolution text images, our model effectively guides the super-resolution process, enhancing fine details within the text and improving overall legibility. The superior performance of our model on both the TextZoom and TextVQA datasets sets a new benchmark for STISR, underscoring the efficacy of our approach.
Reference-Guided Identity Preserving Face Restoration
May 28, 2025Preserving face identity is a critical yet persistent challenge in diffusion-based image restoration. While reference faces offer a path forward, existing reference-based methods often fail to fully exploit their potential. This paper introduces a novel approach that maximizes reference face utility for improved face restoration and identity preservation. Our method makes three key contributions: 1) Composite Context, a comprehensive representation that fuses multi-level (high- and low-level) information from the reference face, offering richer guidance than prior singular representations. 2) Hard Example Identity Loss, a novel loss function that leverages the reference face to address the identity learning inefficiencies found in the existing identity loss. 3) A training-free method to adapt the model to multi-reference inputs during inference. The proposed method demonstrably restores high-quality faces and achieves state-of-the-art identity preserving restoration on benchmarks such as FFHQ-Ref and CelebA-Ref-Test, consistently outperforming previous work.
The Power of Context: How Multimodality Improves Image Super-Resolution
Mar 18, 2025



Single-image super-resolution (SISR) remains challenging due to the inherent difficulty of recovering fine-grained details and preserving perceptual quality from low-resolution inputs. Existing methods often rely on limited image priors, leading to suboptimal results. We propose a novel approach that leverages the rich contextual information available in multiple modalities -- including depth, segmentation, edges, and text prompts -- to learn a powerful generative prior for SISR within a diffusion model framework. We introduce a flexible network architecture that effectively fuses multimodal information, accommodating an arbitrary number of input modalities without requiring significant modifications to the diffusion process. Crucially, we mitigate hallucinations, often introduced by text prompts, by using spatial information from other modalities to guide regional text-based conditioning. Each modality's guidance strength can also be controlled independently, allowing steering outputs toward different directions, such as increasing bokeh through depth or adjusting object prominence via segmentation. Extensive experiments demonstrate that our model surpasses state-of-the-art generative SISR methods, achieving superior visual quality and fidelity. See project page at https://mmsr.kfmei.com/.
Bigger is not Always Better: Scaling Properties of Latent Diffusion Models
Apr 01, 2024We study the scaling properties of latent diffusion models (LDMs) with an emphasis on their sampling efficiency. While improved network architecture and inference algorithms have shown to effectively boost sampling efficiency of diffusion models, the role of model size -- a critical determinant of sampling efficiency -- has not been thoroughly examined. Through empirical analysis of established text-to-image diffusion models, we conduct an in-depth investigation into how model size influences sampling efficiency across varying sampling steps. Our findings unveil a surprising trend: when operating under a given inference budget, smaller models frequently outperform their larger equivalents in generating high-quality results. Moreover, we extend our study to demonstrate the generalizability of the these findings by applying various diffusion samplers, exploring diverse downstream tasks, evaluating post-distilled models, as well as comparing performance relative to training compute. These findings open up new pathways for the development of LDM scaling strategies which can be employed to enhance generative capabilities within limited inference budgets.
TIP: Text-Driven Image Processing with Semantic and Restoration Instructions
Dec 18, 2023Text-driven diffusion models have become increasingly popular for various image editing tasks, including inpainting, stylization, and object replacement. However, it still remains an open research problem to adopt this language-vision paradigm for more fine-level image processing tasks, such as denoising, super-resolution, deblurring, and compression artifact removal. In this paper, we develop TIP, a Text-driven Image Processing framework that leverages natural language as a user-friendly interface to control the image restoration process. We consider the capacity of text information in two dimensions. First, we use content-related prompts to enhance the semantic alignment, effectively alleviating identity ambiguity in the restoration outcomes. Second, our approach is the first framework that supports fine-level instruction through language-based quantitative specification of the restoration strength, without the need for explicit task-specific design. In addition, we introduce a novel fusion mechanism that augments the existing ControlNet architecture by learning to rescale the generative prior, thereby achieving better restoration fidelity. Our extensive experiments demonstrate the superior restoration performance of TIP compared to the state of the arts, alongside offering the flexibility of text-based control over the restoration effects.
Conditional Diffusion Distillation
Oct 02, 2023



Generative diffusion models provide strong priors for text-to-image generation and thereby serve as a foundation for conditional generation tasks such as image editing, restoration, and super-resolution. However, one major limitation of diffusion models is their slow sampling time. To address this challenge, we present a novel conditional distillation method designed to supplement the diffusion priors with the help of image conditions, allowing for conditional sampling with very few steps. We directly distill the unconditional pre-training in a single stage through joint-learning, largely simplifying the previous two-stage procedures that involve both distillation and conditional finetuning separately. Furthermore, our method enables a new parameter-efficient distillation mechanism that distills each task with only a small number of additional parameters combined with the shared frozen unconditional backbone. Experiments across multiple tasks including super-resolution, image editing, and depth-to-image generation demonstrate that our method outperforms existing distillation techniques for the same sampling time. Notably, our method is the first distillation strategy that can match the performance of the much slower fine-tuned conditional diffusion models.
MULLER: Multilayer Laplacian Resizer for Vision
Apr 06, 2023



Image resizing operation is a fundamental preprocessing module in modern computer vision. Throughout the deep learning revolution, researchers have overlooked the potential of alternative resizing methods beyond the commonly used resizers that are readily available, such as nearest-neighbors, bilinear, and bicubic. The key question of our interest is whether the front-end resizer affects the performance of deep vision models? In this paper, we present an extremely lightweight multilayer Laplacian resizer with only a handful of trainable parameters, dubbed MULLER resizer. MULLER has a bandpass nature in that it learns to boost details in certain frequency subbands that benefit the downstream recognition models. We show that MULLER can be easily plugged into various training pipelines, and it effectively boosts the performance of the underlying vision task with little to no extra cost. Specifically, we select a state-of-the-art vision Transformer, MaxViT, as the baseline, and show that, if trained with MULLER, MaxViT gains up to 0.6% top-1 accuracy, and meanwhile enjoys 36% inference cost saving to achieve similar top-1 accuracy on ImageNet-1k, as compared to the standard training scheme. Notably, MULLER's performance also scales with model size and training data size such as ImageNet-21k and JFT, and it is widely applicable to multiple vision tasks, including image classification, object detection and segmentation, as well as image quality assessment.
Image Deblurring with Domain Generalizable Diffusion Models
Dec 04, 2022



Diffusion Probabilistic Models (DPMs) have recently been employed for image deblurring. DPMs are trained via a stochastic denoising process that maps Gaussian noise to the high-quality image, conditioned on the concatenated blurry input. Despite their high-quality generated samples, image-conditioned Diffusion Probabilistic Models (icDPM) rely on synthetic pairwise training data (in-domain), with potentially unclear robustness towards real-world unseen images (out-of-domain). In this work, we investigate the generalization ability of icDPMs in deblurring, and propose a simple but effective guidance to significantly alleviate artifacts, and improve the out-of-distribution performance. Particularly, we propose to first extract a multiscale domain-generalizable representation from the input image that removes domain-specific information while preserving the underlying image structure. The representation is then added into the feature maps of the conditional diffusion model as an extra guidance that helps improving the generalization. To benchmark, we focus on out-of-distribution performance by applying a single-dataset trained model to three external and diverse test sets. The effectiveness of the proposed formulation is demonstrated by improvements over the standard icDPM, as well as state-of-the-art performance on perceptual quality and competitive distortion metrics compared to existing methods.
Soft Diffusion: Score Matching for General Corruptions
Sep 12, 2022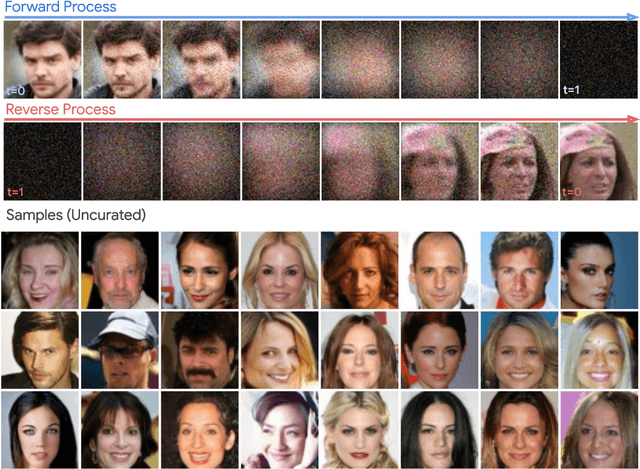

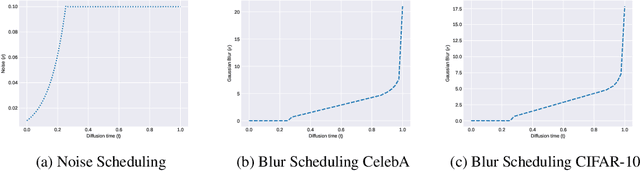

We define a broader family of corruption processes that generalizes previously known diffusion models. To reverse these general diffusions, we propose a new objective called Soft Score Matching that provably learns the score function for any linear corruption process and yields state of the art results for CelebA. Soft Score Matching incorporates the degradation process in the network and trains the model to predict a clean image that after corruption matches the diffused observation. We show that our objective learns the gradient of the likelihood under suitable regularity conditions for the family of corruption processes. We further develop a principled way to select the corruption levels for general diffusion processes and a novel sampling method that we call Momentum Sampler. We evaluate our framework with the corruption being Gaussian Blur and low magnitude additive noise. Our method achieves state-of-the-art FID score $1.85$ on CelebA-64, outperforming all previous linear diffusion models. We also show significant computational benefits compared to vanilla denoising diffusion.