 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Neural Representations: A Signal Processing Perspective
Apr 16, 2026Implicit neural representations (INRs) mark a fundamental shift in signal modeling, moving from discrete sampled data to continuous functional representations. By parameterizing signals as neural networks, INRs provide a unified framework for representing images, audio, video, 3D geometry, and beyond as continuous functions of their coordinates. This functional viewpoint enables signal operations such as differentiation to be carried out analytically through automatic differentiation rather than through discrete approximations. In this article, we examine the evolution of INRs from a signal processing perspective, emphasizing spectral behavior, sampling theory, and multiscale representation. We trace the progression from standard coordinate based networks, which exhibit a spectral bias toward low frequency components, to more advanced designs that reshape the approximation space through specialized activations, including periodic, localized, and adaptive functions. We also discuss structured representations, such as hierarchical decompositions and hash grid encodings, that improve spatial adaptivity and computational efficiency. We further highlight the utility of INRs across a broad range of applications, including inverse problems in medical and radar imaging, compression, and 3D scene representation. By interpreting INRs as learned signal models whose approximation spaces adapt to the underlying data, this article clarifies the field's core conceptual developments and outlines open challenges in theoretical stability, weight space interpretability, and large scale generalization.
SINR: Sparsity Driven Compressed Implicit Neural Representations
Mar 25, 2025



Implicit Neural Representations (INRs) are increasingly recognized as a versatile data modality for representing discretized signals, offering benefits such as infinite query resolution and reduced storage requirements. Existing signal compression approaches for INRs typically employ one of two strategies: 1. direct quantization with entropy coding of the trained INR; 2. deriving a latent code on top of the INR through a learnable transformation. Thus, their performance is heavily dependent on the quantization and entropy coding schemes employed. In this paper, we introduce SINR, an innovative compression algorithm that leverages the patterns in the vector spaces formed by weights of INRs. We compress these vector spaces using a high-dimensional sparse code within a dictionary. Further analysis reveals that the atoms of the dictionary used to generate the sparse code do not need to be learned or transmitted to successfully recover the INR weights. We demonstrate that the proposed approach can be integrated with any existing INR-based signal compression technique. Our results indicate that SINR achieves substantial reductions in storage requirements for INRs across various configurations, outperforming conventional INR-based compression baselines. Furthermore, SINR maintains high-quality decoding across diverse data modalities, including images, occupancy fields, and Neural Radiance Fields.
GAUSS: Guided Encoder-Decoder Architecture for Hyperspectral Unmixing with Spatial Smoothness
Apr 16, 2022
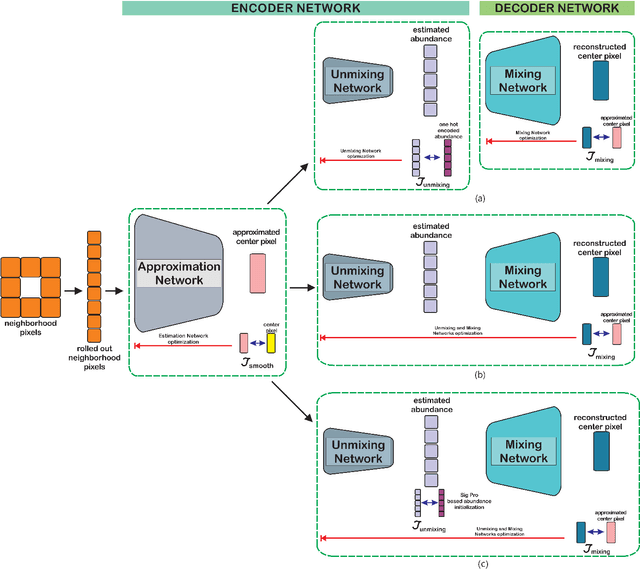

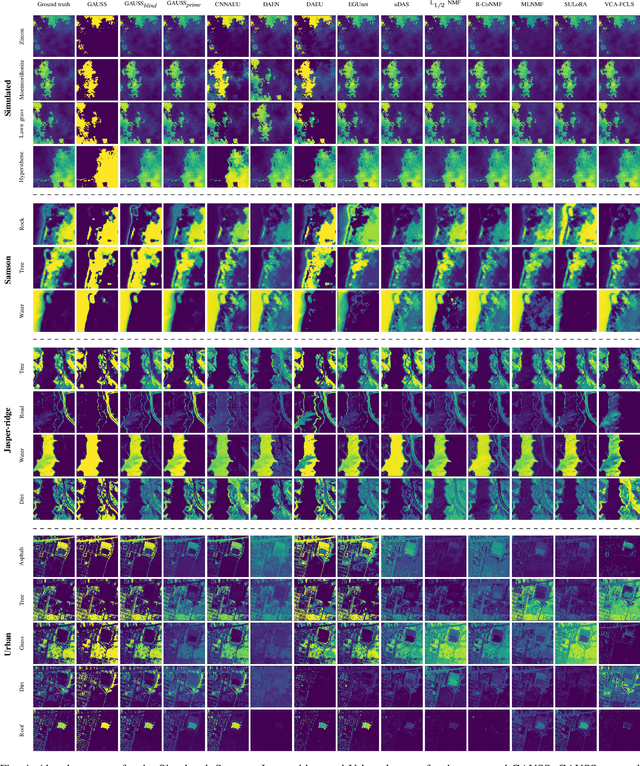
In recent hyperspectral unmixing (HU) literature, the application of deep learning (DL) has become more prominent, especially with the autoencoder (AE) architecture. We propose a split architecture and use a pseudo-ground truth for abundances to guide the `unmixing network' (UN) optimization. Preceding the UN, an `approximation network' (AN) is proposed, which will improve the association between the centre pixel and its neighbourhood. Hence, it will accentuate spatial correlation in the abundances as its output is the input to the UN and the reference for the `mixing network' (MN). In the Guided Encoder-Decoder Architecture for Hyperspectral Unmixing with Spatial Smoothness (GAUSS), we proposed using one-hot encoded abundances as the pseudo-ground truth to guide the UN; computed using the k-means algorithm to exclude the use of prior HU methods. Furthermore, we release the single-layer constraint on MN by introducing the UN generated abundances in contrast to the standard AE for HU. Secondly, we experimented with two modifications on the pre-trained network using the GAUSS method. In GAUSS$_\textit{blind}$, we have concatenated the UN and the MN to back-propagate the reconstruction error gradients to the encoder. Then, in the GAUSS$_\textit{prime}$, abundance results of a signal processing (SP) method with reliable abundance results were used as the pseudo-ground truth with the GAUSS architecture. According to quantitative and graphical results for four experimental datasets, the three architectures either transcended or equated the performance of existing HU algorithms from both DL and SP domains.