 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferring Change Detection in Remote Sensing Imagery
Dec 12, 2025Change detection in remote sensing imagery is essential for applications such as urban planning, environmental monitoring, and disaster management. Traditional change detection methods typically identify all changes between two temporal images without distinguishing the types of transitions, which can lead to results that may not align with specific user needs. Although semantic change detection methods have attempted to address this by categorizing changes into predefined classes, these methods rely on rigid class definitions and fixed model architectures, making it difficult to mix datasets with different label sets or reuse models across tasks, as the output channels are tightly coupled with the number and type of semantic classes. To overcome these limitations, we introduce Referring Change Detection (RCD), which leverages natural language prompts to detect specific classes of changes in remote sensing images. By integrating language understanding with visual analysis, our approach allows users to specify the exact type of change they are interested in. However, training models for RCD is challenging due to the limited availability of annotated data and severe class imbalance in existing datasets. To address this, we propose a two-stage framework consisting of (I) \textbf{RCDNet}, a cross-modal fusion network designed for referring change detection, and (II) \textbf{RCDGen}, a diffusion-based synthetic data generation pipeline that produces realistic post-change images and change maps for a specified category using only pre-change image, without relying on semantic segmentation masks and thereby significantly lowering the barrier to scalable data creation. Experiments across multiple datasets show that our framework enables scalable and targeted change detection. Project website is here: https://yilmazkorkmaz1.github.io/RCD.
F-ViTA: Foundation Model Guided Visible to Thermal Translation
Apr 03, 2025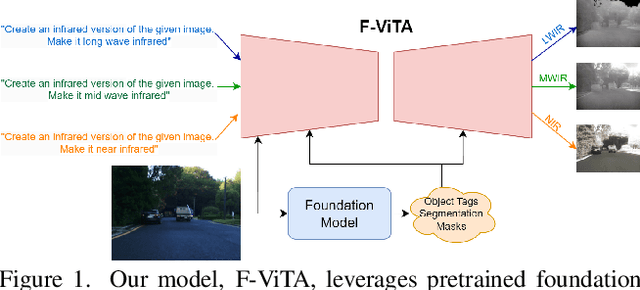
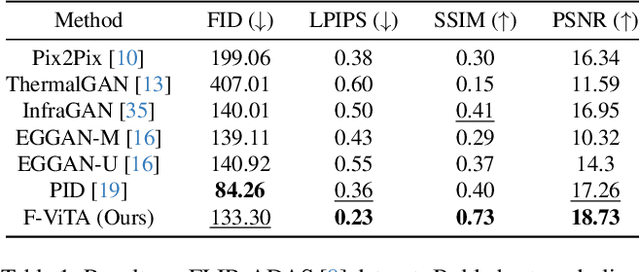
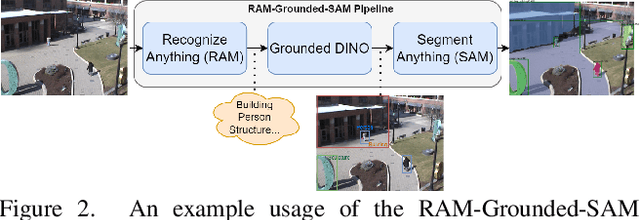
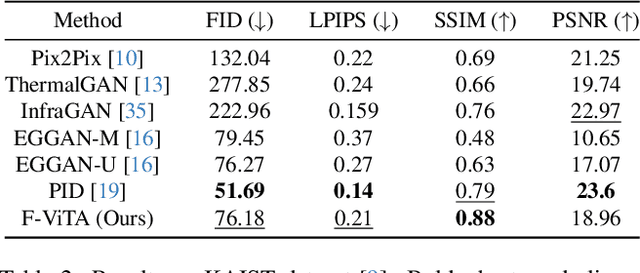
Thermal imaging is crucial for scene understanding, particularly in low-light and nighttime conditions. However, collecting large thermal datasets is costly and labor-intensive due to the specialized equipment required for infrared image capture. To address this challenge, researchers have explored visible-to-thermal image translation. Most existing methods rely on Generative Adversarial Networks (GANs) or Diffusion Models (DMs), treating the task as a style transfer problem. As a result, these approaches attempt to learn both the modality distribution shift and underlying physical principles from limited training data. In this paper, we propose F-ViTA, a novel approach that leverages the general world knowledge embedded in foundation models to guide the diffusion process for improved translation. Specifically, we condition an InstructPix2Pix Diffusion Model with zero-shot masks and labels from foundation models such as SAM and Grounded DINO. This allows the model to learn meaningful correlations between scene objects and their thermal signatures in infrared imagery. Extensive experiments on five public datasets demonstrate that F-ViTA outperforms state-of-the-art (SOTA) methods. Furthermore, our model generalizes well to out-of-distribution (OOD) scenarios and can generate Long-Wave Infrared (LWIR), Mid-Wave Infrared (MWIR), and Near-Infrared (NIR) translations from the same visible image. Code: https://github.com/JayParanjape/F-ViTA/tree/master.
GenDeg: Diffusion-Based Degradation Synthesis for Generalizable All-in-One Image Restoration
Nov 26, 2024



Deep learning-based models for All-In-One Image Restoration (AIOR) have achieved significant advancements in recent years. However, their practical applicability is limited by poor generalization to samples outside the training distribution. This limitation arises primarily from insufficient diversity in degradation variations and scenes within existing datasets, resulting in inadequate representations of real-world scenarios. Additionally, capturing large-scale real-world paired data for degradations such as haze, low-light, and raindrops is often cumbersome and sometimes infeasible. In this paper, we leverage the generative capabilities of latent diffusion models to synthesize high-quality degraded images from their clean counterparts. Specifically, we introduce GenDeg, a degradation and intensity-aware conditional diffusion model capable of producing diverse degradation patterns on clean images. Using GenDeg, we synthesize over 550k samples across six degradation types: haze, rain, snow, motion blur, low-light, and raindrops. These generated samples are integrated with existing datasets to form the GenDS dataset, comprising over 750k samples. Our experiments reveal that image restoration models trained on the GenDS dataset exhibit significant improvements in out-of-distribution performance compared to those trained solely on existing datasets. Furthermore, we provide comprehensive analyses on the implications of diffusion model-based synthetic degradations for AIOR. The code will be made publicly available.
Federated Black-Box Adaptation for Semantic Segmentation
Oct 31, 2024



Federated Learning (FL) is a form of distributed learning that allows multiple institutions or clients to collaboratively learn a global model to solve a task. This allows the model to utilize the information from every institute while preserving data privacy. However, recent studies show that the promise of protecting the privacy of data is not upheld by existing methods and that it is possible to recreate the training data from the different institutions. This is done by utilizing gradients transferred between the clients and the global server during training or by knowing the model architecture at the client end. In this paper, we propose a federated learning framework for semantic segmentation without knowing the model architecture nor transferring gradients between the client and the server, thus enabling better privacy preservation. We propose BlackFed - a black-box adaptation of neural networks that utilizes zero order optimization (ZOO) to update the client model weights and first order optimization (FOO) to update the server weights. We evaluate our approach on several computer vision and medical imaging datasets to demonstrate its effectiveness. To the best of our knowledge, this work is one of the first works in employing federated learning for segmentation, devoid of gradients or model information exchange. Code: https://github.com/JayParanjape/blackfed/tree/master
S-SAM: SVD-based Fine-Tuning of Segment Anything Model for Medical Image Segmentation
Aug 12, 2024Medical image segmentation has been traditionally approached by training or fine-tuning the entire model to cater to any new modality or dataset. However, this approach often requires tuning a large number of parameters during training. With the introduction of the Segment Anything Model (SAM) for prompted segmentation of natural images, many efforts have been made towards adapting it efficiently for medical imaging, thus reducing the training time and resources. However, these methods still require expert annotations for every image in the form of point prompts or bounding box prompts during training and inference, making it tedious to employ them in practice. In this paper, we propose an adaptation technique, called S-SAM, that only trains parameters equal to 0.4% of SAM's parameters and at the same time uses simply the label names as prompts for producing precise masks. This not only makes tuning SAM more efficient than the existing adaptation methods but also removes the burden of providing expert prompts. We call this modified version S-SAM and evaluate it on five different modalities including endoscopic images, x-ray, ultrasound, CT, and histology images. Our experiments show that S-SAM outperforms state-of-the-art methods as well as existing SAM adaptation methods while tuning a significantly less number of parameters. We release the code for S-SAM at https://github.com/JayParanjape/SVDSAM.
A Mamba-based Siamese Network for Remote Sensing Change Detection
Jul 08, 2024



Change detection in remote sensing images is an essential tool for analyzing a region at different times. It finds varied applications in monitoring environmental changes, man-made changes as well as corresponding decision-making and prediction of future trends. Deep learning methods like Convolutional Neural Networks (CNNs) and Transformers have achieved remarkable success in detecting significant changes, given two images at different times. In this paper, we propose a Mamba-based Change Detector (M-CD) that segments out the regions of interest even better. Mamba-based architectures demonstrate linear-time training capabilities and an improved receptive field over transformers. Our experiments on four widely used change detection datasets demonstrate significant improvements over existing state-of-the-art (SOTA) methods. Our code and pre-trained models are available at https://github.com/JayParanjape/M-CD
Blackbox Adaptation for Medical Image Segmentation
May 17, 2024In recent years, various large foundation models have been proposed for image segmentation. There models are often trained on large amounts of data corresponding to general computer vision tasks. Hence, these models do not perform well on medical data. There have been some attempts in the literature to perform parameter-efficient finetuning of such foundation models for medical image segmentation. However, these approaches assume that all the parameters of the model are available for adaptation. But, in many cases, these models are released as APIs or blackboxes, with no or limited access to the model parameters and data. In addition, finetuning methods also require a significant amount of compute, which may not be available for the downstream task. At the same time, medical data can't be shared with third-party agents for finetuning due to privacy reasons. To tackle these challenges, we pioneer a blackbox adaptation technique for prompted medical image segmentation, called BAPS. BAPS has two components - (i) An Image-Prompt decoder (IP decoder) module that generates visual prompts given an image and a prompt, and (ii) A Zero Order Optimization (ZOO) Method, called SPSA-GC that is used to update the IP decoder without the need for backpropagating through the foundation model. Thus, our method does not require any knowledge about the foundation model's weights or gradients. We test BAPS on four different modalities and show that our method can improve the original model's performance by around 4%.
AdaptiveSAM: Towards Efficient Tuning of SAM for Surgical Scene Segmentation
Aug 07, 2023Segmentation is a fundamental problem in surgical scene analysis using artificial intelligence. However, the inherent data scarcity in this domain makes it challenging to adapt traditional segmentation techniques for this task. To tackle this issue, current research employs pretrained models and finetunes them on the given data. Even so, these require training deep networks with millions of parameters every time new data becomes available. A recently published foundation model, Segment-Anything (SAM), generalizes well to a large variety of natural images, hence tackling this challenge to a reasonable extent. However, SAM does not generalize well to the medical domain as is without utilizing a large amount of compute resources for fine-tuning and using task-specific prompts. Moreover, these prompts are in the form of bounding-boxes or foreground/background points that need to be annotated explicitly for every image, making this solution increasingly tedious with higher data size. In this work, we propose AdaptiveSAM - an adaptive modification of SAM that can adjust to new datasets quickly and efficiently, while enabling text-prompted segmentation. For finetuning AdaptiveSAM, we propose an approach called bias-tuning that requires a significantly smaller number of trainable parameters than SAM (less than 2\%). At the same time, AdaptiveSAM requires negligible expert intervention since it uses free-form text as prompt and can segment the object of interest with just the label name as prompt. Our experiments show that AdaptiveSAM outperforms current state-of-the-art methods on various medical imaging datasets including surgery, ultrasound and X-ray. Code is available at https://github.com/JayParanjape/biastuning
Cross-Dataset Adaptation for Instrument Classification in Cataract Surgery Videos
Jul 31, 2023Surgical tool presence detection is an important part of the intra-operative and post-operative analysis of a surgery. State-of-the-art models, which perform this task well on a particular dataset, however, perform poorly when tested on another dataset. This occurs due to a significant domain shift between the datasets resulting from the use of different tools, sensors, data resolution etc. In this paper, we highlight this domain shift in the commonly performed cataract surgery and propose a novel end-to-end Unsupervised Domain Adaptation (UDA) method called the Barlow Adaptor that addresses the problem of distribution shift without requiring any labels from another domain. In addition, we introduce a novel loss called the Barlow Feature Alignment Loss (BFAL) which aligns features across different domains while reducing redundancy and the need for higher batch sizes, thus improving cross-dataset performance. The use of BFAL is a novel approach to address the challenge of domain shift in cataract surgery data. Extensive experiments are conducted on two cataract surgery datasets and it is shown that the proposed method outperforms the state-of-the-art UDA methods by 6%. The code can be found at https://github.com/JayParanjape/Barlow-Adaptor
Characterizing the Weight Space for Different Learning Models
Jun 04, 2020
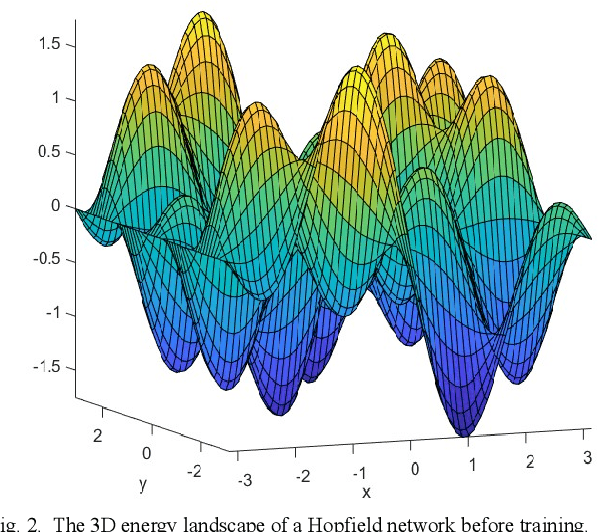
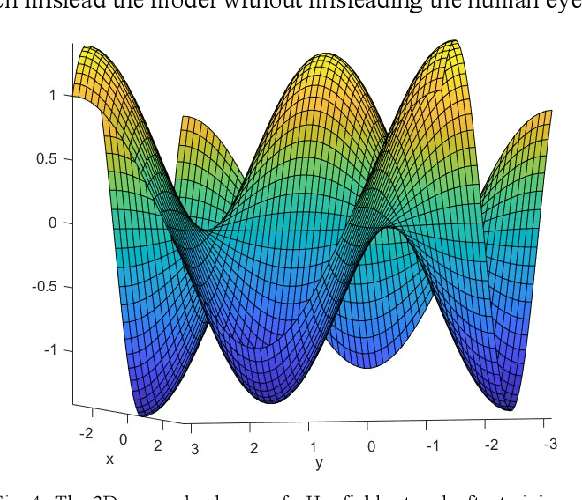
Deep Learning has become one of the primary research areas in developing intelligent machines. Most of the well-known applications (such as Speech Recognition, Image Processing and NLP) of AI are driven by Deep Learning. Deep Learning algorithms mimic human brain using artificial neural networks and progressively learn to accurately solve a given problem. But there are significant challenges in Deep Learning systems. There have been many attempts to make deep learning models imitate the biological neural network. However, many deep learning models have performed poorly in the presence of adversarial examples. Poor performance in adversarial examples leads to adversarial attacks and in turn leads to safety and security in most of the applications. In this paper we make an attempt to characterize the solution space of a deep neural network in terms of three different subsets viz. weights belonging to exact trained patterns, weights belonging to generalized pattern set and weights belonging to adversarial pattern sets. We attempt to characterize the solution space with two seemingly different learning paradigms viz. the Deep Neural Networks and the Dense Associative Memory Model, which try to achieve learning via quite different mechanisms. We also show that adversarial attacks are generally less successful against Associative Memory Models than Deep Neural Networks.