 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlock Policy Mirror Descent
Jan 15, 2022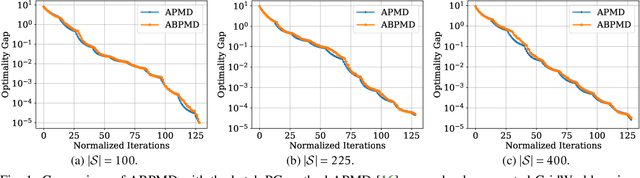
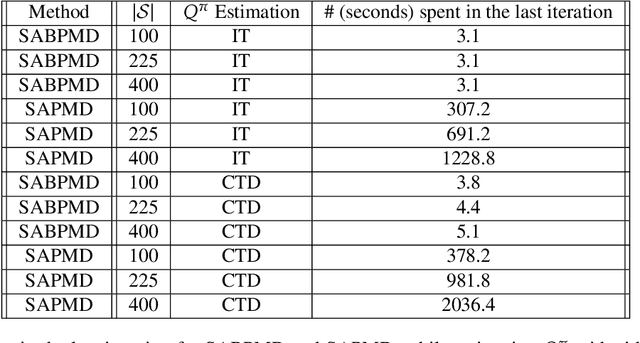
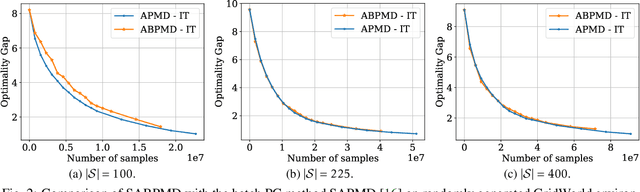
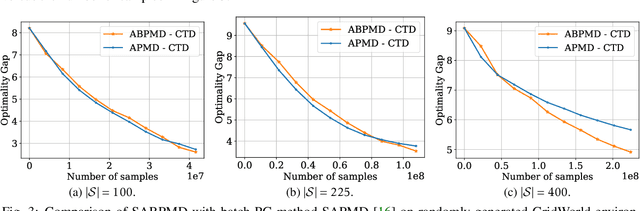
In this paper, we present a new class of policy gradient (PG) methods, namely the block policy mirror descent (BPMD) methods for solving a class of regularized reinforcement learning (RL) problems with (strongly) convex regularizers. Compared to the traditional PG methods with batch update rule, which visit and update the policy for every state, BPMD methods have cheap per-iteration computation via a partial update rule that performs the policy update on a sampled state. Despite the nonconvex nature of the problem and a partial update rule, BPMD methods achieve fast linear convergence to the global optimality. We further extend BPMD methods to the stochastic setting, by utilizing stochastic first-order information constructed from samples. We establish $\cO(1/\epsilon)$ (resp. $\cO(1/\epsilon^2)$) sample complexity for the strongly convex (resp. non-strongly convex) regularizers, with different procedures for constructing the stochastic first-order information, where $\epsilon$ denotes the target accuracy. To the best of our knowledge, this is the first time that block coordinate descent methods have been developed and analyzed for policy optimization in reinforcement learning.
Deep Learning Assisted End-to-End Synthesis of mm-Wave Passive Networks with 3D EM Structures: A Study on A Transformer-Based Matching Network
Jan 06, 2022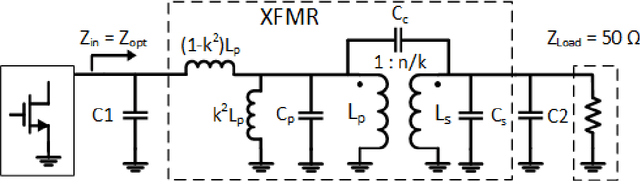
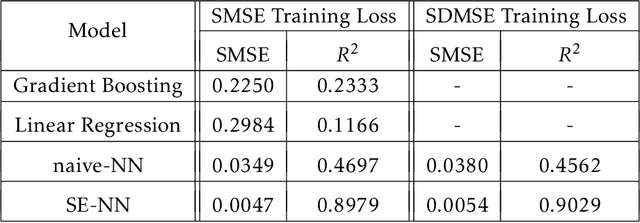
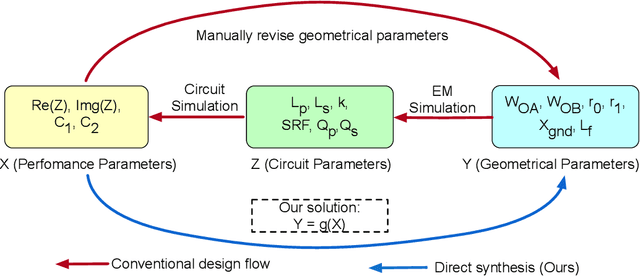
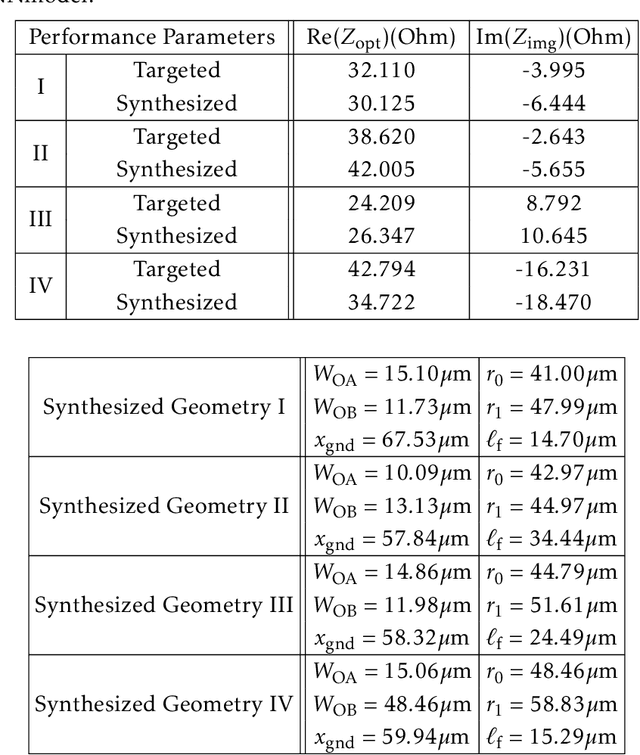
This paper presents a deep learning assisted synthesis approach for direct end-to-end generation of RF/mm-wave passive matching network with 3D EM structures. Different from prior approaches that synthesize EM structures from target circuit component values and target topologies, our proposed approach achieves the direct synthesis of the passive network given the network topology from desired performance values as input. We showcase the proposed synthesis Neural Network (NN) model on an on-chip 1:1 transformer-based impedance matching network. By leveraging parameter sharing, the synthesis NN model successfully extracts relevant features from the input impedance and load capacitors, and predict the transformer 3D EM geometry in a 45nm SOI process that will match the standard 50$\Omega$ load to the target input impedance while absorbing the two loading capacitors. As a proof-of-concept, several example transformer geometries were synthesized, and verified in Ansys HFSS to provide the desired input impedance.
Deep Nonparametric Estimation of Operators between Infinite Dimensional Spaces
Jan 01, 2022
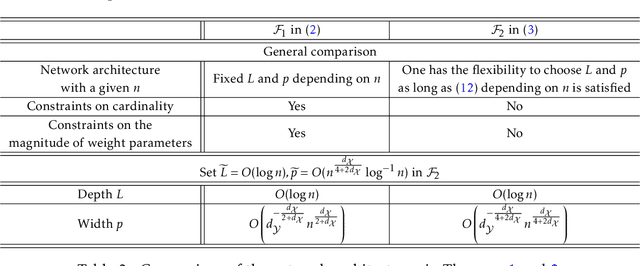
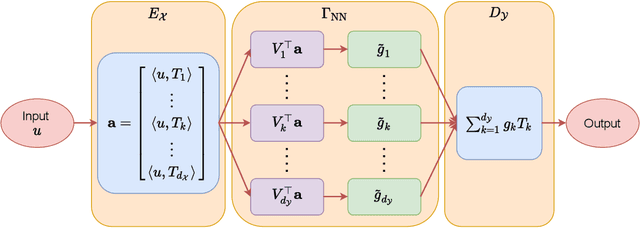
Learning operators between infinitely dimensional spaces is an important learning task arising in wide applications in machine learning, imaging science, mathematical modeling and simulations, etc. This paper studies the nonparametric estimation of Lipschitz operators using deep neural networks. Non-asymptotic upper bounds are derived for the generalization error of the empirical risk minimizer over a properly chosen network class. Under the assumption that the target operator exhibits a low dimensional structure, our error bounds decay as the training sample size increases, with an attractive fast rate depending on the intrinsic dimension in our estimation. Our assumptions cover most scenarios in real applications and our results give rise to fast rates by exploiting low dimensional structures of data in operator estimation. We also investigate the influence of network structures (e.g., network width, depth, and sparsity) on the generalization error of the neural network estimator and propose a general suggestion on the choice of network structures to maximize the learning efficiency quantitatively.
Learning Generalizable Vision-Tactile Robotic Grasping Strategy for Deformable Objects via Transformer
Dec 20, 2021

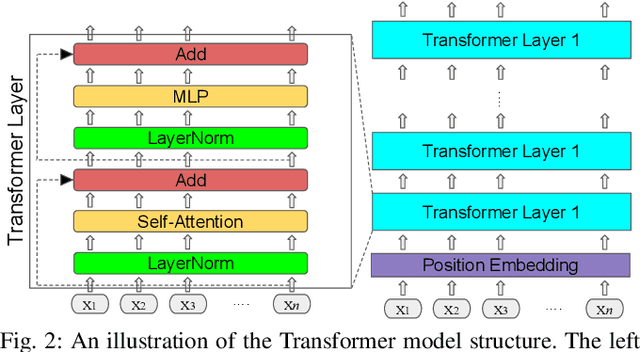
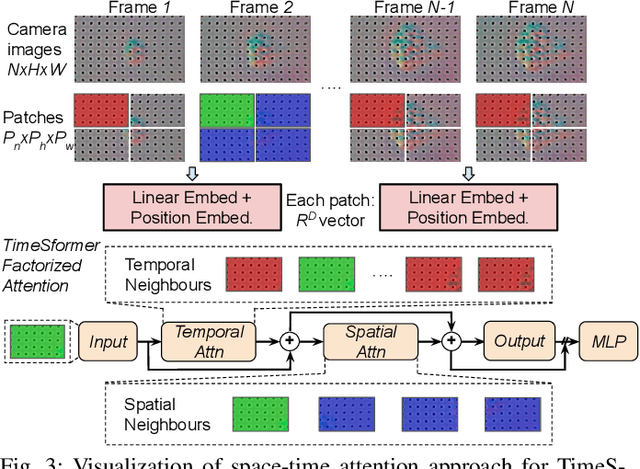
Reliable robotic grasping, especially with deformable objects such as fruits, remains a challenging task due to underactuated contact interactions with a gripper, unknown object dynamics and geometries. In this study, we propose a Transformer-based robotic grasping framework for rigid grippers that leverage tactile and visual information for safe object grasping. Specifically, the Transformer models learn physical feature embeddings with sensor feedback through performing two pre-defined explorative actions (pinching and sliding) and predict a grasping outcome through a multilayer perceptron (MLP) with a given grasping strength. Using these predictions, the gripper predicts a safe grasping strength via inference. Compared with convolutional recurrent networks (CNN), the Transformer models can capture the long-term dependencies across the image sequences and process spatial-temporal features simultaneously. We first benchmark the Transformer models on a public dataset for slip detection. Following that, we show that the Transformer models outperform a CNN+LSTM model in terms of grasping accuracy and computational efficiency. We also collect our fruit grasping dataset and conduct online grasping experiments using the proposed framework for both seen and unseen fruits. Our codes and dataset are public on GitHub.
Frequency-aware SGD for Efficient Embedding Learning with Provable Benefits
Oct 24, 2021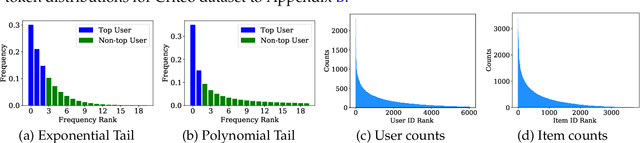
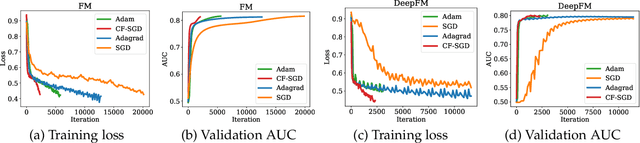

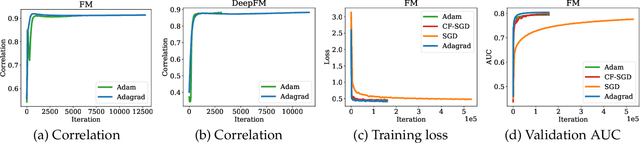
Embedding learning has found widespread applications in recommendation systems and natural language modeling, among other domains. To learn quality embeddings efficiently, adaptive learning rate algorithms have demonstrated superior empirical performance over SGD, largely accredited to their token-dependent learning rate. However, the underlying mechanism for the efficiency of token-dependent learning rate remains underexplored. We show that incorporating frequency information of tokens in the embedding learning problems leads to provably efficient algorithms, and demonstrate that common adaptive algorithms implicitly exploit the frequency information to a large extent. Specifically, we propose (Counter-based) Frequency-aware Stochastic Gradient Descent, which applies a frequency-dependent learning rate for each token, and exhibits provable speed-up compared to SGD when the token distribution is imbalanced. Empirically, we show the proposed algorithms are able to improve or match adaptive algorithms on benchmark recommendation tasks and a large-scale industrial recommendation system, closing the performance gap between SGD and adaptive algorithms. Our results are the first to show token-dependent learning rate provably improves convergence for non-convex embedding learning problems.
Taming Sparsely Activated Transformer with Stochastic Experts
Oct 12, 2021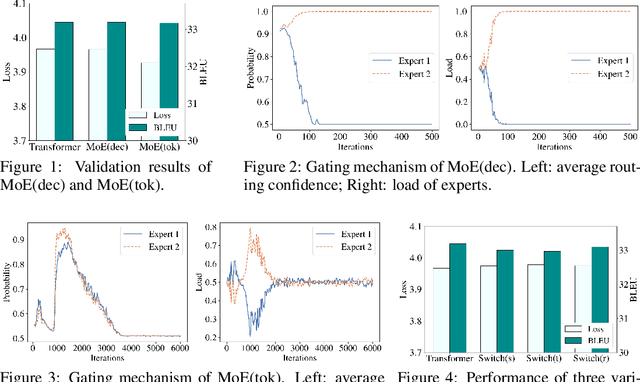
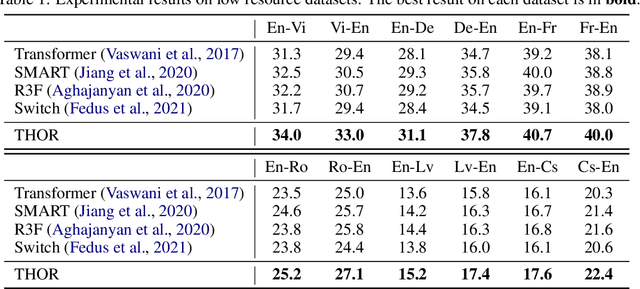
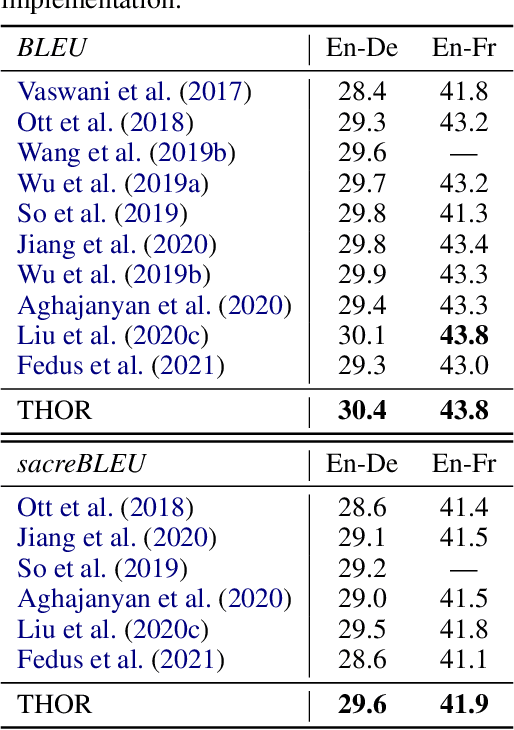

Sparsely activated models (SAMs), such as Mixture-of-Experts (MoE), can easily scale to have outrageously large amounts of parameters without significant increase in computational cost. However, SAMs are reported to be parameter inefficient such that larger models do not always lead to better performance. While most on-going research focuses on improving SAMs models by exploring methods of routing inputs to experts, our analysis reveals that such research might not lead to the solution we expect, i.e., the commonly-used routing methods based on gating mechanisms do not work better than randomly routing inputs to experts. In this paper, we propose a new expert-based model, THOR (Transformer witH StOchastic ExpeRts). Unlike classic expert-based models, such as the Switch Transformer, experts in THOR are randomly activated for each input during training and inference. THOR models are trained using a consistency regularized loss, where experts learn not only from training data but also from other experts as teachers, such that all the experts make consistent predictions. We validate the effectiveness of THOR on machine translation tasks. Results show that THOR models are more parameter efficient in that they significantly outperform the Transformer and MoE models across various settings. For example, in multilingual translation, THOR outperforms the Switch Transformer by 2 BLEU scores, and obtains the same BLEU score as that of a state-of-the-art MoE model that is 18 times larger. Our code is publicly available at: https://github.com/microsoft/Stochastic-Mixture-of-Experts.
Large Learning Rate Tames Homogeneity: Convergence and Balancing Effect
Oct 07, 2021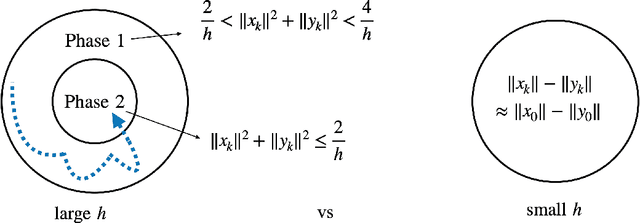
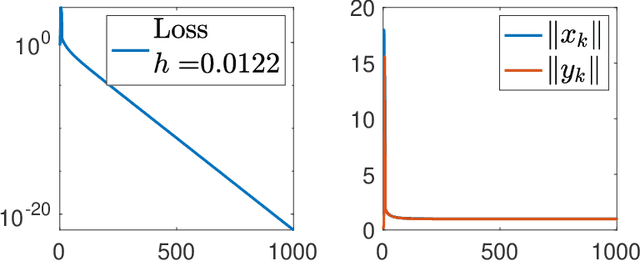
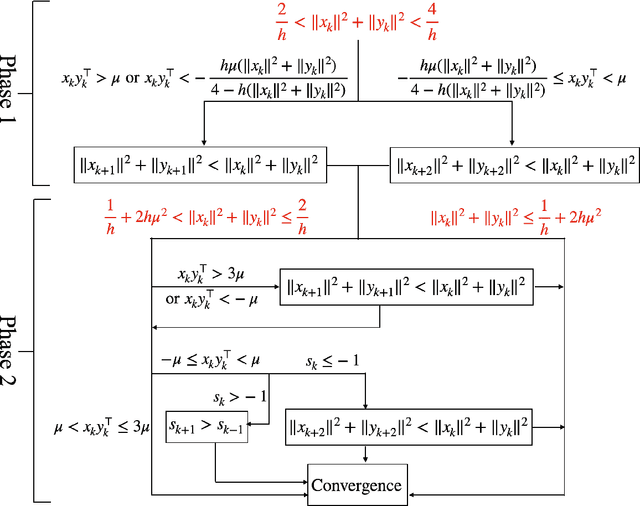
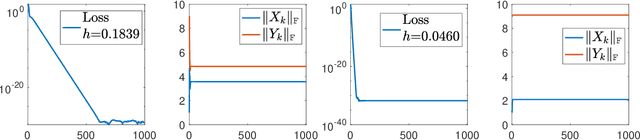
Recent empirical advances show that training deep models with large learning rate often improves generalization performance. However, theoretical justifications on the benefits of large learning rate are highly limited, due to challenges in analysis. In this paper, we consider using Gradient Descent (GD) with a large learning rate on a homogeneous matrix factorization problem, i.e., $\min_{X, Y} \|A - XY^\top\|_{\sf F}^2$. We prove a convergence theory for constant large learning rates well beyond $2/L$, where $L$ is the largest eigenvalue of Hessian at the initialization. Moreover, we rigorously establish an implicit bias of GD induced by such a large learning rate, termed 'balancing', meaning that magnitudes of $X$ and $Y$ at the limit of GD iterations will be close even if their initialization is significantly unbalanced. Numerical experiments are provided to support our theory.
Adversarially Regularized Policy Learning Guided by Trajectory Optimization
Sep 16, 2021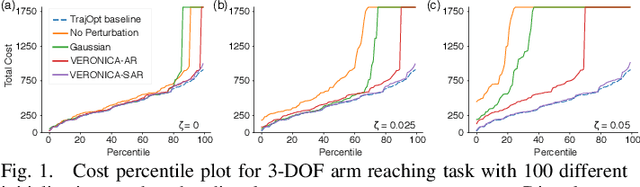
Recent advancement in combining trajectory optimization with function approximation (especially neural networks) shows promise in learning complex control policies for diverse tasks in robot systems. Despite their great flexibility, the large neural networks for parameterizing control policies impose significant challenges. The learned neural control policies are often overcomplex and non-smooth, which can easily cause unexpected or diverging robot motions. Therefore, they often yield poor generalization performance in practice. To address this issue, we propose adVErsarially Regularized pOlicy learNIng guided by trajeCtory optimizAtion (VERONICA) for learning smooth control policies. Specifically, our proposed approach controls the smoothness (local Lipschitz continuity) of the neural control policies by stabilizing the output control with respect to the worst-case perturbation to the input state. Our experiments on robot manipulation show that our proposed approach not only improves the sample efficiency of neural policy learning but also enhances the robustness of the policy against various types of disturbances, including sensor noise, environmental uncertainty, and model mismatch.
Self-Training with Differentiable Teacher
Sep 15, 2021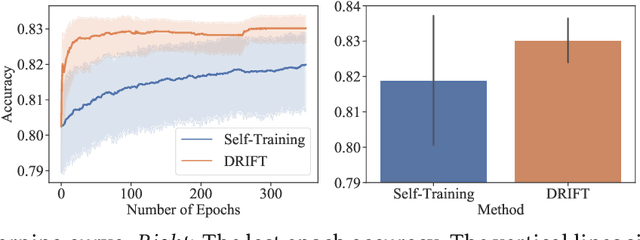
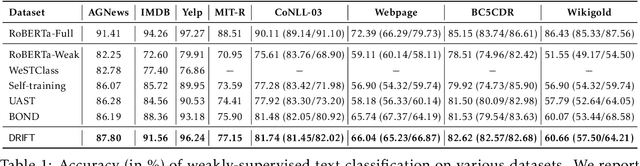
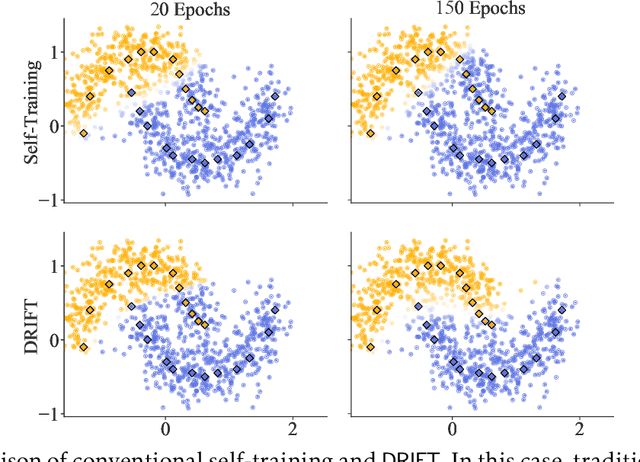
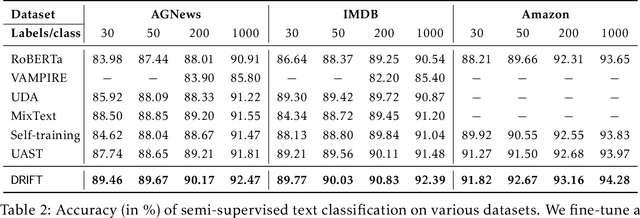
Self-training achieves enormous success in various semi-supervised and weakly-supervised learning tasks. The method can be interpreted as a teacher-student framework, where the teacher generates pseudo-labels, and the student makes predictions. The two models are updated alternatingly. However, such a straightforward alternating update rule leads to training instability. This is because a small change in the teacher may result in a significant change in the student. To address this issue, we propose {\ours}, short for differentiable self-training, that treats teacher-student as a Stackelberg game. In this game, a leader is always in a more advantageous position than a follower. In self-training, the student contributes to the prediction performance, and the teacher controls the training process by generating pseudo-labels. Therefore, we treat the student as the leader and the teacher as the follower. The leader procures its advantage by acknowledging the follower's strategy, which involves differentiable pseudo-labels and differentiable sample weights. Consequently, the leader-follower interaction can be effectively captured via Stackelberg gradient, obtained by differentiating the follower's strategy. Experimental results on semi- and weakly-supervised classification and named entity recognition tasks show that our model outperforms existing approaches by large margins.
ARCH: Efficient Adversarial Regularized Training with Caching
Sep 15, 2021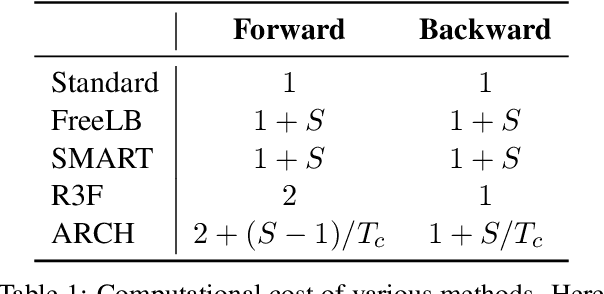
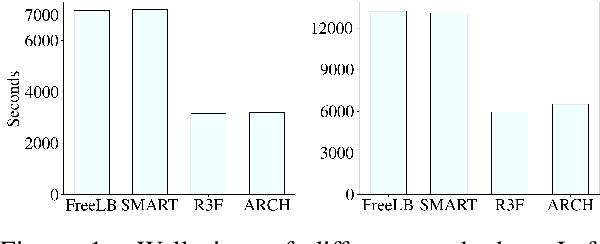
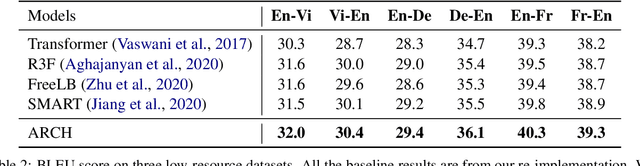
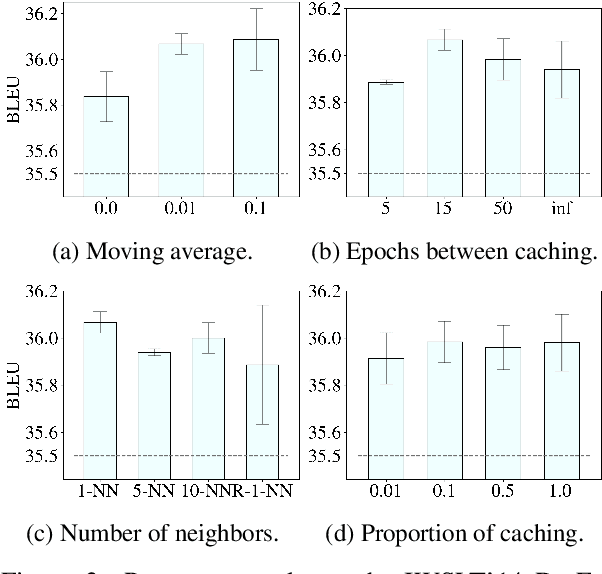
Adversarial regularization can improve model generalization in many natural language processing tasks. However, conventional approaches are computationally expensive since they need to generate a perturbation for each sample in each epoch. We propose a new adversarial regularization method ARCH (adversarial regularization with caching), where perturbations are generated and cached once every several epochs. As caching all the perturbations imposes memory usage concerns, we adopt a K-nearest neighbors-based strategy to tackle this issue. The strategy only requires caching a small amount of perturbations, without introducing additional training time. We evaluate our proposed method on a set of neural machine translation and natural language understanding tasks. We observe that ARCH significantly eases the computational burden (saves up to 70\% of computational time in comparison with conventional approaches). More surprisingly, by reducing the variance of stochastic gradients, ARCH produces a notably better (in most of the tasks) or comparable model generalization. Our code is publicly available.