 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrift No More? Context Equilibria in Multi-Turn LLM Interactions
Oct 09, 2025Large Language Models (LLMs) excel at single-turn tasks such as instruction following and summarization, yet real-world deployments require sustained multi-turn interactions where user goals and conversational context persist and evolve. A recurring challenge in this setting is context drift: the gradual divergence of a model's outputs from goal-consistent behavior across turns. Unlike single-turn errors, drift unfolds temporally and is poorly captured by static evaluation metrics. In this work, we present a study of context drift in multi-turn interactions and propose a simple dynamical framework to interpret its behavior. We formalize drift as the turn-wise KL divergence between the token-level predictive distributions of the test model and a goal-consistent reference model, and propose a recurrence model that interprets its evolution as a bounded stochastic process with restoring forces and controllable interventions. We instantiate this framework in both synthetic long-horizon rewriting tasks and realistic user-agent simulations such as in $\tau$-Bench, measuring drift for several open-weight LLMs that are used as user simulators. Our experiments consistently reveal stable, noise-limited equilibria rather than runaway degradation, and demonstrate that simple reminder interventions reliably reduce divergence in line with theoretical predictions. Together, these results suggest that multi-turn drift can be understood as a controllable equilibrium phenomenon rather than as inevitable decay, providing a foundation for studying and mitigating context drift in extended interactions.
Steering MoE LLMs via Expert (De)Activation
Sep 11, 2025



Mixture-of-Experts (MoE) in Large Language Models (LLMs) routes each token through a subset of specialized Feed-Forward Networks (FFN), known as experts. We present SteerMoE, a framework for steering MoE models by detecting and controlling behavior-linked experts. Our detection method identifies experts with distinct activation patterns across paired inputs exhibiting contrasting behaviors. By selectively (de)activating such experts during inference, we control behaviors like faithfulness and safety without retraining or modifying weights. Across 11 benchmarks and 6 LLMs, our steering raises safety by up to +20% and faithfulness by +27%. In adversarial attack mode, it drops safety by -41% alone, and -100% when combined with existing jailbreak methods, bypassing all safety guardrails and exposing a new dimension of alignment faking hidden within experts.
FIFA: Unified Faithfulness Evaluation Framework for Text-to-Video and Video-to-Text Generation
Jul 09, 2025

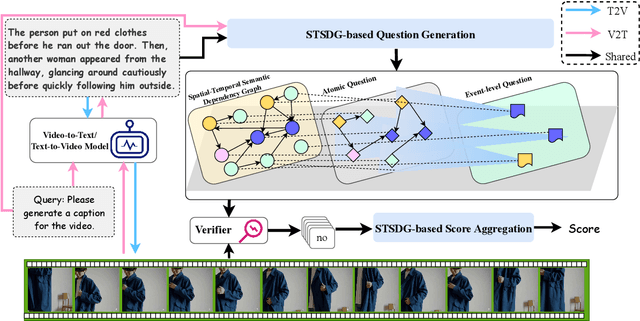
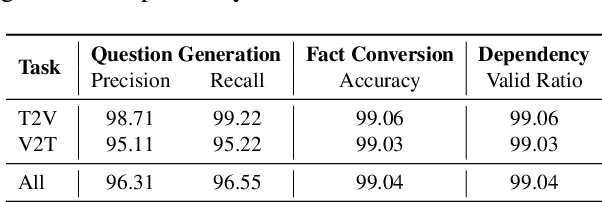
Video Multimodal Large Language Models (VideoMLLMs) have achieved remarkable progress in both Video-to-Text and Text-to-Video tasks. However, they often suffer fro hallucinations, generating content that contradicts the visual input. Existing evaluation methods are limited to one task (e.g., V2T) and also fail to assess hallucinations in open-ended, free-form responses. To address this gap, we propose FIFA, a unified FaIthFulness evAluation framework that extracts comprehensive descriptive facts, models their semantic dependencies via a Spatio-Temporal Semantic Dependency Graph, and verifies them using VideoQA models. We further introduce Post-Correction, a tool-based correction framework that revises hallucinated content. Extensive experiments demonstrate that FIFA aligns more closely with human judgment than existing evaluation methods, and that Post-Correction effectively improves factual consistency in both text and video generation.
Context-Informed Grounding Supervision
Jun 18, 2025Large language models (LLMs) are often supplemented with external knowledge to provide information not encoded in their parameters or to reduce hallucination. In such cases, we expect the model to generate responses by grounding its response in the provided external context. However, prior work has shown that simply appending context at inference time does not ensure grounded generation. To address this, we propose Context-INformed Grounding Supervision (CINGS), a post-training supervision in which the model is trained with relevant context prepended to the response, while computing the loss only over the response tokens and masking out the context. Our experiments demonstrate that models trained with CINGS exhibit stronger grounding in both textual and visual domains compared to standard instruction-tuned models. In the text domain, CINGS outperforms other training methods across 11 information-seeking datasets and is complementary to inference-time grounding techniques. In the vision-language domain, replacing a vision-language model's LLM backbone with a CINGS-trained model reduces hallucinations across four benchmarks and maintains factual consistency throughout the generated response. This improved grounding comes without degradation in general downstream performance. Finally, we analyze the mechanism underlying the enhanced grounding in CINGS and find that it induces a shift in the model's prior knowledge and behavior, implicitly encouraging greater reliance on the external context.
MS4UI: A Dataset for Multi-modal Summarization of User Interface Instructional Videos
Jun 14, 2025We study multi-modal summarization for instructional videos, whose goal is to provide users an efficient way to learn skills in the form of text instructions and key video frames. We observe that existing benchmarks focus on generic semantic-level video summarization, and are not suitable for providing step-by-step executable instructions and illustrations, both of which are crucial for instructional videos. We propose a novel benchmark for user interface (UI) instructional video summarization to fill the gap. We collect a dataset of 2,413 UI instructional videos, which spans over 167 hours. These videos are manually annotated for video segmentation, text summarization, and video summarization, which enable the comprehensive evaluations for concise and executable video summarization. We conduct extensive experiments on our collected MS4UI dataset, which suggest that state-of-the-art multi-modal summarization methods struggle on UI video summarization, and highlight the importance of new methods for UI instructional video summarization.
Learning to Clarify by Reinforcement Learning Through Reward-Weighted Fine-Tuning
Jun 08, 2025



Question answering (QA) agents automatically answer questions posed in natural language. In this work, we learn to ask clarifying questions in QA agents. The key idea in our method is to simulate conversations that contain clarifying questions and learn from them using reinforcement learning (RL). To make RL practical, we propose and analyze offline RL objectives that can be viewed as reward-weighted supervised fine-tuning (SFT) and easily optimized in large language models. Our work stands in a stark contrast to recently proposed methods, based on SFT and direct preference optimization, which have additional hyper-parameters and do not directly optimize rewards. We compare to these methods empirically and report gains in both optimized rewards and language quality.
Understanding Generative AI Capabilities in Everyday Image Editing Tasks
May 22, 2025Generative AI (GenAI) holds significant promise for automating everyday image editing tasks, especially following the recent release of GPT-4o on March 25, 2025. However, what subjects do people most often want edited? What kinds of editing actions do they want to perform (e.g., removing or stylizing the subject)? Do people prefer precise edits with predictable outcomes or highly creative ones? By understanding the characteristics of real-world requests and the corresponding edits made by freelance photo-editing wizards, can we draw lessons for improving AI-based editors and determine which types of requests can currently be handled successfully by AI editors? In this paper, we present a unique study addressing these questions by analyzing 83k requests from the past 12 years (2013-2025) on the Reddit community, which collected 305k PSR-wizard edits. According to human ratings, approximately only 33% of requests can be fulfilled by the best AI editors (including GPT-4o, Gemini-2.0-Flash, SeedEdit). Interestingly, AI editors perform worse on low-creativity requests that require precise editing than on more open-ended tasks. They often struggle to preserve the identity of people and animals, and frequently make non-requested touch-ups. On the other side of the table, VLM judges (e.g., o1) perform differently from human judges and may prefer AI edits more than human edits. Code and qualitative examples are available at: https://psrdataset.github.io
YoChameleon: Personalized Vision and Language Generation
Apr 29, 2025Large Multimodal Models (e.g., GPT-4, Gemini, Chameleon) have evolved into powerful tools with millions of users. However, they remain generic models and lack personalized knowledge of specific user concepts. Previous work has explored personalization for text generation, yet it remains unclear how these methods can be adapted to new modalities, such as image generation. In this paper, we introduce Yo'Chameleon, the first attempt to study personalization for large multimodal models. Given 3-5 images of a particular concept, Yo'Chameleon leverages soft-prompt tuning to embed subject-specific information to (i) answer questions about the subject and (ii) recreate pixel-level details to produce images of the subject in new contexts. Yo'Chameleon is trained with (i) a self-prompting optimization mechanism to balance performance across multiple modalities, and (ii) a ``soft-positive" image generation approach to enhance image quality in a few-shot setting.
CORG: Generating Answers from Complex, Interrelated Contexts
Apr 25, 2025In a real-world corpus, knowledge frequently recurs across documents but often contains inconsistencies due to ambiguous naming, outdated information, or errors, leading to complex interrelationships between contexts. Previous research has shown that language models struggle with these complexities, typically focusing on single factors in isolation. We classify these relationships into four types: distracting, ambiguous, counterfactual, and duplicated. Our analysis reveals that no single approach effectively addresses all these interrelationships simultaneously. Therefore, we introduce Context Organizer (CORG), a framework that organizes multiple contexts into independently processed groups. This design allows the model to efficiently find all relevant answers while ensuring disambiguation. CORG consists of three key components: a graph constructor, a reranker, and an aggregator. Our results demonstrate that CORG balances performance and efficiency effectively, outperforming existing grouping methods and achieving comparable results to more computationally intensive, single-context approaches.
NoLiMa: Long-Context Evaluation Beyond Literal Matching
Feb 07, 2025Recent large language models (LLMs) support long contexts ranging from 128K to 1M tokens. A popular method for evaluating these capabilities is the needle-in-a-haystack (NIAH) test, which involves retrieving a "needle" (relevant information) from a "haystack" (long irrelevant context). Extensions of this approach include increasing distractors, fact chaining, and in-context reasoning. However, in these benchmarks, models can exploit existing literal matches between the needle and haystack to simplify the task. To address this, we introduce NoLiMa, a benchmark extending NIAH with a carefully designed needle set, where questions and needles have minimal lexical overlap, requiring models to infer latent associations to locate the needle within the haystack. We evaluate 12 popular LLMs that claim to support contexts of at least 128K tokens. While they perform well in short contexts (<1K), performance degrades significantly as context length increases. At 32K, for instance, 10 models drop below 50% of their strong short-length baselines. Even GPT-4o, one of the top-performing exceptions, experiences a reduction from an almost-perfect baseline of 99.3% to 69.7%. Our analysis suggests these declines stem from the increased difficulty the attention mechanism faces in longer contexts when literal matches are absent, making it harder to retrieve relevant information.