 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiPreManip: Learning Affordance-Based Bimanual Preparatory Manipulation through Anticipatory Collaboration
Mar 23, 2026Many everyday objects are difficult to directly grasp (e.g., a flat iPad) or manipulate functionally (e.g., opening the cap of a pen lying on a desk). Such tasks require sequential, asymmetric coordination between two arms, where one arm performs preparatory manipulation that enables the other's goal-directed action - for instance, pushing the iPad to the table's edge before picking it up, or lifting the pen body to allow the other hand to remove its cap. In this work, we introduce Collaborative Preparatory Manipulation, a class of bimanual manipulation tasks that demand understanding object semantics and geometry, anticipating spatial relationships, and planning long-horizon coordinated actions between the two arms. To tackle this challenge, we propose a visual affordance-based framework that first envisions the final goal-directed action and then guides one arm to perform a sequence of preparatory manipulations that facilitate the other arm's subsequent operation. This affordance-centric representation enables anticipatory inter-arm reasoning and coordination, generalizing effectively across various objects spanning diverse categories. Extensive experiments in both simulation and the real world demonstrate that our approach substantially improves task success rates and generalization compared to competitive baselines.
NLP4Neuro: Sequence-to-sequence learning for neural population decoding
Jul 03, 2025



Delineating how animal behavior arises from neural activity is a foundational goal of neuroscience. However, as the computations underlying behavior unfold in networks of thousands of individual neurons across the entire brain, this presents challenges for investigating neural roles and computational mechanisms in large, densely wired mammalian brains during behavior. Transformers, the backbones of modern large language models (LLMs), have become powerful tools for neural decoding from smaller neural populations. These modern LLMs have benefited from extensive pre-training, and their sequence-to-sequence learning has been shown to generalize to novel tasks and data modalities, which may also confer advantages for neural decoding from larger, brain-wide activity recordings. Here, we present a systematic evaluation of off-the-shelf LLMs to decode behavior from brain-wide populations, termed NLP4Neuro, which we used to test LLMs on simultaneous calcium imaging and behavior recordings in larval zebrafish exposed to visual motion stimuli. Through NLP4Neuro, we found that LLMs become better at neural decoding when they use pre-trained weights learned from textual natural language data. Moreover, we found that a recent mixture-of-experts LLM, DeepSeek Coder-7b, significantly improved behavioral decoding accuracy, predicted tail movements over long timescales, and provided anatomically consistent highly interpretable readouts of neuron salience. NLP4Neuro demonstrates that LLMs are highly capable of informing brain-wide neural circuit dissection.
MinD: Unified Visual Imagination and Control via Hierarchical World Models
Jun 23, 2025



Video generation models (VGMs) offer a promising pathway for unified world modeling in robotics by integrating simulation, prediction, and manipulation. However, their practical application remains limited due to (1) slowgeneration speed, which limits real-time interaction, and (2) poor consistency between imagined videos and executable actions. To address these challenges, we propose Manipulate in Dream (MinD), a hierarchical diffusion-based world model framework that employs a dual-system design for vision-language manipulation. MinD executes VGM at low frequencies to extract video prediction features, while leveraging a high-frequency diffusion policy for real-time interaction. This architecture enables low-latency, closed-loop control in manipulation with coherent visual guidance. To better coordinate the two systems, we introduce a video-action diffusion matching module (DiffMatcher), with a novel co-training strategy that uses separate schedulers for each diffusion model. Specifically, we introduce a diffusion-forcing mechanism to DiffMatcher that aligns their intermediate representations during training, helping the fast action model better understand video-based predictions. Beyond manipulation, MinD also functions as a world simulator, reliably predicting task success or failure in latent space before execution. Trustworthy analysis further shows that VGMs can preemptively evaluate task feasibility and mitigate risks. Extensive experiments across multiple benchmarks demonstrate that MinD achieves state-of-the-art manipulation (63%+) in RL-Bench, advancing the frontier of unified world modeling in robotics.
Multi-robot Social-aware Cooperative Planning in Pedestrian Environments Using Multi-agent Reinforcement Learning
Nov 29, 2022Safe and efficient co-planning of multiple robots in pedestrian participation environments is promising for applications. In this work, a novel multi-robot social-aware efficient cooperative planner that on the basis of off-policy multi-agent reinforcement learning (MARL) under partial dimension-varying observation and imperfect perception conditions is proposed. We adopt temporal-spatial graph (TSG)-based social encoder to better extract the importance of social relation between each robot and the pedestrians in its field of view (FOV). Also, we introduce K-step lookahead reward setting in multi-robot RL framework to avoid aggressive, intrusive, short-sighted, and unnatural motion decisions generated by robots. Moreover, we improve the traditional centralized critic network with multi-head global attention module to better aggregates local observation information among different robots to guide the process of individual policy update. Finally, multi-group experimental results verify the effectiveness of the proposed cooperative motion planner.
Multi-agent Soft Actor-Critic Based Hybrid Motion Planner for Mobile Robots
Dec 13, 2021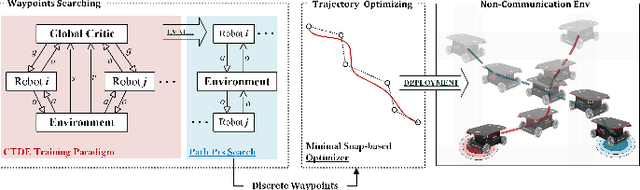
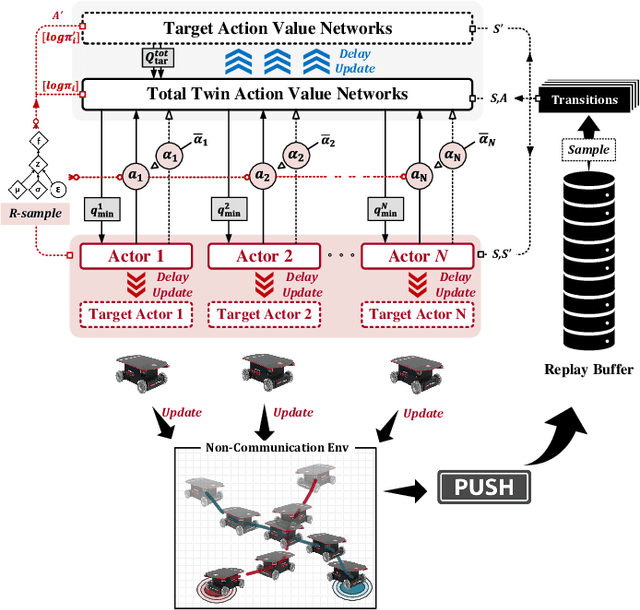
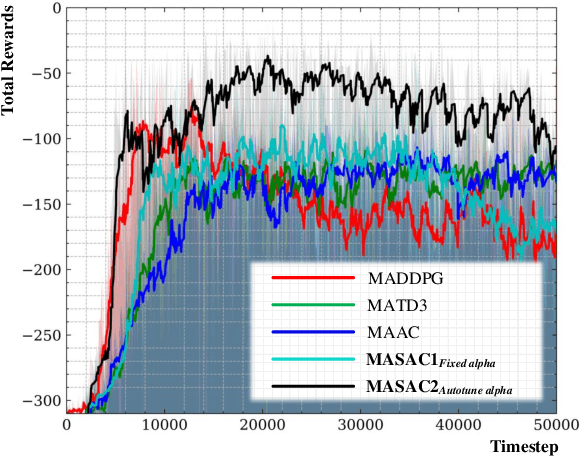
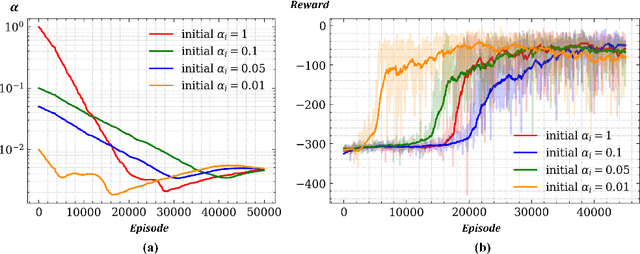
In this paper, a novel hybrid multi-robot motion planner that can be applied under non-communication and local observable conditions is presented. The planner is model-free and can realize the end-to-end mapping of multi-robot state and observation information to final smooth and continuous trajectories. The planner is a front-end and back-end separated architecture. The design of the front-end collaborative waypoints searching module is based on the multi-agent soft actor-critic algorithm under the centralized training with decentralized execution diagram. The design of the back-end trajectory optimization module is based on the minimal snap method with safety zone constraints. This module can output the final dynamic-feasible and executable trajectories. Finally, multi-group experimental results verify the effectiveness of the proposed motion planner.
A review of mobile robot motion planning methods: from classical motion planning workflows to reinforcement learning-based architectures
Sep 06, 2021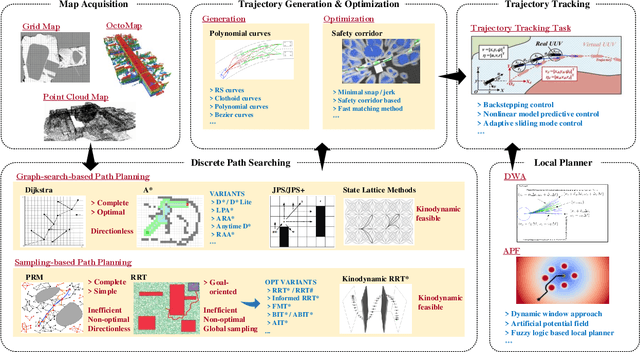
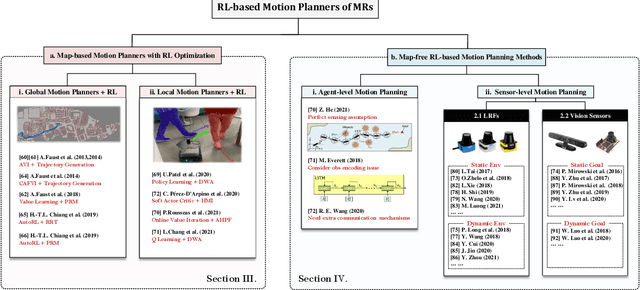
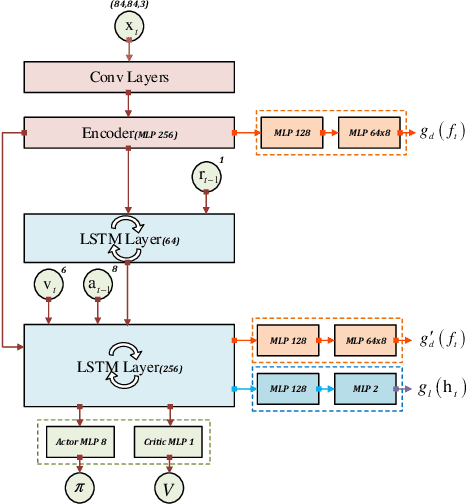
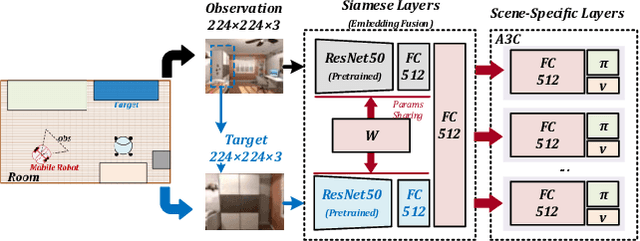
Motion planning is critical to realize the autonomous operation of mobile robots. As the complexity and stochasticity of robot application scenarios increase, the planning capability of the classical hierarchical motion planners is challenged. In recent years, with the development of intelligent computation technology, the deep reinforcement learning (DRL) based motion planning algorithm has gradually become a research hotspot due to its advantageous features such as not relying on the map prior, model-free, and unified global and local planning paradigms. In this paper, we provide a systematic review of various motion planning methods. First, we summarize the representative and cutting-edge algorithms for each submodule of the classical motion planning architecture and analyze their performance limitations. Subsequently, we concentrate on reviewing RL-based motion planning approaches, including RL optimization motion planners, map-free end-to-end methods that integrate sensing and decision-making, and multi-robot cooperative planning methods. Last but not least, we analyze the urgent challenges faced by these mainstream RL-based motion planners in detail, review some state-of-the-art works for these issues, and propose suggestions for future research.