 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCIE_Interaction Solution for Ego4D Social Interaction Challenge
May 30, 2025This report presents our team's PCIE_Interaction solution for the Ego4D Social Interaction Challenge at CVPR 2025, addressing both Looking At Me (LAM) and Talking To Me (TTM) tasks. The challenge requires accurate detection of social interactions between subjects and the camera wearer, with LAM relying exclusively on face crop sequences and TTM combining speaker face crops with synchronized audio segments. In the LAM track, we employ face quality enhancement and ensemble methods. For the TTM task, we extend visual interaction analysis by fusing audio and visual cues, weighted by a visual quality score. Our approach achieved 0.81 and 0.71 mean average precision (mAP) on the LAM and TTM challenges leader board. Code is available at https://github.com/KanokphanL/PCIE_Ego4D_Social_Interaction
PCIE_Pose Solution for EgoExo4D Pose and Proficiency Estimation Challenge
May 30, 2025This report introduces our team's (PCIE_EgoPose) solutions for the EgoExo4D Pose and Proficiency Estimation Challenges at CVPR2025. Focused on the intricate task of estimating 21 3D hand joints from RGB egocentric videos, which are complicated by subtle movements and frequent occlusions, we developed the Hand Pose Vision Transformer (HP-ViT+). This architecture synergizes a Vision Transformer and a CNN backbone, using weighted fusion to refine the hand pose predictions. For the EgoExo4D Body Pose Challenge, we adopted a multimodal spatio-temporal feature integration strategy to address the complexities of body pose estimation across dynamic contexts. Our methods achieved remarkable performance: 8.31 PA-MPJPE in the Hand Pose Challenge and 11.25 MPJPE in the Body Pose Challenge, securing championship titles in both competitions. We extended our pose estimation solutions to the Proficiency Estimation task, applying core technologies such as transformer-based architectures. This extension enabled us to achieve a top-1 accuracy of 0.53, a SOTA result, in the Demonstrator Proficiency Estimation competition.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
EGFormer: Towards Efficient and Generalizable Multimodal Semantic Segmentation
May 20, 2025Recent efforts have explored multimodal semantic segmentation using various backbone architectures. However, while most methods aim to improve accuracy, their computational efficiency remains underexplored. To address this, we propose EGFormer, an efficient multimodal semantic segmentation framework that flexibly integrates an arbitrary number of modalities while significantly reducing model parameters and inference time without sacrificing performance. Our framework introduces two novel modules. First, the Any-modal Scoring Module (ASM) assigns importance scores to each modality independently, enabling dynamic ranking based on their feature maps. Second, the Modal Dropping Module (MDM) filters out less informative modalities at each stage, selectively preserving and aggregating only the most valuable features. This design allows the model to leverage useful information from all available modalities while discarding redundancy, thus ensuring high segmentation quality. In addition to efficiency, we evaluate EGFormer on a synthetic-to-real transfer task to demonstrate its generalizability. Extensive experiments show that EGFormer achieves competitive performance with up to 88 percent reduction in parameters and 50 percent fewer GFLOPs. Under unsupervised domain adaptation settings, it further achieves state-of-the-art transfer performance compared to existing methods.
Cooperative Causal GraphSAGE
May 20, 2025GraphSAGE is a widely used graph neural network. The introduction of causal inference has improved its robust performance and named as Causal GraphSAGE. However, Causal GraphSAGE focuses on measuring causal weighting among individual nodes, but neglecting the cooperative relationships among sampling nodes as a whole. To address this issue, this paper proposes Cooperative Causal GraphSAGE (CoCa-GraphSAGE), which combines cooperative game theory with Causal GraphSAGE. Initially, a cooperative causal structure model is constructed in the case of cooperation based on the graph structure. Subsequently, Cooperative Causal sampling (CoCa-sampling) algorithm is proposed, employing the Shapley values to calculate the cooperative contribution based on causal weights of the nodes sets. CoCa-sampling guides the selection of nodes with significant cooperative causal effects during the neighborhood sampling process, thus integrating the selected neighborhood features under cooperative relationships, which takes the sampled nodes as a whole and generates more stable target node embeddings. Experiments on publicly available datasets show that the proposed method has comparable classification performance to the compared methods and outperforms under perturbations, demonstrating the robustness improvement by CoCa-sampling.
S2SBench: A Benchmark for Quantifying Intelligence Degradation in Speech-to-Speech Large Language Models
May 20, 2025



End-to-end speech large language models ((LLMs)) extend the capabilities of text-based models to directly process and generate audio tokens. However, this often leads to a decline in reasoning and generation performance compared to text input, a phenomenon referred to as intelligence degradation. To systematically evaluate this gap, we propose S2SBench, a benchmark designed to quantify performance degradation in Speech LLMs. It includes diagnostic datasets targeting sentence continuation and commonsense reasoning under audio input. We further introduce a pairwise evaluation protocol based on perplexity differences between plausible and implausible samples to measure degradation relative to text input. We apply S2SBench to analyze the training process of Baichuan-Audio, which further demonstrates the benchmark's effectiveness. All datasets and evaluation code are available at https://github.com/undobug/S2SBench.
Confidence-Regulated Generative Diffusion Models for Reliable AI Agent Migration in Vehicular Metaverses
May 19, 2025Vehicular metaverses are an emerging paradigm that merges intelligent transportation systems with virtual spaces, leveraging advanced digital twin and Artificial Intelligence (AI) technologies to seamlessly integrate vehicles, users, and digital environments. In this paradigm, vehicular AI agents are endowed with environment perception, decision-making, and action execution capabilities, enabling real-time processing and analysis of multi-modal data to provide users with customized interactive services. Since vehicular AI agents require substantial resources for real-time decision-making, given vehicle mobility and network dynamics conditions, the AI agents are deployed in RoadSide Units (RSUs) with sufficient resources and dynamically migrated among them. However, AI agent migration requires frequent data exchanges, which may expose vehicular metaverses to potential cyber attacks. To this end, we propose a reliable vehicular AI agent migration framework, achieving reliable dynamic migration and efficient resource scheduling through cooperation between vehicles and RSUs. Additionally, we design a trust evaluation model based on the theory of planned behavior to dynamically quantify the reputation of RSUs, thereby better accommodating the personalized trust preferences of users. We then model the vehicular AI agent migration process as a partially observable markov decision process and develop a Confidence-regulated Generative Diffusion Model (CGDM) to efficiently generate AI agent migration decisions. Numerical results demonstrate that the CGDM algorithm significantly outperforms baseline methods in reducing system latency and enhancing robustness against cyber attacks.
On Path to Multimodal Generalist: General-Level and General-Bench
May 07, 2025The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm. Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones. While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems. This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI. At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities. To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances. The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI. Project page: https://generalist.top/
Unaligned RGB Guided Hyperspectral Image Super-Resolution with Spatial-Spectral Concordance
May 04, 2025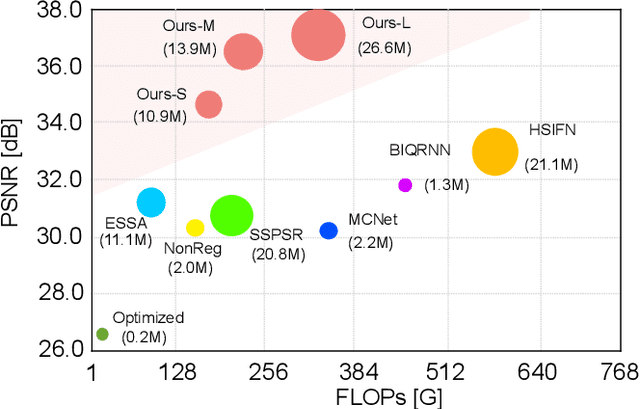
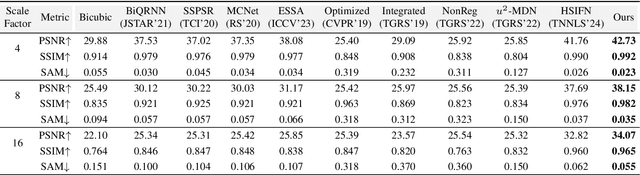
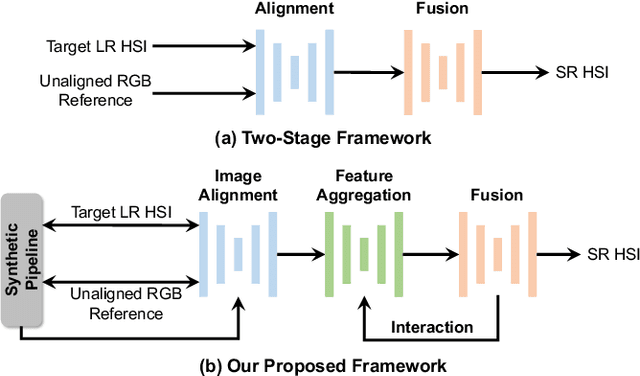
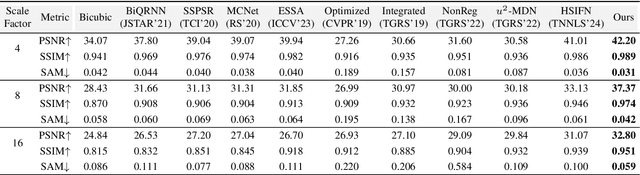
Hyperspectral images super-resolution aims to improve the spatial resolution, yet its performance is often limited at high-resolution ratios. The recent adoption of high-resolution reference images for super-resolution is driven by the poor spatial detail found in low-resolution HSIs, presenting it as a favorable method. However, these approaches cannot effectively utilize information from the reference image, due to the inaccuracy of alignment and its inadequate interaction between alignment and fusion modules. In this paper, we introduce a Spatial-Spectral Concordance Hyperspectral Super-Resolution (SSC-HSR) framework for unaligned reference RGB guided HSI SR to address the issues of inaccurate alignment and poor interactivity of the previous approaches. Specifically, to ensure spatial concordance, i.e., align images more accurately across resolutions and refine textures, we construct a Two-Stage Image Alignment with a synthetic generation pipeline in the image alignment module, where the fine-tuned optical flow model can produce a more accurate optical flow in the first stage and warp model can refine damaged textures in the second stage. To enhance the interaction between alignment and fusion modules and ensure spectral concordance during reconstruction, we propose a Feature Aggregation module and an Attention Fusion module. In the feature aggregation module, we introduce an Iterative Deformable Feature Aggregation block to achieve significant feature matching and texture aggregation with the fusion multi-scale results guidance, iteratively generating learnable offset. Besides, we introduce two basic spectral-wise attention blocks in the attention fusion module to model the inter-spectra interactions. Extensive experiments on three natural or remote-sensing datasets show that our method outperforms state-of-the-art approaches on both quantitative and qualitative evaluations.
PVUW 2025 Challenge Report: Advances in Pixel-level Understanding of Complex Videos in the Wild
Apr 15, 2025



This report provides a comprehensive overview of the 4th Pixel-level Video Understanding in the Wild (PVUW) Challenge, held in conjunction with CVPR 2025. It summarizes the challenge outcomes, participating methodologies, and future research directions. The challenge features two tracks: MOSE, which focuses on complex scene video object segmentation, and MeViS, which targets motion-guided, language-based video segmentation. Both tracks introduce new, more challenging datasets designed to better reflect real-world scenarios. Through detailed evaluation and analysis, the challenge offers valuable insights into the current state-of-the-art and emerging trends in complex video segmentation. More information can be found on the workshop website: https://pvuw.github.io/.