 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerspectives on the System-level Design of a Safe Autonomous Driving Stack
Jul 29, 2022
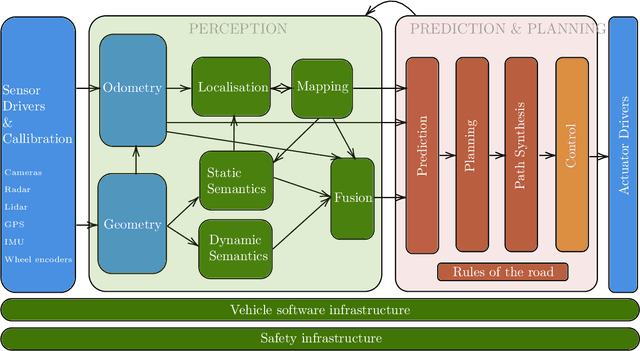
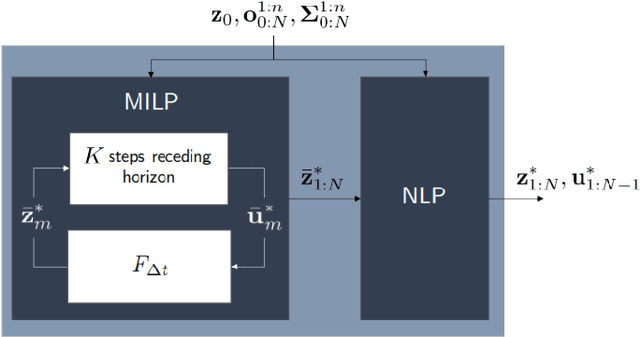
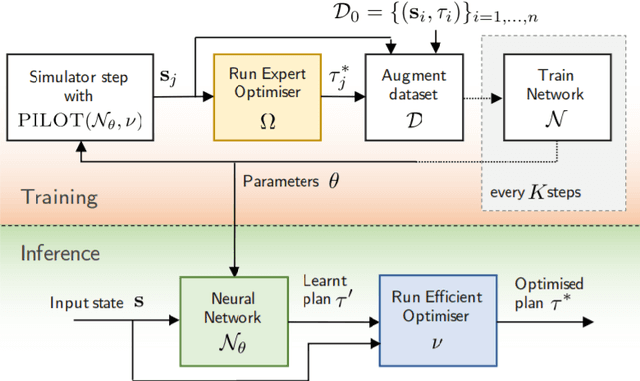
Achieving safe and robust autonomy is the key bottleneck on the path towards broader adoption of autonomous vehicles technology. This motivates going beyond extrinsic metrics such as miles between disengagement, and calls for approaches that embody safety by design. In this paper, we address some aspects of this challenge, with emphasis on issues of motion planning and prediction. We do this through description of novel approaches taken to solving selected sub-problems within an autonomous driving stack, in the process introducing the design philosophy being adopted within Five. This includes safe-by-design planning, interpretable as well as verifiable prediction, and modelling of perception errors to enable effective sim-to-real and real-to-sim transfer within the testing pipeline of a realistic autonomous system.
A Novel Design and Evaluation of a Dactylus-Equipped Quadruped Robot for Mobile Manipulation
Jul 18, 2022
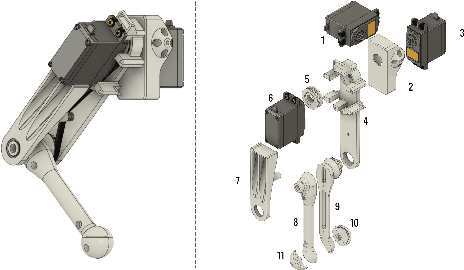
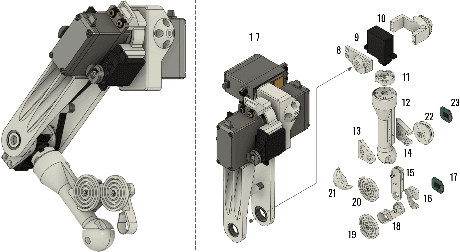
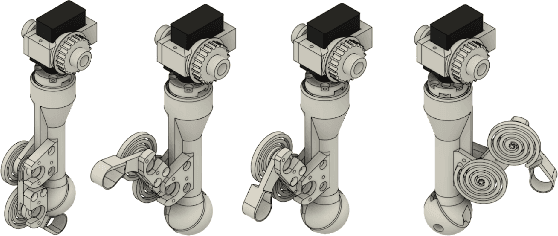
Quadruped robots are usually equipped with additional arms for manipulation, negatively impacting price and weight. On the other hand, the requirements of legged locomotion mean that the legs of such robots often possess the needed torque and precision to perform manipulation. In this paper, we present a novel design for a small-scale quadruped robot equipped with two leg-mounted manipulators inspired by crustacean chelipeds and knuckle-walker forelimbs. By making use of the actuators already present in the legs, we can achieve manipulation using only 3 additional motors per limb. The design enables the use of small and inexpensive actuators relative to the leg motors, further reducing cost and weight. The moment of inertia impact on the leg is small thanks to an integrated cable/pulley system. As we show in a suite of tele-operation experiments, the robot is capable of performing single- and dual-limb manipulation, as well as transitioning between manipulation modes. The proposed design performs similarly to an additional arm while weighing and costing 5 times less per manipulator and enabling the completion of tasks requiring 2 manipulators.
On Specifying for Trustworthiness
Jun 22, 2022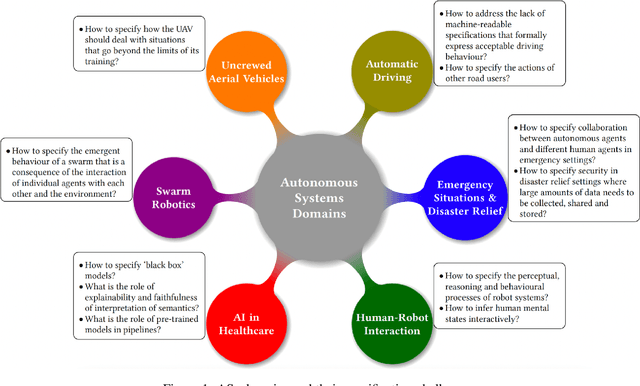
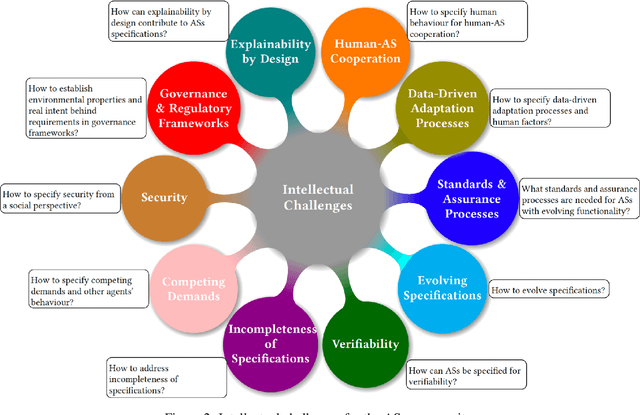
As autonomous systems are becoming part of our daily lives, ensuring their trustworthiness is crucial. There are a number of techniques for demonstrating trustworthiness. Common to all these techniques is the need to articulate specifications. In this paper, we take a broad view of specification, concentrating on top-level requirements including but not limited to functionality, safety, security and other non-functional properties. The main contribution of this article is a set of high-level intellectual challenges for the autonomous systems community related to specifying for trustworthiness. We also describe unique specification challenges concerning a number of application domains for autonomous systems.
Beyond RMSE: Do machine-learned models of road user interaction produce human-like behavior?
Jun 22, 2022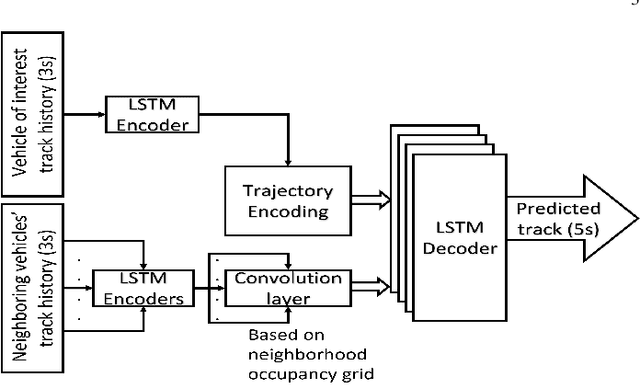
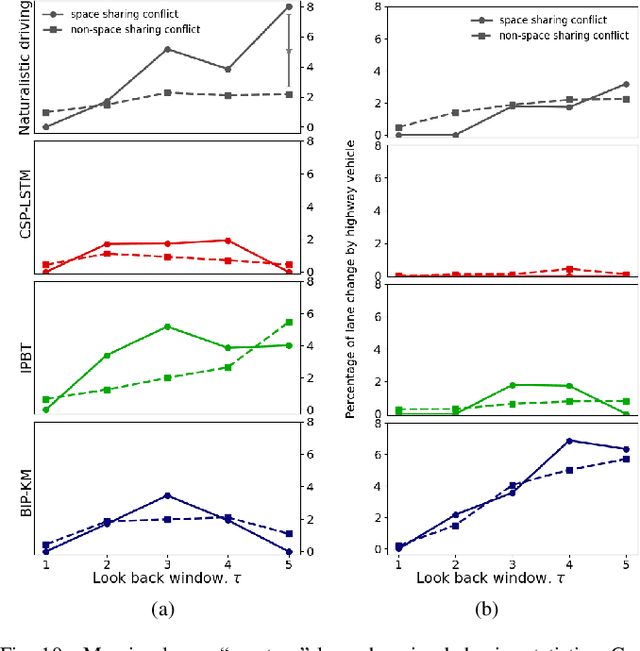
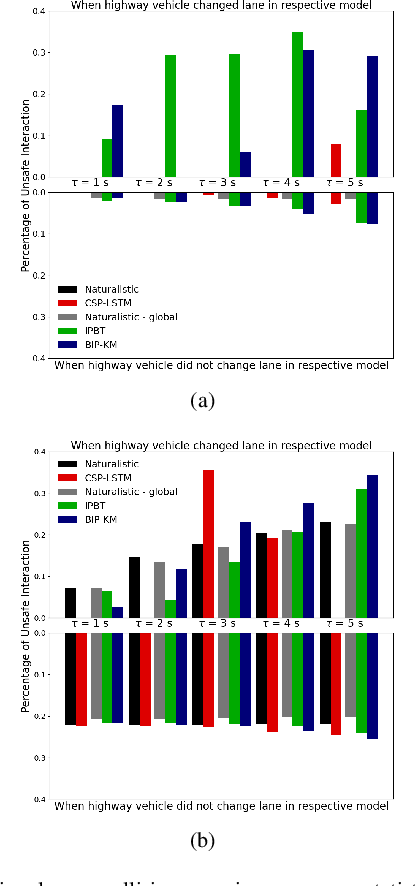
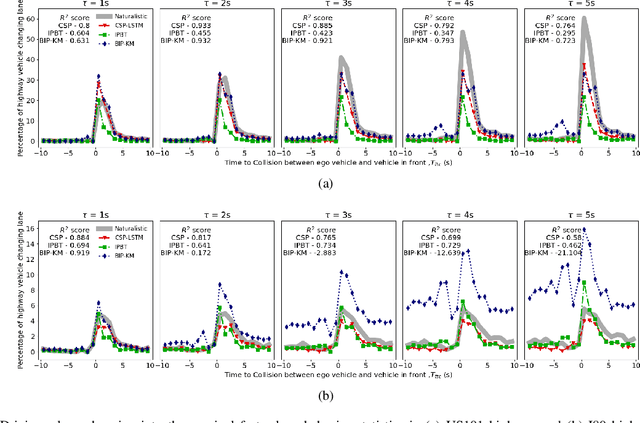
Autonomous vehicles use a variety of sensors and machine-learned models to predict the behavior of surrounding road users. Most of the machine-learned models in the literature focus on quantitative error metrics like the root mean square error (RMSE) to learn and report their models' capabilities. This focus on quantitative error metrics tends to ignore the more important behavioral aspect of the models, raising the question of whether these models really predict human-like behavior. Thus, we propose to analyze the output of machine-learned models much like we would analyze human data in conventional behavioral research. We introduce quantitative metrics to demonstrate presence of three different behavioral phenomena in a naturalistic highway driving dataset: 1) The kinematics-dependence of who passes a merging point first 2) Lane change by an on-highway vehicle to accommodate an on-ramp vehicle 3) Lane changes by vehicles on the highway to avoid lead vehicle conflicts. Then, we analyze the behavior of three machine-learned models using the same metrics. Even though the models' RMSE value differed, all the models captured the kinematic-dependent merging behavior but struggled at varying degrees to capture the more nuanced courtesy lane change and highway lane change behavior. Additionally, the collision aversion analysis during lane changes showed that the models struggled to capture the physical aspect of human driving: leaving adequate gap between the vehicles. Thus, our analysis highlighted the inadequacy of simple quantitative metrics and the need to take a broader behavioral perspective when analyzing machine-learned models of human driving predictions.
Achieving Dexterous Bidirectional Interaction in Uncertain Conditions for Medical Robotics
Jun 20, 2022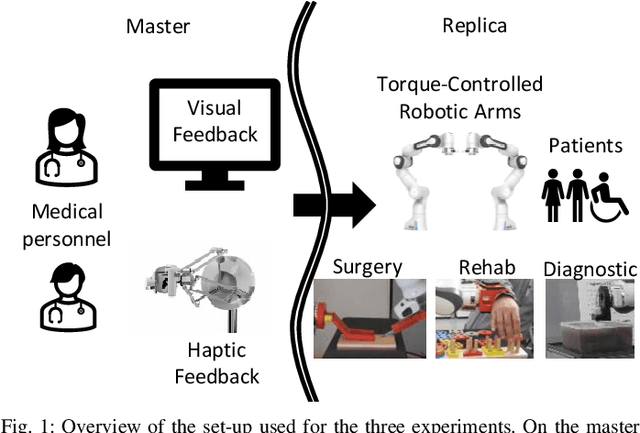
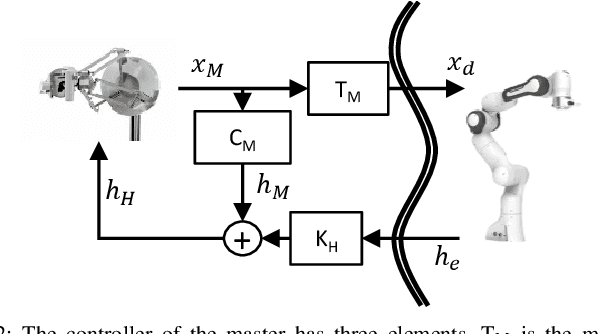
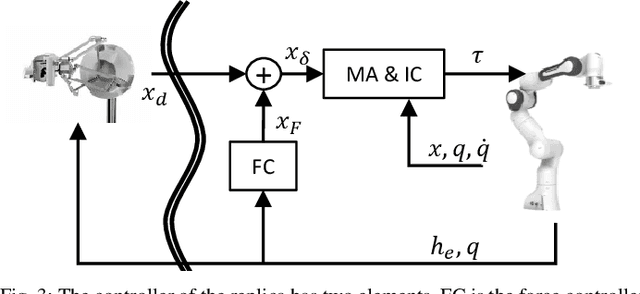

Medical robotics can help improve and extend the reach of healthcare services. A major challenge for medical robots is the complex physical interaction between the robot and the patients which is required to be safe. This work presents the preliminary evaluation of a recently introduced control architecture based on the Fractal Impedance Control (FIC) in medical applications. The deployed FIC architecture is robust to delay between the master and the replica robots. It can switch online between an admittance and impedance behaviour, and it is robust to interaction with unstructured environments. Our experiments analyse three scenarios: teleoperated surgery, rehabilitation, and remote ultrasound scan. The experiments did not require any adjustment of the robot tuning, which is essential in medical applications where the operators do not have an engineering background required to tune the controller. Our results show that is possible to teleoperate the robot to cut using a scalpel, do an ultrasound scan, and perform remote occupational therapy. However, our experiments also highlighted the need for a better robots embodiment to precisely control the system in 3D dynamic tasks.
Risk-Driven Design of Perception Systems
May 21, 2022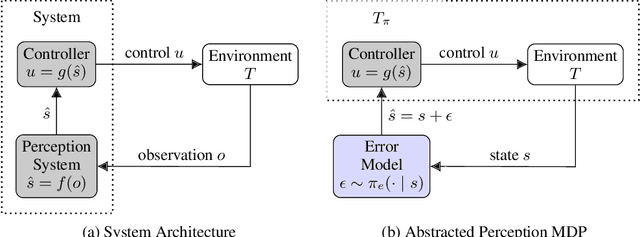

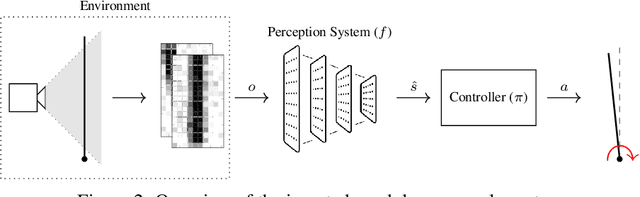

Modern autonomous systems rely on perception modules to process complex sensor measurements into state estimates. These estimates are then passed to a controller, which uses them to make safety-critical decisions. It is therefore important that we design perception systems to minimize errors that reduce the overall safety of the system. We develop a risk-driven approach to designing perception systems that accounts for the effect of perceptual errors on the performance of the fully-integrated, closed-loop system. We formulate a risk function to quantify the effect of a given perceptual error on overall safety, and show how we can use it to design safer perception systems by including a risk-dependent term in the loss function and generating training data in risk-sensitive regions. We evaluate our techniques on a realistic vision-based aircraft detect and avoid application and show that risk-driven design reduces collision risk by 37% over a baseline system.
Flash: Fast and Light Motion Prediction for Autonomous Driving with Bayesian Inverse Planning and Learned Motion Profiles
Mar 15, 2022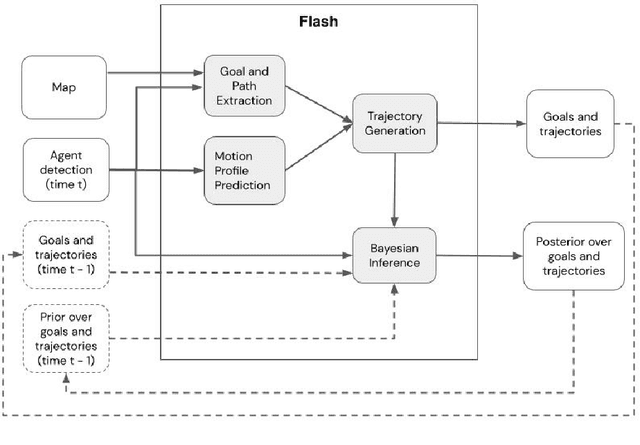
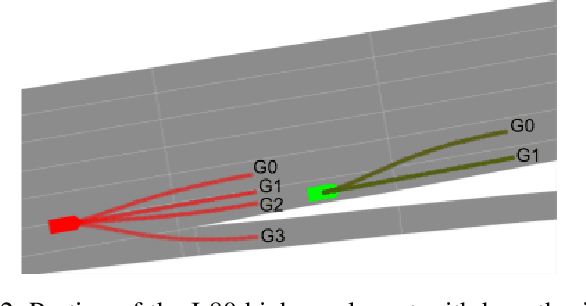
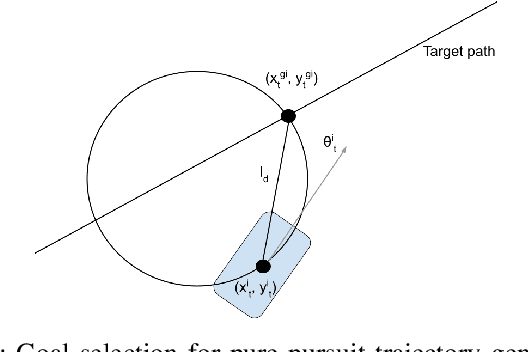
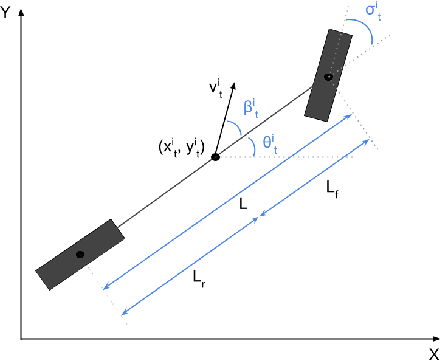
Motion prediction of road users in traffic scenes is critical for autonomous driving systems that must take safe and robust decisions in complex dynamic environments. We present a novel motion prediction system for autonomous driving. Our system is based on the Bayesian inverse planning framework, which efficiently orchestrates map-based goal extraction, a classical control-based trajectory generator and an ensemble of light-weight neural networks specialised in motion profile prediction. In contrast to many alternative methods, this modularity helps isolate performance factors and better interpret results, without compromising performance. This system addresses multiple aspects of interest, namely multi-modality, motion profile uncertainty and trajectory physical feasibility. We report on several experiments with the popular highway dataset NGSIM, demonstrating state-of-the-art performance in terms of trajectory error. We also perform a detailed analysis of our system's components, along with experiments that stratify the data based on behaviours, such as change lane versus follow lane, to provide insights into the challenges in this domain. Finally, we present a qualitative analysis to show other benefits of our approach, such as the ability to interpret the outputs.
Learning physics-informed simulation models for soft robotic manipulation: A case study with dielectric elastomer actuators
Feb 25, 2022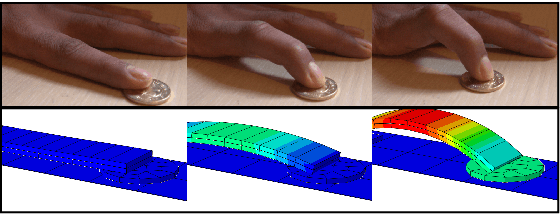
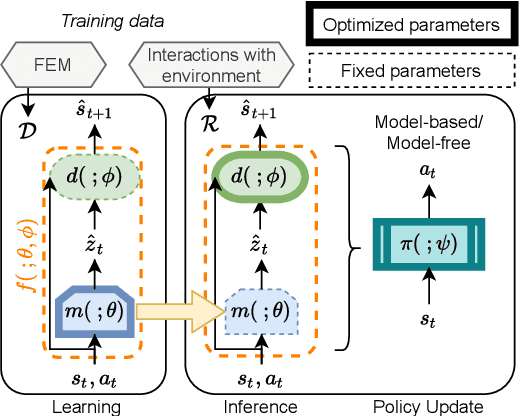
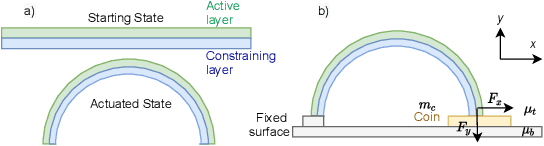
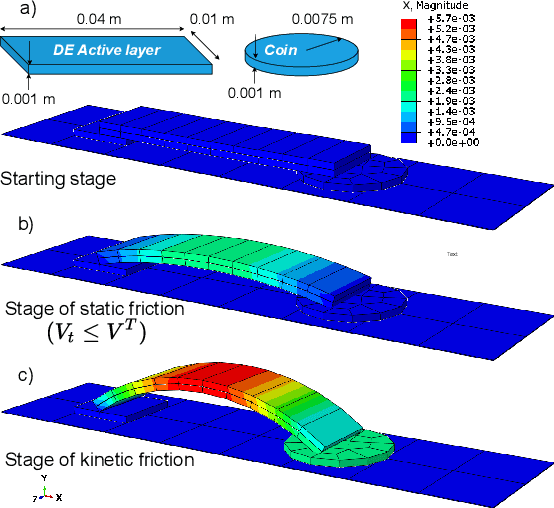
Soft actuators offer a safe and adaptable approach to robotic tasks like gentle grasping and dexterous movement. Creating accurate models to control such systems, however, is challenging due to the complex physics of deformable materials. Accurate Finite Element Method (FEM) models incur prohibitive computational complexity for closed-loop use. Using a differentiable simulator is an attractive alternative, but their applicability to soft actuators and deformable materials remains under-explored. This paper presents a framework that combines the advantages of both. We learn a differentiable model consisting of a material properties neural network and an analytical dynamics model of the remainder of the manipulation task. This physics-informed model is trained using data generated from FEM and can be used for closed-loop control and inference. We evaluate our framework on a dielectric elastomer actuator (DEA) coin-pulling task. We simulate DEA coin pulling in FEM, and design experiments to evaluate the physics-informed model for simulation, control, and inference. Our model attains < 5% simulation error compared to FEM, and we use it as the basis for an MPC controller that outperforms (i.e., requires fewer iterations to converge) a model-free actor-critic policy, a heuristic policy, and a PD controller.
Robust Learning from Observation with Model Misspecification
Feb 15, 2022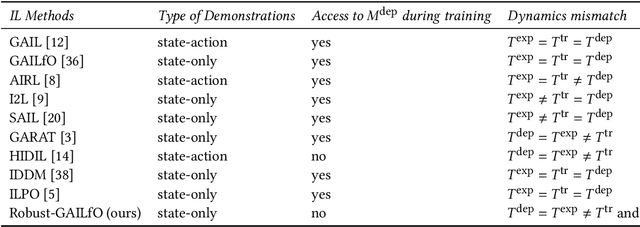
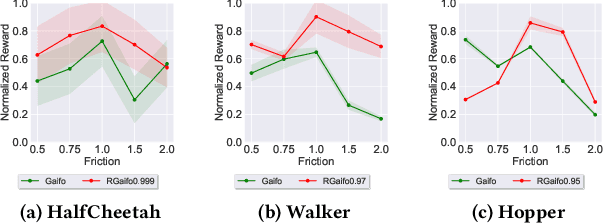
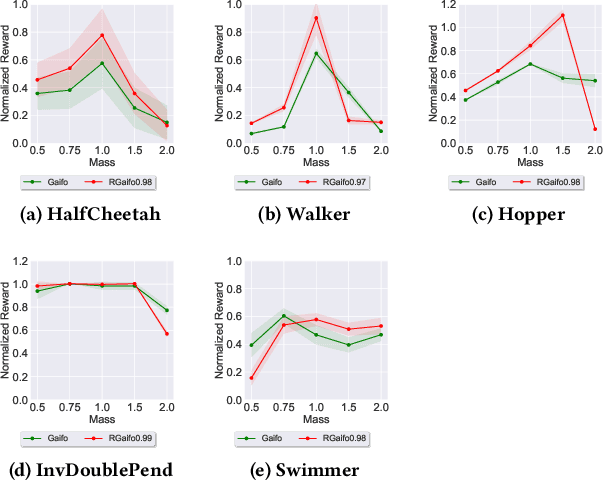
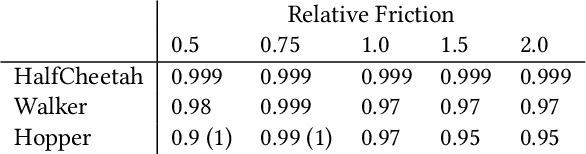
Imitation learning (IL) is a popular paradigm for training policies in robotic systems when specifying the reward function is difficult. However, despite the success of IL algorithms, they impose the somewhat unrealistic requirement that the expert demonstrations must come from the same domain in which a new imitator policy is to be learned. We consider a practical setting, where (i) state-only expert demonstrations from the real (deployment) environment are given to the learner, (ii) the imitation learner policy is trained in a simulation (training) environment whose transition dynamics is slightly different from the real environment, and (iii) the learner does not have any access to the real environment during the training phase beyond the batch of demonstrations given. Most of the current IL methods, such as generative adversarial imitation learning and its state-only variants, fail to imitate the optimal expert behavior under the above setting. By leveraging insights from the Robust reinforcement learning (RL) literature and building on recent adversarial imitation approaches, we propose a robust IL algorithm to learn policies that can effectively transfer to the real environment without fine-tuning. Furthermore, we empirically demonstrate on continuous-control benchmarks that our method outperforms the state-of-the-art state-only IL method in terms of the zero-shot transfer performance in the real environment and robust performance under different testing conditions.
Vision Checklist: Towards Testable Error Analysis of Image Models to Help System Designers Interrogate Model Capabilities
Jan 31, 2022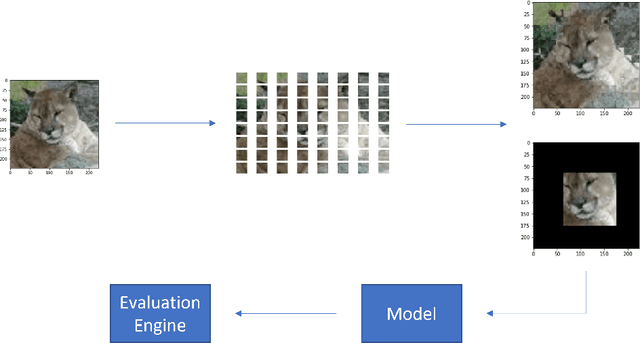



Using large pre-trained models for image recognition tasks is becoming increasingly common owing to the well acknowledged success of recent models like vision transformers and other CNN-based models like VGG and Resnet. The high accuracy of these models on benchmark tasks has translated into their practical use across many domains including safety-critical applications like autonomous driving and medical diagnostics. Despite their widespread use, image models have been shown to be fragile to changes in the operating environment, bringing their robustness into question. There is an urgent need for methods that systematically characterise and quantify the capabilities of these models to help designers understand and provide guarantees about their safety and robustness. In this paper, we propose Vision Checklist, a framework aimed at interrogating the capabilities of a model in order to produce a report that can be used by a system designer for robustness evaluations. This framework proposes a set of perturbation operations that can be applied on the underlying data to generate test samples of different types. The perturbations reflect potential changes in operating environments, and interrogate various properties ranging from the strictly quantitative to more qualitative. Our framework is evaluated on multiple datasets like Tinyimagenet, CIFAR10, CIFAR100 and Camelyon17 and for models like ViT and Resnet. Our Vision Checklist proposes a specific set of evaluations that can be integrated into the previously proposed concept of a model card. Robustness evaluations like our checklist will be crucial in future safety evaluations of visual perception modules, and be useful for a wide range of stakeholders including designers, deployers, and regulators involved in the certification of these systems. Source code of Vision Checklist would be open for public use.