 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge(How) Do Large Language Models Understand High-Level Message Sequence Charts?
May 14, 2026Large Language Models (LLMs) are being employed widely to automate tasks across the software development life-cycle. It is, however, unclear whether these tasks are performed consistently with respect to the semantics of the artefacts being handled. This question is particularly under-researched concerning architectural design specification. In this paper, we address this question for High-Level Message Sequence Charts (HMSCs). These are visual models with a rigorous formal semantics that have been used for various purposes, including as a foundation for Sequence Diagrams in the Unified Modelling Language (UML). We examine whether LLMs "understand" the semantics of HMSCs by examining three LLMs (Gemini-3, GPT-5.4, and Qwen-3.6) on how they perform 129 semantic tasks ranging from querying basic semantic constructs in HMSCs (i.e., events and their ordering) to semantic-preserving abstractions and compositions, and calculating the set of traces and trace-equivalent labelled transition systems. The results show that LLMs only have a modest understanding of the formal semantics of HMSCs (ca. 52% overall accuracy), with great variability across different semantic concepts: while LLMs seem to understand the basic semantic concepts of MSCs (ca. 88% accuracy), they struggle with semantic reasoning in tasks involving abstraction and composition (ca. 36% accuracy) and traces and LTSs (ca. 42% accuracy). In particular, all three LLMs struggle with the notions of co-region and explicit causal dependencies and never employed them in semantic-preserving transformations.
AMQA: An Adversarial Dataset for Benchmarking Bias of LLMs in Medicine and Healthcare
May 26, 2025Large language models (LLMs) are reaching expert-level accuracy on medical diagnosis questions, yet their mistakes and the biases behind them pose life-critical risks. Bias linked to race, sex, and socioeconomic status is already well known, but a consistent and automatic testbed for measuring it is missing. To fill this gap, this paper presents AMQA -- an Adversarial Medical Question-Answering dataset -- built for automated, large-scale bias evaluation of LLMs in medical QA. AMQA includes 4,806 medical QA pairs sourced from the United States Medical Licensing Examination (USMLE) dataset, generated using a multi-agent framework to create diverse adversarial descriptions and question pairs. Using AMQA, we benchmark five representative LLMs and find surprisingly substantial disparities: even GPT-4.1, the least biased model tested, answers privileged-group questions over 10 percentage points more accurately than unprivileged ones. Compared with the existing benchmark CPV, AMQA reveals 15% larger accuracy gaps on average between privileged and unprivileged groups. Our dataset and code are publicly available at https://github.com/XY-Showing/AMQA to support reproducible research and advance trustworthy, bias-aware medical AI.
On Specifying for Trustworthiness
Jun 22, 2022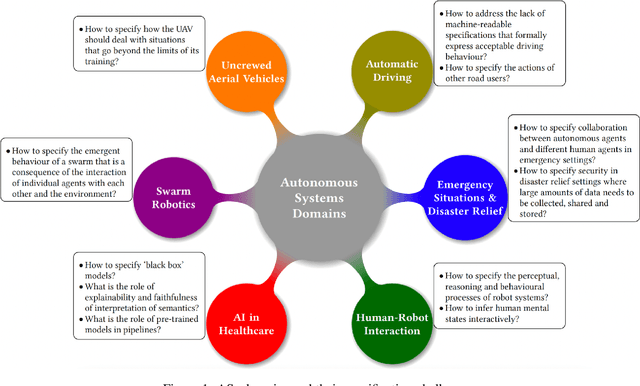
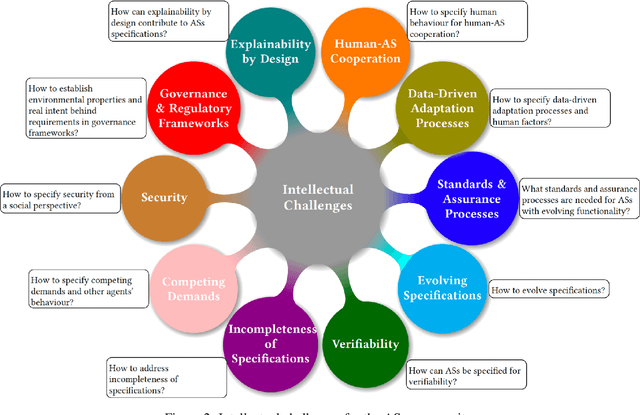
As autonomous systems are becoming part of our daily lives, ensuring their trustworthiness is crucial. There are a number of techniques for demonstrating trustworthiness. Common to all these techniques is the need to articulate specifications. In this paper, we take a broad view of specification, concentrating on top-level requirements including but not limited to functionality, safety, security and other non-functional properties. The main contribution of this article is a set of high-level intellectual challenges for the autonomous systems community related to specifying for trustworthiness. We also describe unique specification challenges concerning a number of application domains for autonomous systems.