 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Devil is in Classification: A Simple Framework for Long-tail Instance Segmentation
Jul 31, 2020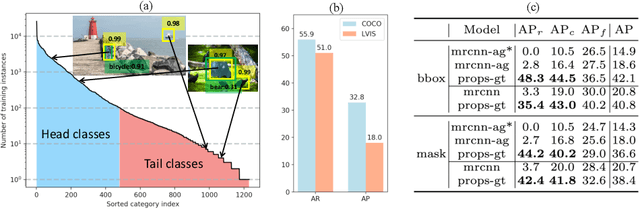

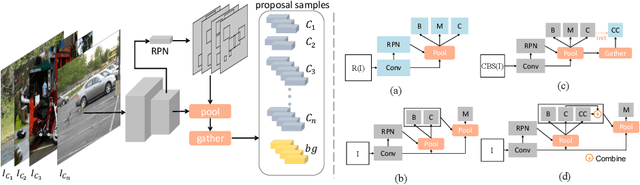
Most existing object instance detection and segmentation models only work well on fairly balanced benchmarks where per-category training sample numbers are comparable, such as COCO. They tend to suffer performance drop on realistic datasets that are usually long-tailed. This work aims to study and address such open challenges. Specifically, we systematically investigate performance drop of the state-of-the-art two-stage instance segmentation model Mask R-CNN on the recent long-tail LVIS dataset, and unveil that a major cause is the inaccurate classification of object proposals. Based on such an observation, we first consider various techniques for improving long-tail classification performance which indeed enhance instance segmentation results. We then propose a simple calibration framework to more effectively alleviate classification head bias with a bi-level class balanced sampling approach. Without bells and whistles, it significantly boosts the performance of instance segmentation for tail classes on the recent LVIS dataset and our sampled COCO-LT dataset. Our analysis provides useful insights for solving long-tail instance detection and segmentation problems, and the straightforward \emph{SimCal} method can serve as a simple but strong baseline. With the method we have won the 2019 LVIS challenge. Codes and models are available at \url{https://github.com/twangnh/SimCal}.
Extreme Low-Light Imaging with Multi-granulation Cooperative Networks
May 16, 2020
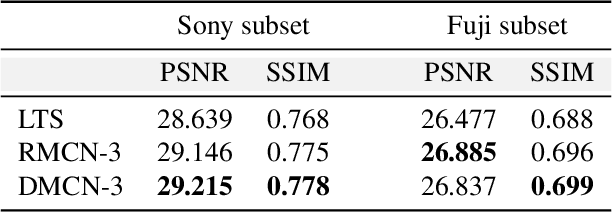
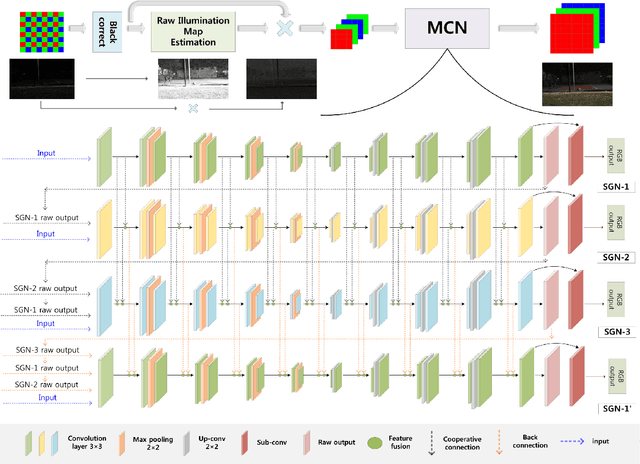

Low-light imaging is challenging since images may appear to be dark and noised due to low signal-to-noise ratio, complex image content, and the variety in shooting scenes in extreme low-light condition. Many methods have been proposed to enhance the imaging quality under extreme low-light conditions, but it remains difficult to obtain satisfactory results, especially when they attempt to retain high dynamic range (HDR). In this paper, we propose a novel method of multi-granulation cooperative networks (MCN) with bidirectional information flow to enhance extreme low-light images, and design an illumination map estimation function (IMEF) to preserve high dynamic range (HDR). To facilitate this research, we also contribute to create a new benchmark dataset of real-world Dark High Dynamic Range (DHDR) images to evaluate the performance of high dynamic preservation in low light environment. Experimental results show that the proposed method outperforms the state-of-the-art approaches in terms of both visual effects and quantitative analysis.
ToD-BERT: Pre-trained Natural Language Understanding for Task-Oriented Dialogues
Apr 29, 2020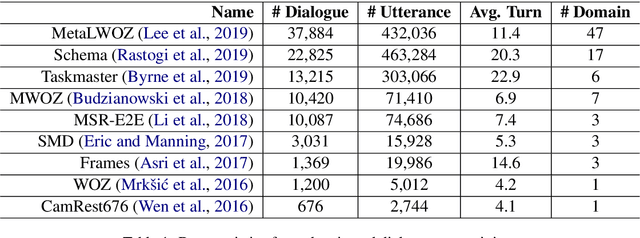
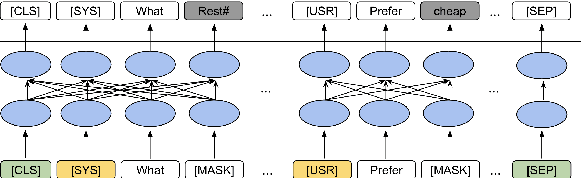
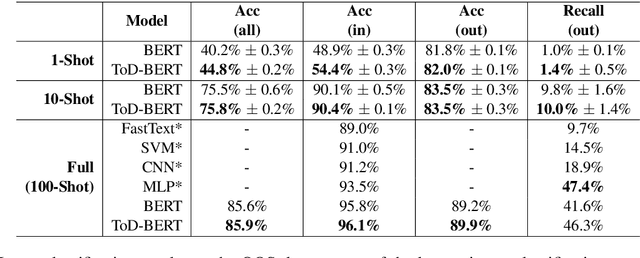
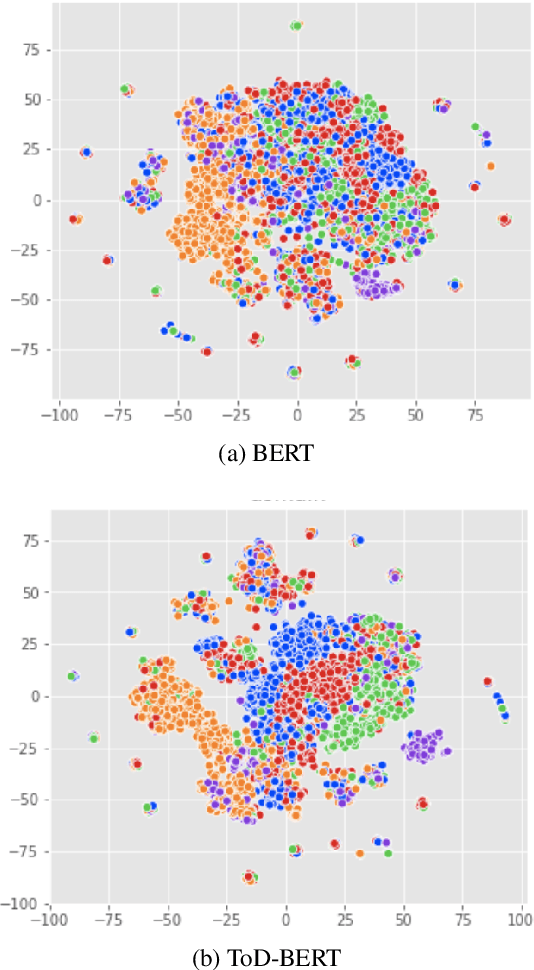
The use of pre-trained language models has emerged as a promising direction for improving dialogue systems. However, the underlying difference of linguistic patterns between conversational data and general text makes the existing pre-trained language models not as effective as they have been shown to be. Recently, there are some pre-training approaches based on open-domain dialogues, leveraging large-scale social media data such as Twitter or Reddit. Pre-training for task-oriented dialogues, on the other hand, is rarely discussed because of the long-standing and crucial data scarcity problem. In this work, we combine nine English-based, human-human, multi-turn and publicly available task-oriented dialogue datasets to conduct language model pre-training. The experimental results show that our pre-trained task-oriented dialogue BERT (ToD-BERT) surpasses BERT and other strong baselines in four downstream task-oriented dialogue applications, including intention detection, dialogue state tracking, dialogue act prediction, and response selection. Moreover, in the simulated limited data experiments, we show that ToD-BERT has stronger few-shot capacity that can mitigate the data scarcity problem in task-oriented dialogues.
Towards Noise-resistant Object Detection with Noisy Annotations
Mar 03, 2020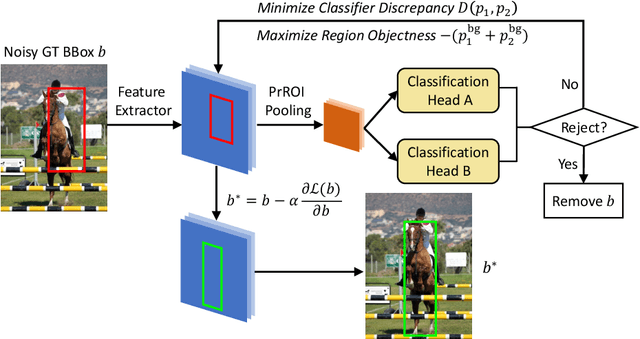
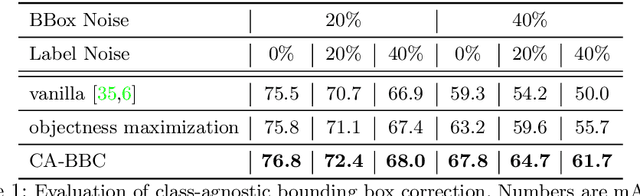
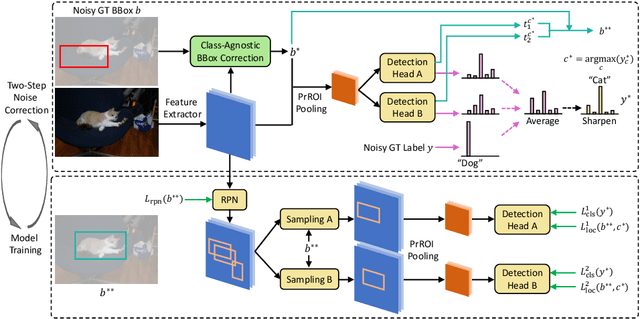
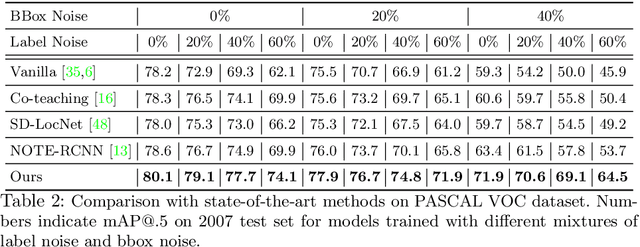
Training deep object detectors requires significant amount of human-annotated images with accurate object labels and bounding box coordinates, which are extremely expensive to acquire. Noisy annotations are much more easily accessible, but they could be detrimental for learning. We address the challenging problem of training object detectors with noisy annotations, where the noise contains a mixture of label noise and bounding box noise. We propose a learning framework which jointly optimizes object labels, bounding box coordinates, and model parameters by performing alternating noise correction and model training. To disentangle label noise and bounding box noise, we propose a two-step noise correction method. The first step performs class-agnostic bounding box correction by minimizing classifier discrepancy and maximizing region objectness. The second step distils knowledge from dual detection heads for soft label correction and class-specific bounding box refinement. We conduct experiments on PASCAL VOC and MS-COCO dataset with both synthetic noise and machine-generated noise. Our method achieves state-of-the-art performance by effectively cleaning both label noise and bounding box noise. Code to reproduce all results will be released.
Classification Calibration for Long-tail Instance Segmentation
Nov 02, 2019

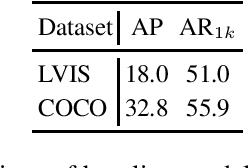

Remarkable progress has been made in object instance detection and segmentation in recent years. However, existing state-of-the-art methods are mostly evaluated with fairly balanced and class-limited benchmarks, such as Microsoft COCO dataset [8]. In this report, we investigate the performance drop phenomenon of state-of-the-art two-stage instance segmentation models when processing extreme long-tail training data based on the LVIS [5] dataset, and find a major cause is the inaccurate classification of object proposals. Based on this observation, we propose to calibrate the prediction of classification head to improve recognition performance for the tail classes. Without much additional cost and modification of the detection model architecture, our calibration method improves the performance of the baseline by a large margin on the tail classes. Codes will be available. Importantly, after the submission, we find significant improvement can be further achieved by modifying the calibration head, which we will update later.
DART: Domain-Adversarial Residual-Transfer Networks for Unsupervised Cross-Domain Image Classification
Dec 30, 2018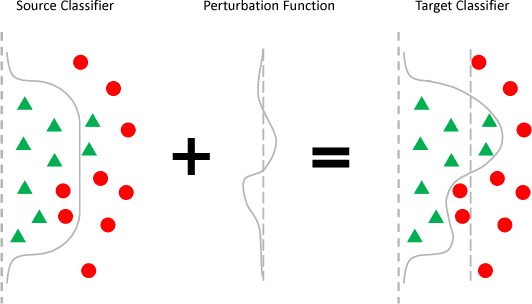

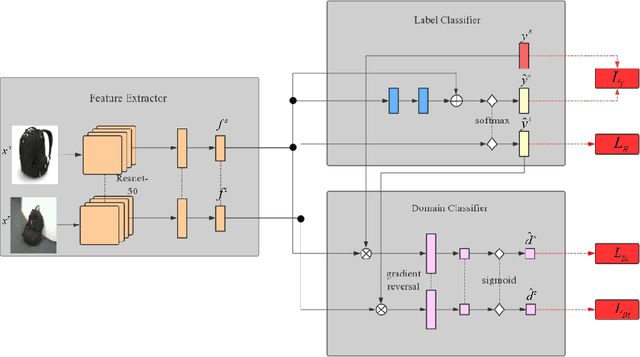
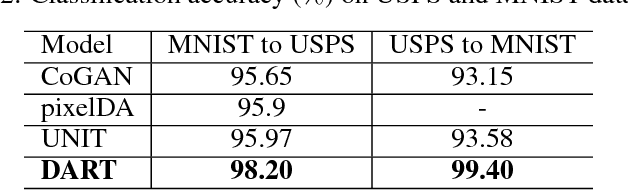
The accuracy of deep learning (e.g., convolutional neural networks) for an image classification task critically relies on the amount of labeled training data. Aiming to solve an image classification task on a new domain that lacks labeled data but gains access to cheaply available unlabeled data, unsupervised domain adaptation is a promising technique to boost the performance without incurring extra labeling cost, by assuming images from different domains share some invariant characteristics. In this paper, we propose a new unsupervised domain adaptation method named Domain-Adversarial Residual-Transfer (DART) learning of Deep Neural Networks to tackle cross-domain image classification tasks. In contrast to the existing unsupervised domain adaption approaches, the proposed DART not only learns domain-invariant features via adversarial training, but also achieves robust domain-adaptive classification via a residual-transfer strategy, all in an end-to-end training framework. We evaluate the performance of the proposed method for cross-domain image classification tasks on several well-known benchmark data sets, in which our method clearly outperforms the state-of-the-art approaches.
Dynamic Fusion with Intra- and Inter- Modality Attention Flow for Visual Question Answering
Dec 13, 2018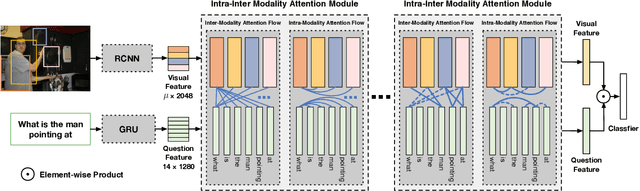

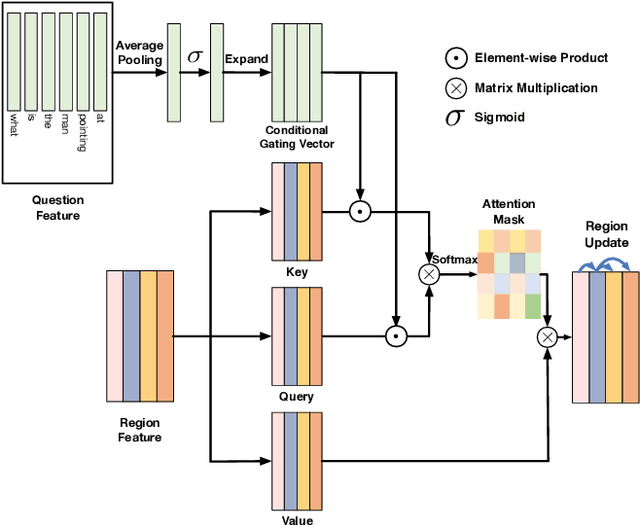
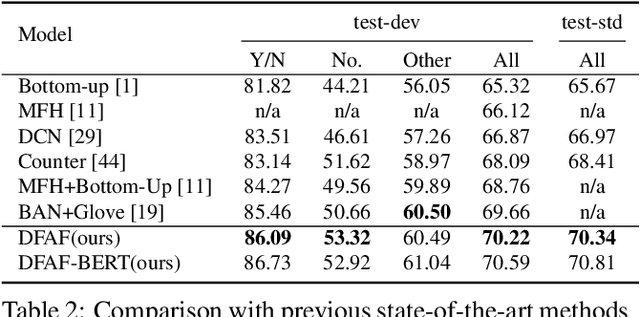
Learning effective fusion of multi-modality features is at the heart of visual question answering. We propose a novel method of dynamically fusing multi-modal features with intra- and inter-modality information flow, which alternatively pass dynamic information between and across the visual and language modalities. It can robustly capture the high-level interactions between language and vision domains, thus significantly improves the performance of visual question answering. We also show that the proposed dynamic intra-modality attention flow conditioned on the other modality can dynamically modulate the intra-modality attention of the target modality, which is vital for multimodality feature fusion. Experimental evaluations on the VQA 2.0 dataset show that the proposed method achieves state-of-the-art VQA performance. Extensive ablation studies are carried out for the comprehensive analysis of the proposed method.
Question-Guided Hybrid Convolution for Visual Question Answering
Aug 08, 2018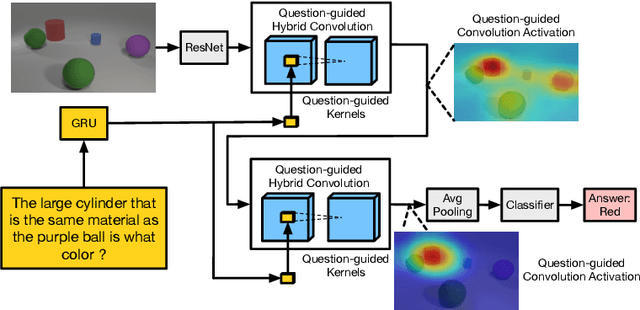
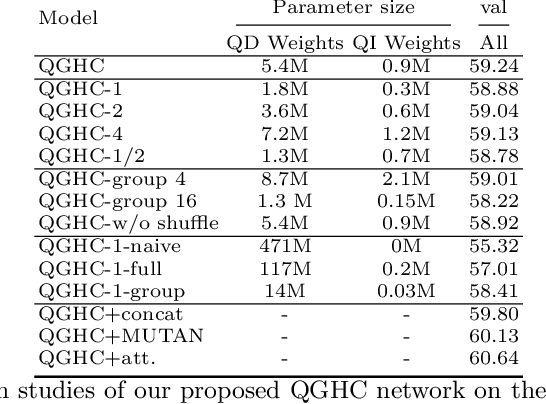
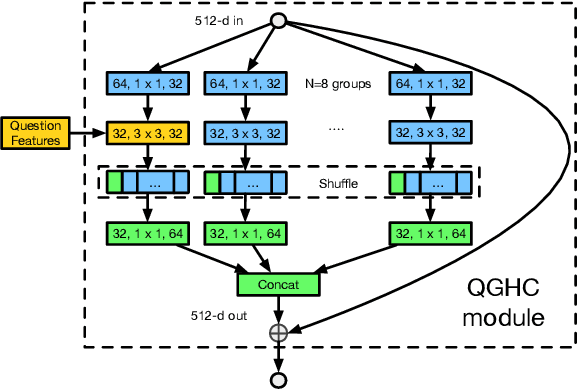
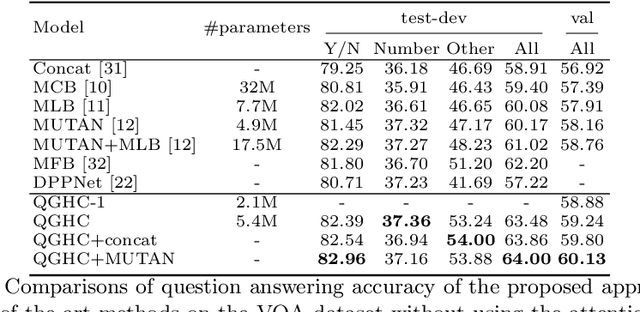
In this paper, we propose a novel Question-Guided Hybrid Convolution (QGHC) network for Visual Question Answering (VQA). Most state-of-the-art VQA methods fuse the high-level textual and visual features from the neural network and abandon the visual spatial information when learning multi-modal features.To address these problems, question-guided kernels generated from the input question are designed to convolute with visual features for capturing the textual and visual relationship in the early stage. The question-guided convolution can tightly couple the textual and visual information but also introduce more parameters when learning kernels. We apply the group convolution, which consists of question-independent kernels and question-dependent kernels, to reduce the parameter size and alleviate over-fitting. The hybrid convolution can generate discriminative multi-modal features with fewer parameters. The proposed approach is also complementary to existing bilinear pooling fusion and attention based VQA methods. By integrating with them, our method could further boost the performance. Extensive experiments on public VQA datasets validate the effectiveness of QGHC.
An Incremental Path-Following Splitting Method for Linearly Constrained Nonconvex Nonsmooth Programs
Aug 04, 2018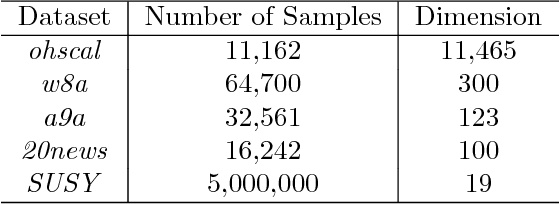
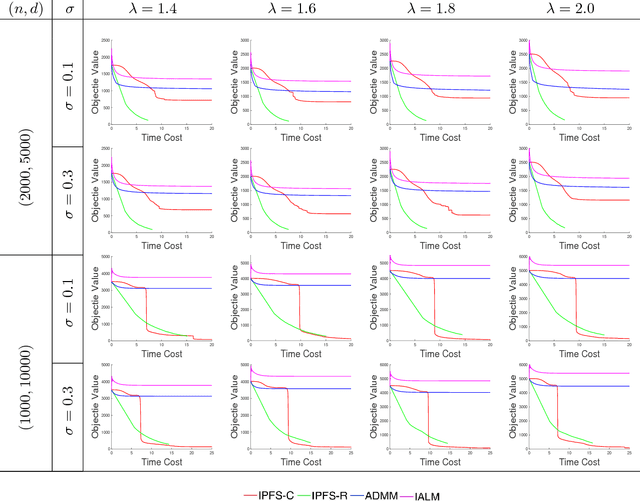
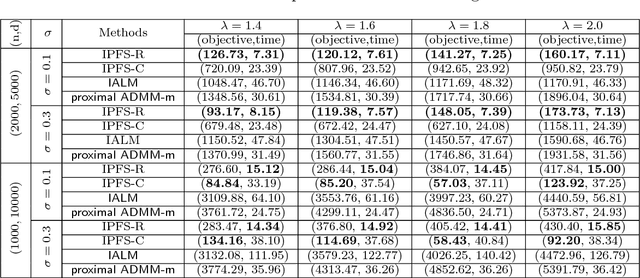
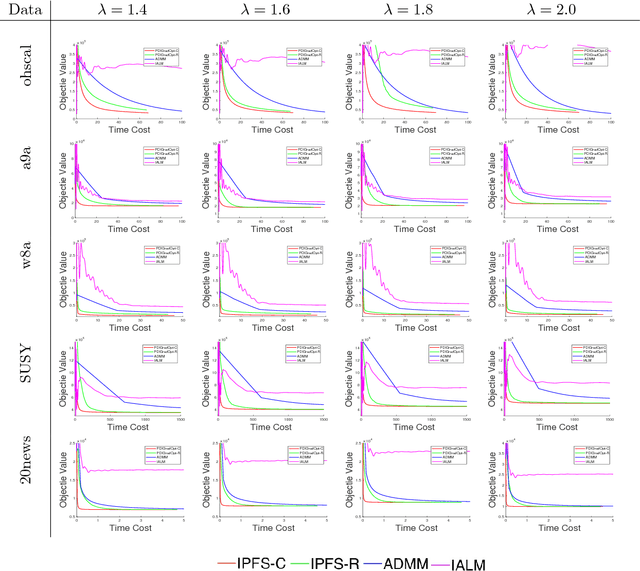
The stationary point of Problem 2 is NOT the stationary point of Problem 1. We are sorry and we are working on fixing this error.
Active Learning with Expert Advice
Sep 26, 2013
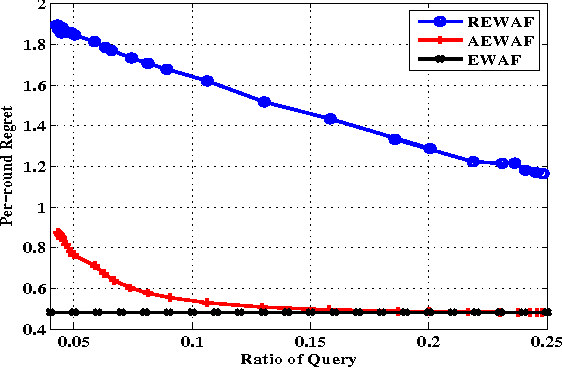
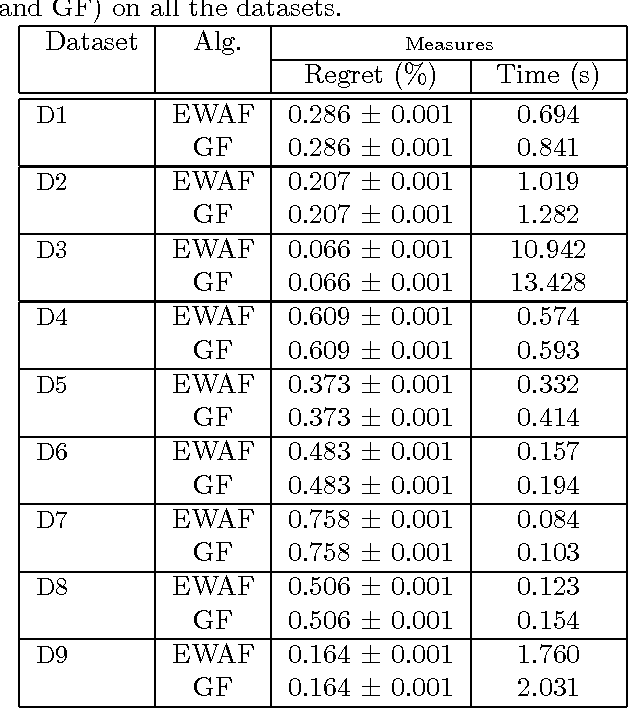
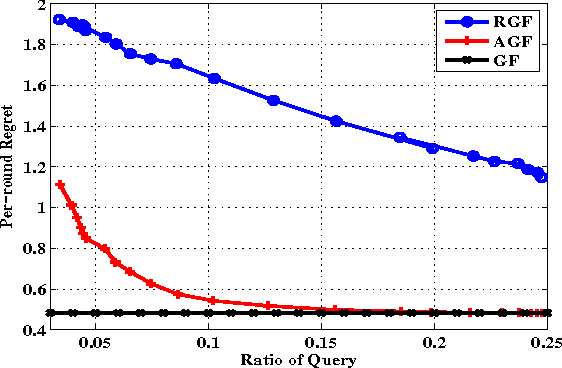
Conventional learning with expert advice methods assumes a learner is always receiving the outcome (e.g., class labels) of every incoming training instance at the end of each trial. In real applications, acquiring the outcome from oracle can be costly or time consuming. In this paper, we address a new problem of active learning with expert advice, where the outcome of an instance is disclosed only when it is requested by the online learner. Our goal is to learn an accurate prediction model by asking the oracle the number of questions as small as possible. To address this challenge, we propose a framework of active forecasters for online active learning with expert advice, which attempts to extend two regular forecasters, i.e., Exponentially Weighted Average Forecaster and Greedy Forecaster, to tackle the task of active learning with expert advice. We prove that the proposed algorithms satisfy the Hannan consistency under some proper assumptions, and validate the efficacy of our technique by an extensive set of experiments.