 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToD-BERT: Pre-trained Natural Language Understanding for Task-Oriented Dialogues
Paper and Code
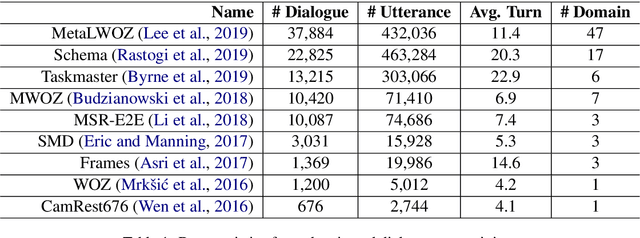
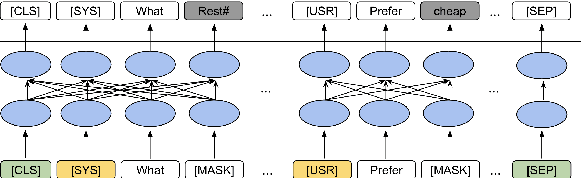
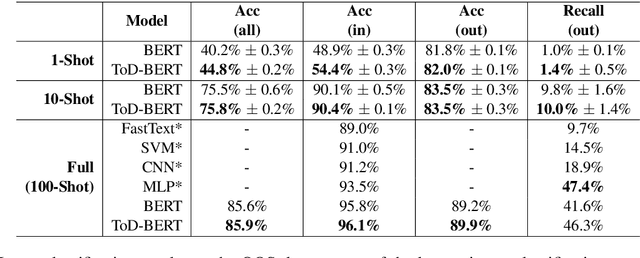
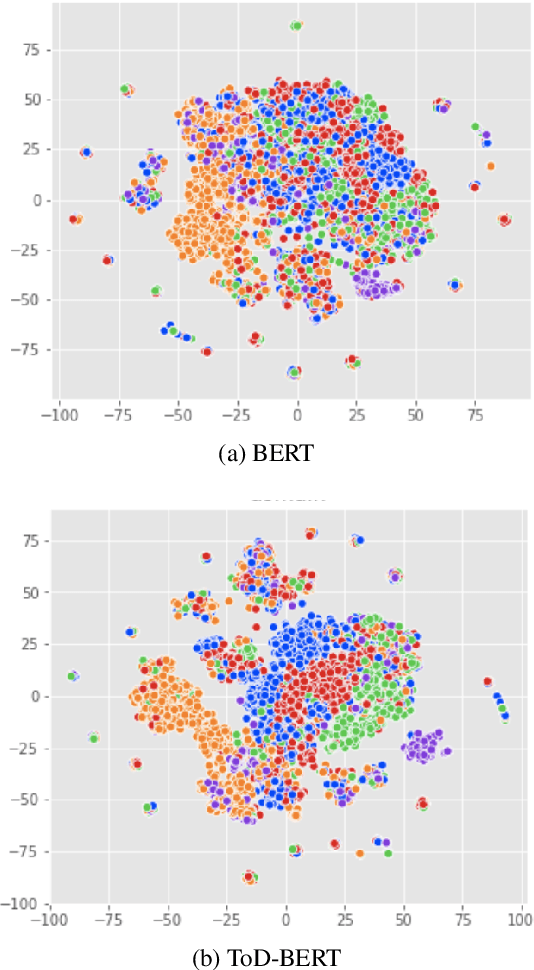
The use of pre-trained language models has emerged as a promising direction for improving dialogue systems. However, the underlying difference of linguistic patterns between conversational data and general text makes the existing pre-trained language models not as effective as they have been shown to be. Recently, there are some pre-training approaches based on open-domain dialogues, leveraging large-scale social media data such as Twitter or Reddit. Pre-training for task-oriented dialogues, on the other hand, is rarely discussed because of the long-standing and crucial data scarcity problem. In this work, we combine nine English-based, human-human, multi-turn and publicly available task-oriented dialogue datasets to conduct language model pre-training. The experimental results show that our pre-trained task-oriented dialogue BERT (ToD-BERT) surpasses BERT and other strong baselines in four downstream task-oriented dialogue applications, including intention detection, dialogue state tracking, dialogue act prediction, and response selection. Moreover, in the simulated limited data experiments, we show that ToD-BERT has stronger few-shot capacity that can mitigate the data scarcity problem in task-oriented dialogues.